AWS EMR Spark, S3 Storage, Zeppelin Notebook скачать в хорошем качестве
AWS EMR Spark, S3 Storage, Zeppelin Notebook
8 лет назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: AWS EMR Spark, S3 Storage, Zeppelin Notebook в качестве 4k
У нас вы можете посмотреть бесплатно AWS EMR Spark, S3 Storage, Zeppelin Notebook или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон AWS EMR Spark, S3 Storage, Zeppelin Notebook в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
AWS EMR Spark, S3 Storage, Zeppelin Notebook
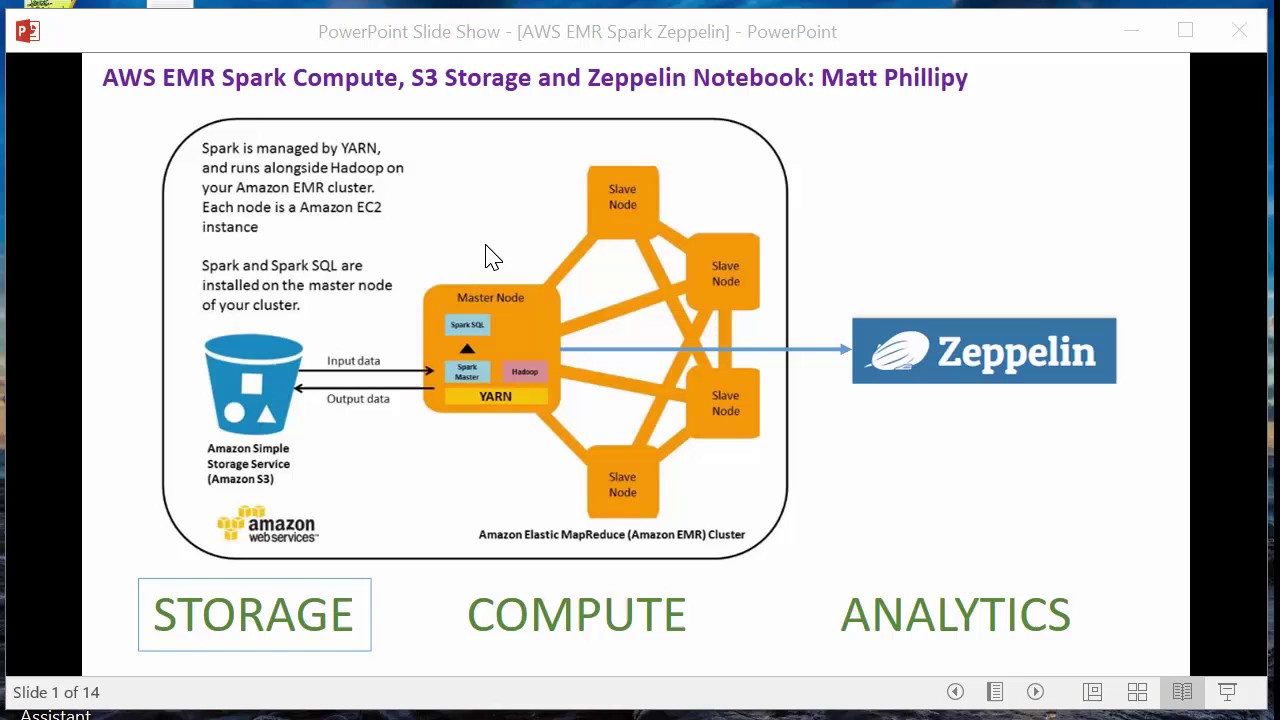
This is a demo on how to launch a basic big data solution using Amazon Web Services (AWS). This solution is comparable to the the Azure HDInsight Spark solution I created in another video. The AWS solution can be deployed in 10 minutes, provides high availability/durability, and can easily be scaled out to process terabytes of data. The “Compute” engine for this solution is an AWS Elastic Map Reduce Spark cluster, which is AWS’ Platform as a Service (PaaS) offering for Hadoop/Spark. From the UI, I believe AWS allows you to scale out to 20 nodes. If you need more than that then you need to call them! For the cluster configuration this demo, I calculated cluster cost at $0.45/hour. AWS rounds up to the nearest hour so even if launch and only use for 25 minutes then you still get charged for an hour, or $0.45. The “Storage” component is AWS Simple Storage Solution (S3), the primary general all purpose storage offering from AWS. Elastic Map Reduce (EMR) clusters come with an already configured interface allowing for integration with the Hadoop File System (HDFS). This can significantly reduce the need to manipulate files directly in HDFS if you are using S3 as storage. This means you can use the file path prefixed by S3://, instead of hdfs://. Zeppelin notebooks are ready to use once the cluster is active (less 5 minutes after launching the cluster). EMR clusters do not come with Jupyter notebooks automatically configured.
Comments