Speed of Light Inference w/ NVIDIA + AMD GPUs and Modular by Abdul Dakkak, Head of Gen AI @ Modular скачать в хорошем качестве
Speed of Light Inference w/ NVIDIA + AMD GPUs and Modular by Abdul Dakkak, Head of Gen AI @ Modular
2 месяца назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Speed of Light Inference w/ NVIDIA + AMD GPUs and Modular by Abdul Dakkak, Head of Gen AI @ Modular в качестве 4k
У нас вы можете посмотреть бесплатно Speed of Light Inference w/ NVIDIA + AMD GPUs and Modular by Abdul Dakkak, Head of Gen AI @ Modular или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Speed of Light Inference w/ NVIDIA + AMD GPUs and Modular by Abdul Dakkak, Head of Gen AI @ Modular в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Speed of Light Inference w/ NVIDIA + AMD GPUs and Modular by Abdul Dakkak, Head of Gen AI @ Modular
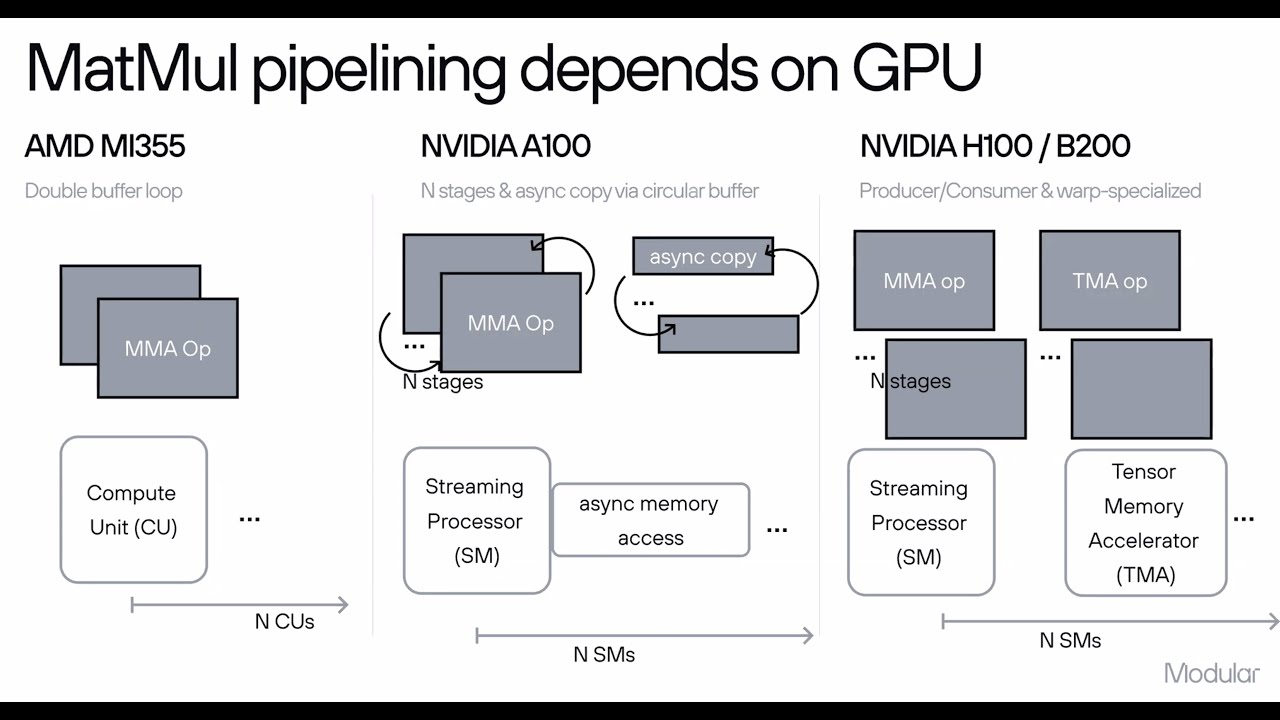
Zoom link: https://us02web.zoom.us/j/82308186562 Talk #0: Introductions and Meetup Updates by Chris Fregly and Antje Barth Talk: Speed of Light Inference w/ NVIDIA and AMD GPUs using the Modular Platform by Abdul Dakkak @ Modular This technical presentation will demonstrate how the Modular platform can be used to scale AI workloads across various clusters. It will delve into the collaborative functionality of the Modular stack, encompassing Modular Cloud (a cluster-level solution), MAX (the framework and runtime), and Mojo (the programming language). Together, these components deliver exceptional performance and significantly reduce Total Cost of Ownership (TCO) across both NVIDIA and AMD GPU architectures. Zoom link: https://us02web.zoom.us/j/82308186562 Related Links Github Repo: http://github.com/cfregly/ai-performa... O'Reilly Book: https://www.amazon.com/Systems-Perfor... YouTube: / @aiperformanceengineering Generative AI Free Course on DeepLearning.ai: https://bit.ly/gllm
Comments



















