Newton Losses: Using Curvature Information for Learning with Differentiable Algorithms - NeurIPS2024 скачать в хорошем качестве
Newton Losses: Using Curvature Information for Learning with Differentiable Algorithms - NeurIPS2024
1 год назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Newton Losses: Using Curvature Information for Learning with Differentiable Algorithms - NeurIPS2024 в качестве 4k
У нас вы можете посмотреть бесплатно Newton Losses: Using Curvature Information for Learning with Differentiable Algorithms - NeurIPS2024 или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Newton Losses: Using Curvature Information for Learning with Differentiable Algorithms - NeurIPS2024 в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Newton Losses: Using Curvature Information for Learning with Differentiable Algorithms - NeurIPS2024
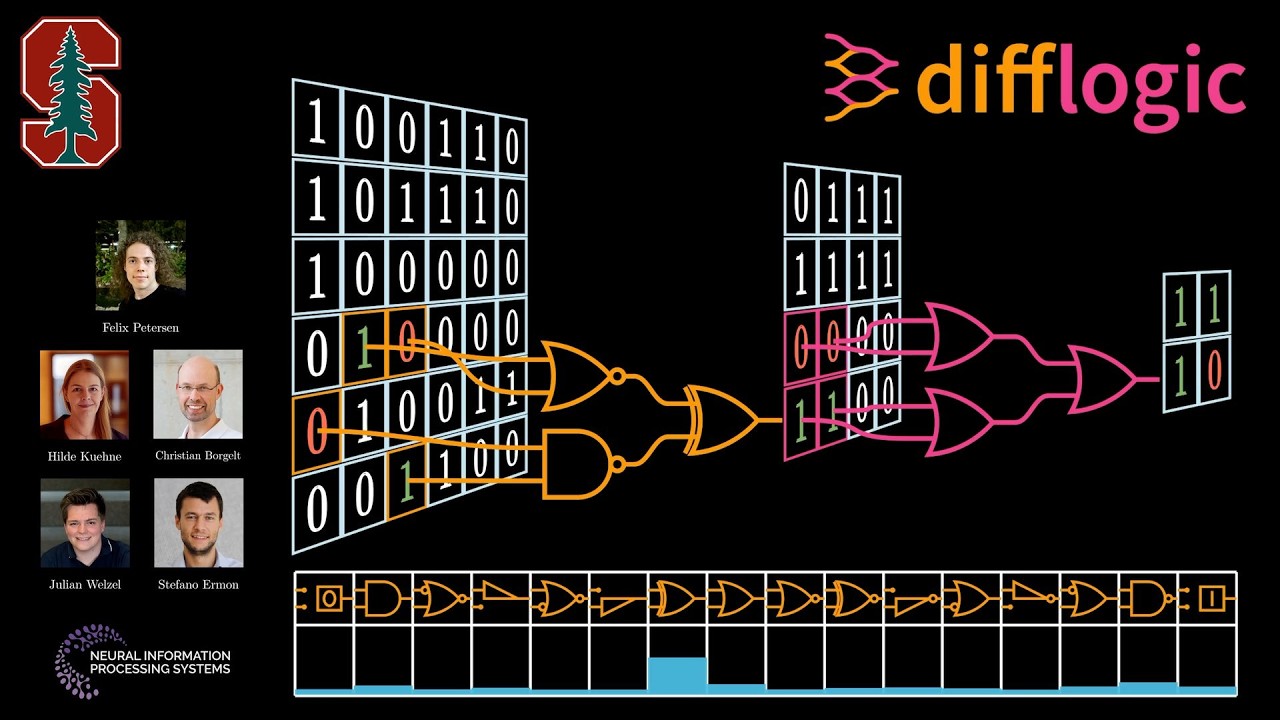
Official video for our NeurIPS 2024 Paper "Newton Losses: Using Curvature Information for Learning with Differentiable Algorithms". Felix Petersen, Christian Borgelt, Tobias Sutter, Hilde Kuehne, Oliver Deussen, Stefano Ermon Abstract: When training neural networks with custom objectives, such as ranking losses and shortest-path losses, a common problem is that they are, per se, non-differentiable. A popular approach is to continuously relax the objectives to provide gradients, enabling learning. However, such differentiable relaxations are often non-convex and can exhibit vanishing and exploding gradients, making them (already in isolation) hard to optimize. Here, the loss function poses the bottleneck when training a deep neural network. We present Newton Losses, a method for improving the performance of existing hard to optimize losses by exploiting their second-order information via their empirical Fisher and Hessian matrices. Instead of training the neural network with second-order techniques, we only utilize the loss function's second-order information to replace it by a Newton Loss, while training the network with gradient descent. This makes our method computationally efficient. We apply Newton Losses to eight differentiable algorithms for sorting and shortest-paths, achieving significant improvements for less-optimized differentiable algorithms, and consistent improvements, even for well-optimized differentiable algorithms. NeurIPS 2024 Paper: https://arxiv.org/abs/2410.19055 Code: https://github.com/Felix-Petersen/new...
Comments

















![Neural Networks for Abstraction & Reasoning (ARC-AGI) [NeurIPS 2024]](https://imager.clipsaver.ru/os3SHkrd-UQ/max.jpg)