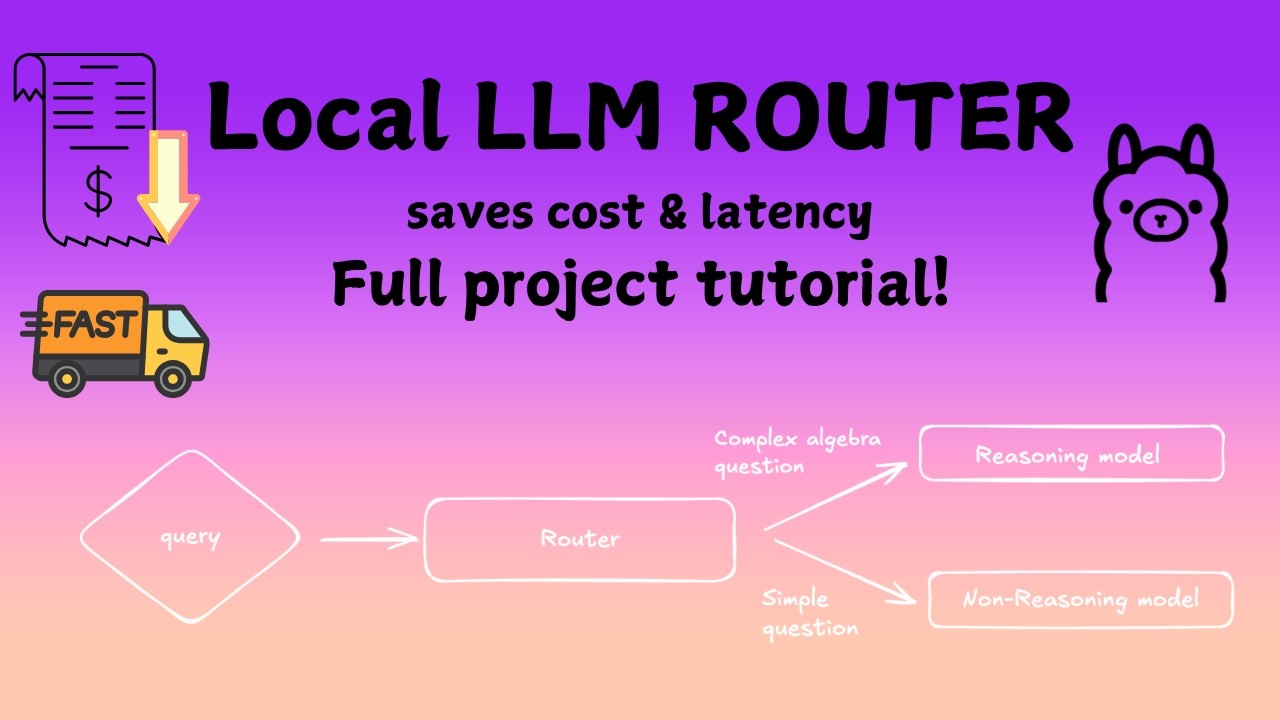
Build a Smart LLM Router That Saves Cost (Full Project Tutorial) скачать в хорошем качестве
Build a Smart LLM Router That Saves Cost (Full Project Tutorial)
2 часа назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Build a Smart LLM Router That Saves Cost (Full Project Tutorial) в качестве 4k
У нас вы можете посмотреть бесплатно Build a Smart LLM Router That Saves Cost (Full Project Tutorial) или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Build a Smart LLM Router That Saves Cost (Full Project Tutorial) в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Build a Smart LLM Router That Saves Cost (Full Project Tutorial)
Most AI apps send **every query to the largest LLM**, which makes systems **slow and expensive**. In this video, we build a *Smart LLM Router* that automatically decides whether a query should be handled by a **small model or a reasoning model**. Instead of wasting compute, the router analyzes the *complexity of the user query* and routes it to the right model. Even better — the entire system runs **locally using Ollama**, so you can build and experiment without relying on external APIs. By the end of this tutorial you will understand: • How to classify query complexity using embeddings • How to build an LLM router using a Gradient Boosting model • How to route queries between small and reasoning models • How to measure latency and simulated cost savings • How to run multi-model AI systems locally with Ollama We also build a *Streamlit dashboard* to visualize routing decisions, latency, and cost in real time. This project demonstrates a key concept used in modern AI systems: **adaptive model routing**. Topics covered: LLM routing, query complexity classification, Ollama local LLMs, AI cost optimization, multi-model systems, Gradient Boosting classifiers, embeddings with MiniLM, and building AI tools with Streamlit. If you're interested in **AI system design, LLM infrastructure, and building practical GenAI projects**, this tutorial will walk you through the entire pipeline step-by-step. Subscribe for more videos on **LLM systems, AI engineering, and practical machine learning projects**.
Comments