349 - Understanding FAISS for efficient similarity search of dense vectors скачать в хорошем качестве
349 - Understanding FAISS for efficient similarity search of dense vectors
1 год назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: 349 - Understanding FAISS for efficient similarity search of dense vectors в качестве 4k
У нас вы можете посмотреть бесплатно 349 - Understanding FAISS for efficient similarity search of dense vectors или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон 349 - Understanding FAISS for efficient similarity search of dense vectors в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
349 - Understanding FAISS for efficient similarity search of dense vectors
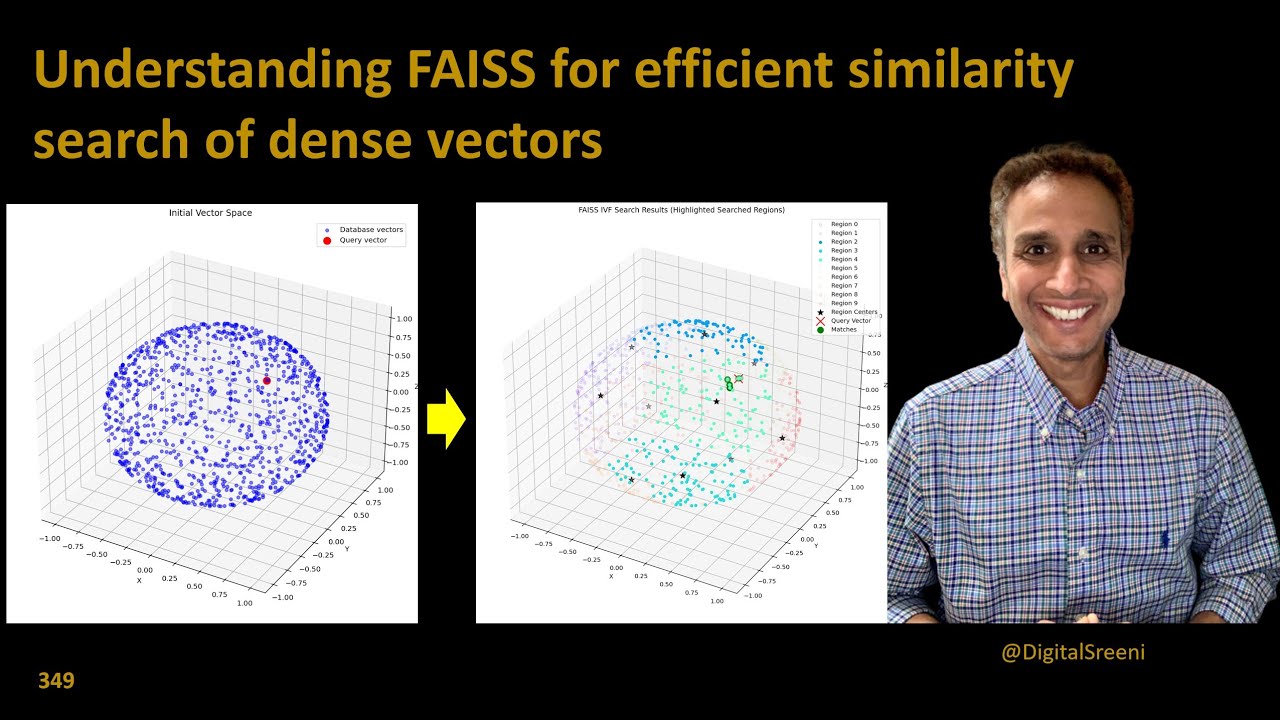
What is FAISS? Faiss is a library for efficient similarity search and clustering of dense vectors. Optimized for searching through millions or billions of high-dimensional vectors quickly Faiss contains several methods for similarity search. Two main approaches (that we will be focusing on): IndexFlatL2: Exact L2 matching but faster than manual implementation IndexIVF (Inverted file): Clusters similar features together, only searches relevant clusters IndexFlatL2 is similar to our cosine distance matching from the previous tutorial. You may not notice any speed difference both, especially for smaller datasets. For large datasets, IndexFlatL2 will still be slow since it does exhaustive search. That's where IndexIVF becomes valuable (by reducing the number of comparisons needed through clustering.) References: https://arxiv.org/abs/1702.08734 https://arxiv.org/abs/2401.08281 Python code available here: https://github.com/bnsreenu/python_fo...
Comments