Semantic Caching with Valkey and Redis: Reducing LLM Cost and Latency - Martin Visser скачать в хорошем качестве
Semantic Caching with Valkey and Redis: Reducing LLM Cost and Latency - Martin Visser
8 дней назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Semantic Caching with Valkey and Redis: Reducing LLM Cost and Latency - Martin Visser в качестве 4k
У нас вы можете посмотреть бесплатно Semantic Caching with Valkey and Redis: Reducing LLM Cost and Latency - Martin Visser или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Semantic Caching with Valkey and Redis: Reducing LLM Cost and Latency - Martin Visser в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Semantic Caching with Valkey and Redis: Reducing LLM Cost and Latency - Martin Visser
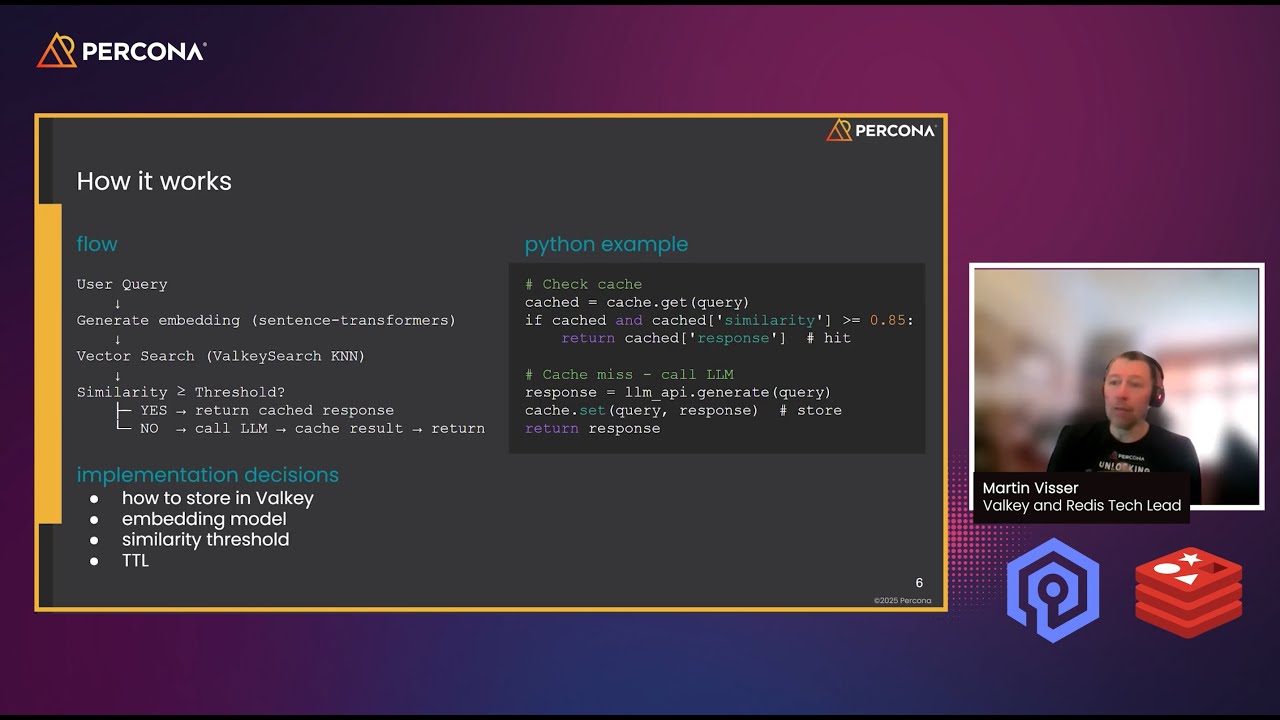
This presentation explains how semantic caching can significantly reduce the cost and latency of Large Language Model (LLM) applications by reusing meaningfully similar responses instead of exact matches. Using Valkey and Redis as vector databases, it walks through how embeddings, similarity thresholds, and TTLs work together to cache LLM responses efficiently. The talk includes practical architecture decisions, configuration trade-offs, cost comparisons, and a real-world demo showing how semantic caching can cut LLM usage by up to 60% while improving response times.
Comments












![Как происходит модернизация остаточных соединений [mHC]](https://imager.clipsaver.ru/jYn_1PpRzxI/max.jpg)






