Can LLMs Guide Their Own Exploration? G2RL Explained — Gradient-Guided RL for Better LLM Reasoning скачать в хорошем качестве
Can LLMs Guide Their Own Exploration? G2RL Explained — Gradient-Guided RL for Better LLM Reasoning
2 –º–µ—Å—è—Ü–∞ –Ω–∞–∑–∞–¥
–ù–µ —É–¥–∞–µ—Ç—Å—è –∑–∞–≥—Ä—É–∑–∏—Ç—å Youtube-–ø–ª–µ–µ—Ä. –ü—Ä–æ–≤–µ—Ä—å—Ç–µ –±–ª–æ–∫–∏—Ä–æ–≤–∫—É Youtube –≤ –≤–∞—à–µ–π —Å–µ—Ç–∏.
–ü–æ–≤—Ç–æ—Ä—è–µ–º –ø–æ–ø—ã—Ç–∫—É...
–ü–æ–≤—Ç–æ—Ä—è–µ–º –ø–æ–ø—ã—Ç–∫—É...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Can LLMs Guide Their Own Exploration? G2RL Explained — Gradient-Guided RL for Better LLM Reasoning в качестве 4k
У нас вы можете посмотреть бесплатно Can LLMs Guide Their Own Exploration? G2RL Explained — Gradient-Guided RL for Better LLM Reasoning или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
–ò–Ω—Ñ–æ—Ä–º–∞—Ü–∏—è –ø–æ –∑–∞–≥—Ä—É–∑–∫–µ:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Can LLMs Guide Their Own Exploration? G2RL Explained — Gradient-Guided RL for Better LLM Reasoning в формате MP3:
–ï—Å–ª–∏ –∫–Ω–æ–ø–∫–∏ —Å–∫–∞—á–∏–≤–∞–Ω–∏—è –Ω–µ
–∑–∞–≥—Ä—É–∑–∏–ª–∏—Å—å
–ù–ê–ñ–ú–ò–¢–ï –ó–î–ï–°–¨ –∏–ª–∏ –æ–±–Ω–æ–≤–∏—Ç–µ —Å—Ç—Ä–∞–Ω–∏—Ü—É
–ï—Å–ª–∏ –≤–æ–∑–Ω–∏–∫–∞—é—Ç –ø—Ä–æ–±–ª–µ–º—ã —Å–æ —Å–∫–∞—á–∏–≤–∞–Ω–∏–µ–º –≤–∏–¥–µ–æ, –ø–æ–∂–∞–ª—É–π—Å—Ç–∞ –Ω–∞–ø–∏—à–∏—Ç–µ –≤ –ø–æ–¥–¥–µ—Ä–∂–∫—É –ø–æ –∞–¥—Ä–µ—Å—É –≤–Ω–∏–∑—É
—Å—Ç—Ä–∞–Ω–∏—Ü—ã.
–°–ø–∞—Å–∏–±–æ –∑–∞ –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏–µ —Å–µ—Ä–≤–∏—Å–∞ ClipSaver.ru
Can LLMs Guide Their Own Exploration? G2RL Explained — Gradient-Guided RL for Better LLM Reasoning
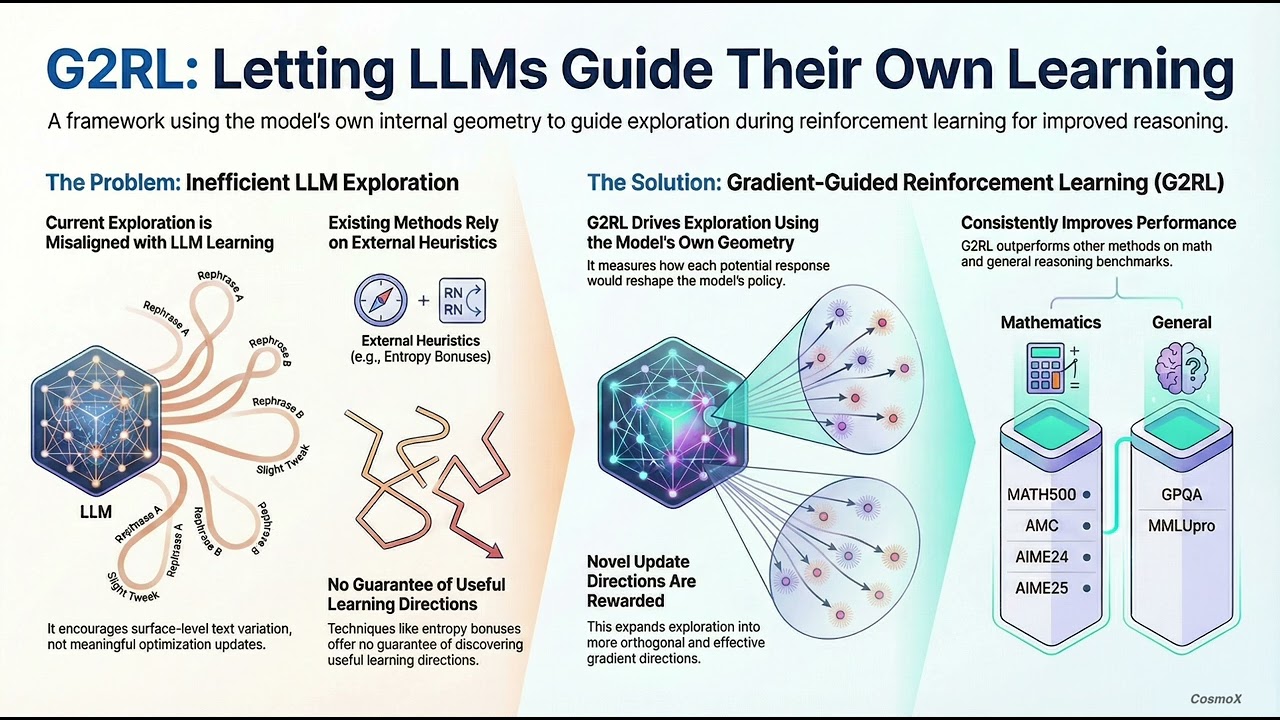
In this video, we break down the latest research paper ‚ÄúCan LLMs Guide Their Own Exploration? Gradient-Guided Reinforcement Learning for LLM Reasoning.‚Äù üîç What‚Äôs Inside: ‚Ä¢ Current RL exploration methods used in large language models (LLMs) often rely on heuristic signals like entropy bonuses, which may not align with how models actually learn. ‚Ä¢ G2RL (Gradient-Guided Reinforcement Learning) proposes a new way to drive exploration based on the model‚Äôs own gradient geometry, creating more meaningful update directions during training. ‚Ä¢ Experiments show improvements over typical RL approaches on reasoning benchmarks including math and general reasoning tests. üéØ We explain the idea behind G2RL, why it matters, and how it can enhance reasoning capabilities in LLMs ‚Äî all made easy to understand.
Comments
-
 3 –Ω–µ–¥–µ–ª–∏ –Ω–∞–∑–∞–¥
3 –Ω–µ–¥–µ–ª–∏ –Ω–∞–∑–∞–¥
-
 10 –¥–Ω–µ–π –Ω–∞–∑–∞–¥
10 –¥–Ω–µ–π –Ω–∞–∑–∞–¥
-
 1 –¥–µ–Ω—å –Ω–∞–∑–∞–¥
1 –¥–µ–Ω—å –Ω–∞–∑–∞–¥
-
 6 дней назад
6 –¥–Ω–µ–π –Ω–∞–∑–∞–¥
-
 4 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
4 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-
 4 –¥–Ω—è –Ω–∞–∑–∞–¥
4 –¥–Ω—è –Ω–∞–∑–∞–¥
-
 8 –¥–Ω–µ–π –Ω–∞–∑–∞–¥
8 –¥–Ω–µ–π –Ω–∞–∑–∞–¥
-
 2 –º–µ—Å—è—Ü–∞ –Ω–∞–∑–∞–¥
2 –º–µ—Å—è—Ü–∞ –Ω–∞–∑–∞–¥
-
 4 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
4 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-
 6 дней назад
6 –¥–Ω–µ–π –Ω–∞–∑–∞–¥
-
 1 месяц назад
1 –º–µ—Å—è—Ü –Ω–∞–∑–∞–¥
-
 7 –¥–Ω–µ–π –Ω–∞–∑–∞–¥
7 –¥–Ω–µ–π –Ω–∞–∑–∞–¥
-
 1 –≥–æ–¥ –Ω–∞–∑–∞–¥
1 –≥–æ–¥ –Ω–∞–∑–∞–¥
-
 1 –¥–µ–Ω—å –Ω–∞–∑–∞–¥
1 –¥–µ–Ω—å –Ω–∞–∑–∞–¥
-
 3 недели назад
3 –Ω–µ–¥–µ–ª–∏ –Ω–∞–∑–∞–¥
-
 2 –º–µ—Å—è—Ü–∞ –Ω–∞–∑–∞–¥
2 –º–µ—Å—è—Ü–∞ –Ω–∞–∑–∞–¥
-
 6 –º–µ—Å—è—Ü–µ–≤ –Ω–∞–∑–∞–¥
6 –º–µ—Å—è—Ü–µ–≤ –Ω–∞–∑–∞–¥
-
 1 –º–µ—Å—è—Ü –Ω–∞–∑–∞–¥
1 –º–µ—Å—è—Ü –Ω–∞–∑–∞–¥
-
 3 –Ω–µ–¥–µ–ª–∏ –Ω–∞–∑–∞–¥
3 –Ω–µ–¥–µ–ª–∏ –Ω–∞–∑–∞–¥
-
 3 дня назад
3 –¥–Ω—è –Ω–∞–∑–∞–¥