GPU Architecture Deep Dive: From HBM to Tensor Cores (Visually Explained) | M2L1 скачать в хорошем качестве
GPU Architecture Deep Dive: From HBM to Tensor Cores (Visually Explained) | M2L1
2 месяца назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: GPU Architecture Deep Dive: From HBM to Tensor Cores (Visually Explained) | M2L1 в качестве 4k
У нас вы можете посмотреть бесплатно GPU Architecture Deep Dive: From HBM to Tensor Cores (Visually Explained) | M2L1 или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон GPU Architecture Deep Dive: From HBM to Tensor Cores (Visually Explained) | M2L1 в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
GPU Architecture Deep Dive: From HBM to Tensor Cores (Visually Explained) | M2L1
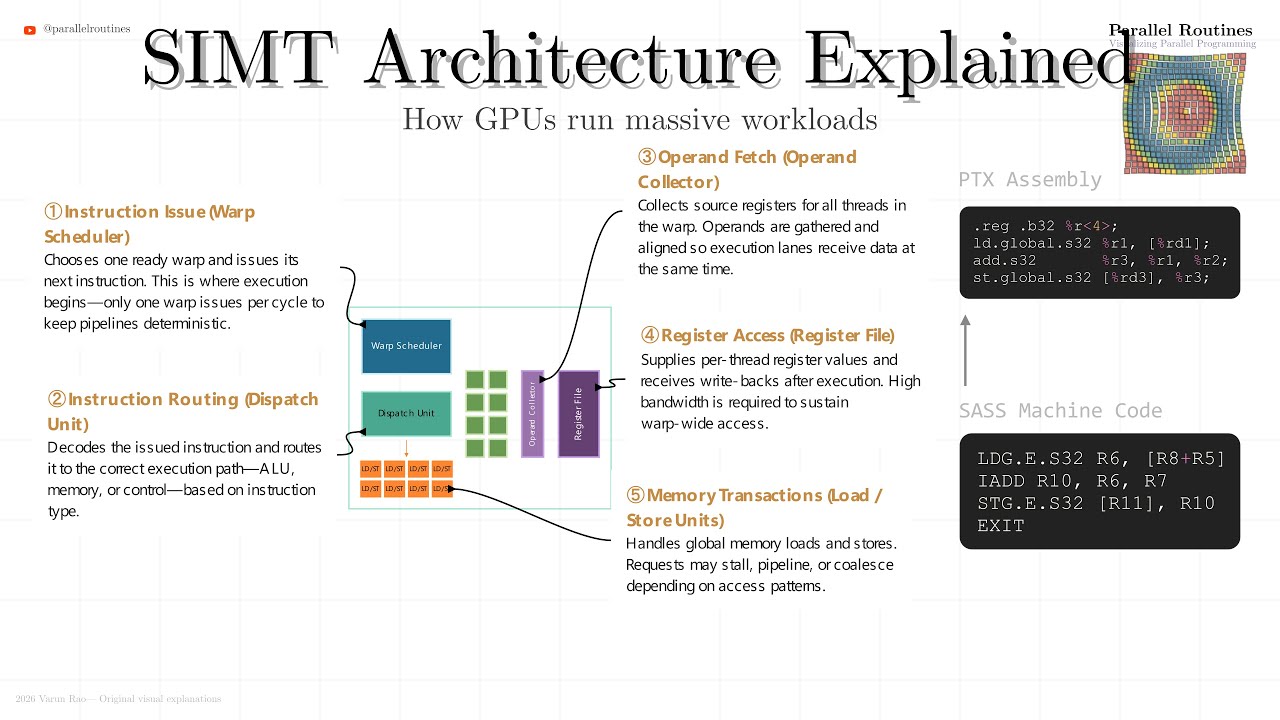
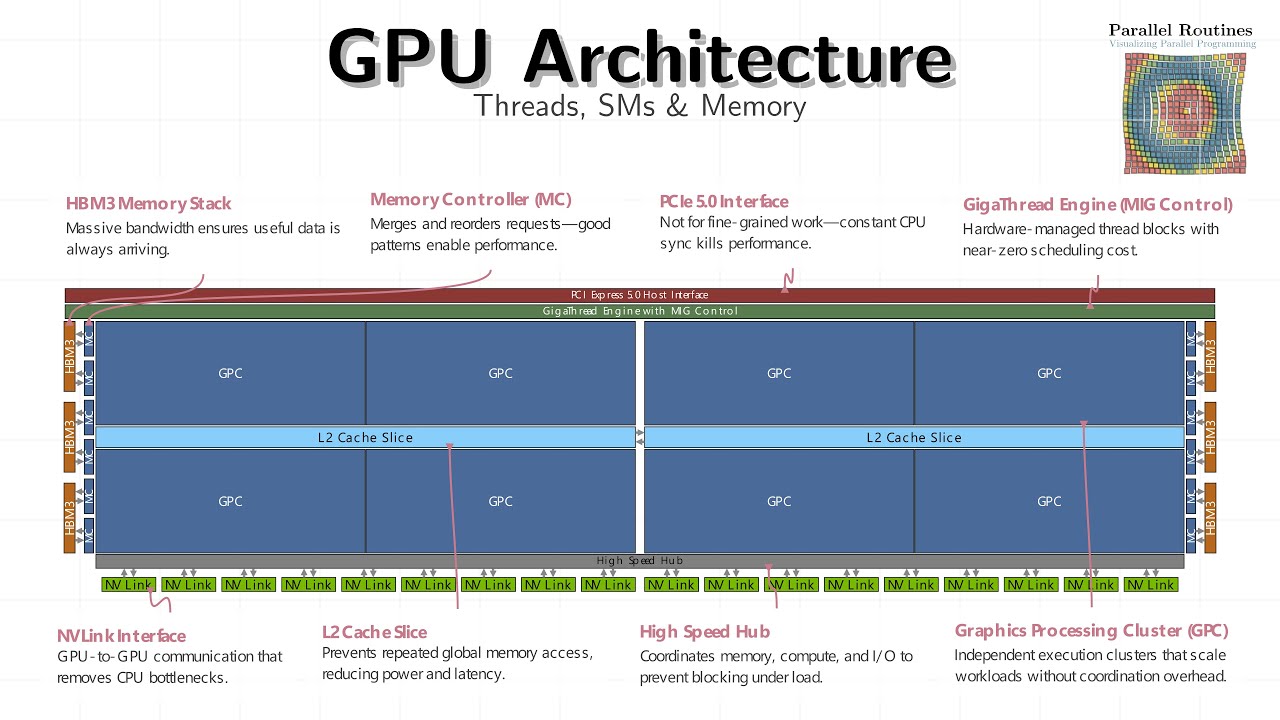
Why do GPUs stay fast even when memory is slow? Why do thousands of threads exist when only a few execute at a time? And why does GPU performance come from organization, not clock speed? In Module 2, Lesson 1, we take a visual, architectural tour of a modern GPU — not from a programming API view, but from the hardware’s point of view. This lesson builds the mental model you must have before writing performant CUDA, HIP, or GPU compute code. A GPU is not a fast single core. It is a throughput machine designed to keep work moving forward even when parts of the system are stalled. Through layered animations and guided narration, we walk from the outermost GPU structures down to the smallest execution units where your threads actually run. 🔍 What you’ll understand after this lesson • Why GPUs prioritize latency hiding over low latency • How HBM provides massive bandwidth but forces careful access patterns • What memory controllers, L2 cache, and the HUB really do • Why PCIe behaves differently from on-device memory • How NVLink enables true multi-GPU scaling • What a Graphics Processing Cluster (GPC) is and why GPUs scale by replication • How work is distributed through TPCs and SMs • Why the Streaming Multiprocessor (SM) is the most important unit for programmers • How warps are scheduled, dispatched, and swapped to hide stalls • The real role of registers, shared memory, and instruction caches • Why coalesced memory access matters more than raw compute • When FP32, FP64, and Tensor Cores are used — and why misuse hurts throughput By the end, GPU performance will stop feeling mysterious. You’ll see exactly where code waits, where it runs, and where data moves. 🧠 Who this is for • CUDA / GPU programmers who want predictable performance • Engineers moving from CPU thinking to GPU thinking • Students of parallel computing and HPC • Anyone building AI, ML, or simulation workloads on GPUs No math-heavy derivations — just clear mental models backed by hardware reality. 🧩 How this fits in the series This is Module 2 · Lesson 1 (M2L1) It follows Module 1 (Parallel Limits & Amdahl’s Law) and sets the foundation for: • Occupancy & latency hiding • Memory hierarchy optimization • Warp behavior & divergence • Persistent kernels • Tensor Core utilization • Real-world CUDA optimization strategy ⏱️ Timeline Overview 00:00 — Why GPUs are throughput machines 00:26 — The GPU die: overlap beats speed 00:39 — HBM: bandwidth vs latency 00:58 — Memory controllers & access patterns 01:14 — PCIe vs device memory 01:35 — GigaThread Engine & scheduling 01:59 — NVLink & multi-GPU scaling 02:09 — L2 cache & reuse 02:22 — The HUB: coordination under load 02:32 — Graphics Processing Clusters (GPCs) 02:45 — Why GPUs scale by replication 02:54 — TPCs, SMs, and execution layout 03:21 — Inside the Streaming Multiprocessor 03:37 — Instruction caches & branching 04:04 — Load/store pipelines 04:25 — SFUs, TMA, and background data movement 04:34 — Shared memory: power and pitfalls 04:53 — Texture units in modern AI workloads 05:09 — Warp scheduling & dispatch 05:35 — Registers, INT, FP32, FP64 units 06:39 — Tensor Cores: efficiency over flexibility 06:50 — Final takeaway: feed the machine continuously 📌 Final takeaway If you know where your code runs, where it waits, and where data flows, optimization stops being guesswork — it becomes engineering. #GPUArchitecture #CUDA #GPUProgramming #HighPerformanceComputing #ParallelComputing #AIAcceleration #TensorCores #SM #WarpScheduling #HBM
Comments