DeiT Explained in 3 Minutes! | Data Efficient Transformers скачать в хорошем качестве
DeiT Explained in 3 Minutes! | Data Efficient Transformers
3 дня назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: DeiT Explained in 3 Minutes! | Data Efficient Transformers в качестве 4k
У нас вы можете посмотреть бесплатно DeiT Explained in 3 Minutes! | Data Efficient Transformers или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон DeiT Explained in 3 Minutes! | Data Efficient Transformers в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
DeiT Explained in 3 Minutes! | Data Efficient Transformers
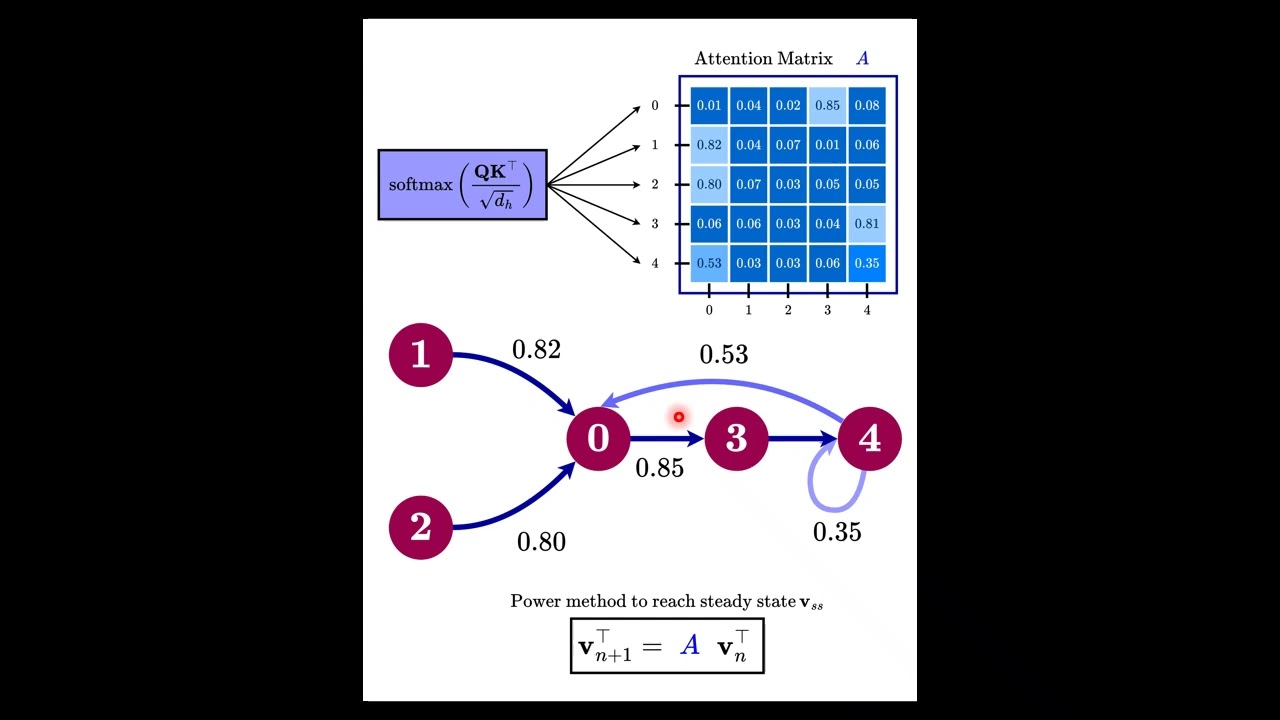
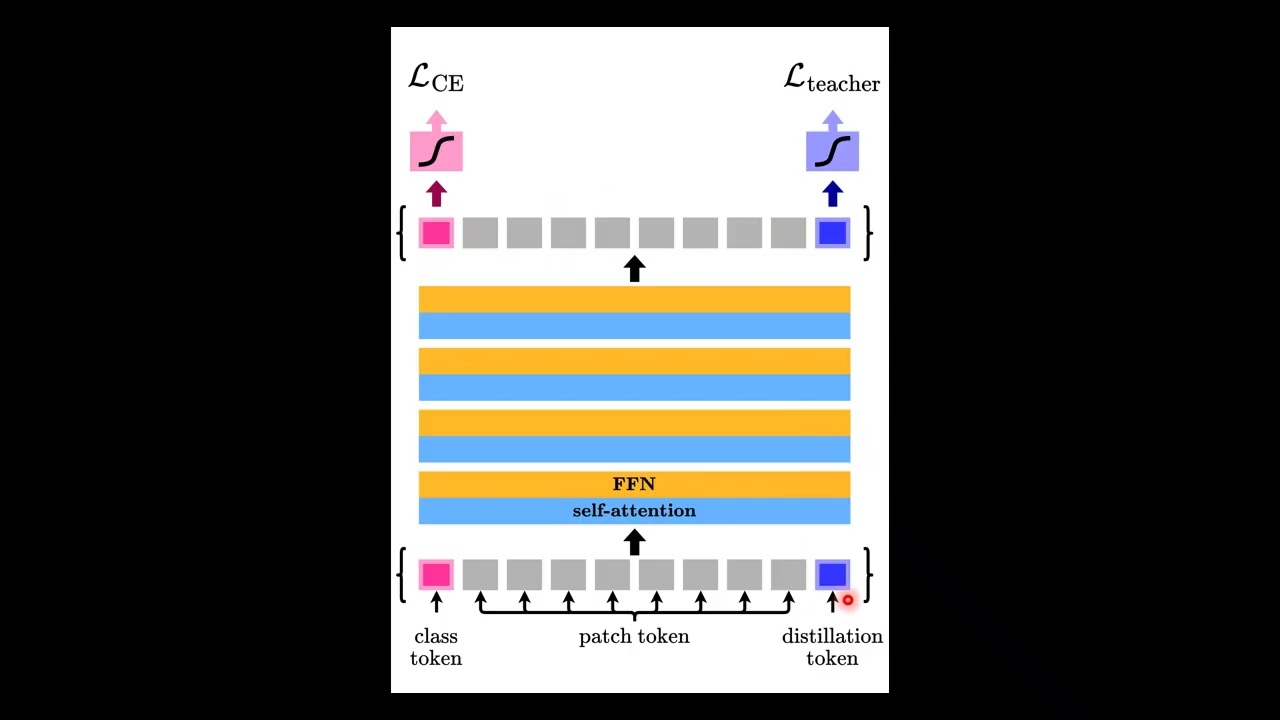
Vision Transformers changed computer vision by replacing convolutions with attention. But there was a major problem: they required enormous datasets and huge computational resources to work properly. So how did researchers make transformers practical for real-world vision tasks? In this video, we explore DeiT (Data-Efficient Image Transformers), a breakthrough that showed transformers can be trained using only ImageNet while achieving performance competitive with convolutional neural networks. We cover: ✅ Why Vision Transformers needed massive datasets ✅ The idea behind data-efficient training ✅ Class token vs Distillation token ✅ Transformer-specific knowledge distillation ✅ Why CNNs are surprisingly better teachers ✅ Hard vs soft distillation explained intuitively ✅ Training tricks that made DeiT work ✅ How inductive bias is transferred through supervision DeiT is not just a new architecture. It is a new way of training transformers, and it played a key role in making modern vision transformers practical. 📄 Paper: Training Data-Efficient Image Transformers & Distillation through Attention 👨🔬 Authors: Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou #DeiT #VisionTransformer #Transformers #ComputerVision #DeepLearning #MachineLearning #AIResearch #KnowledgeDistillation #SelfAttention #ImageClassification #NeuralNetworks #AIExplained #CVPR #ArtificialIntelligence #DLResearch
Comments