RL 6: Policy iteration and value iteration - Reinforcement learning скачать в хорошем качестве
RL 6: Policy iteration and value iteration - Reinforcement learning
7 лет назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: RL 6: Policy iteration and value iteration - Reinforcement learning в качестве 4k
У нас вы можете посмотреть бесплатно RL 6: Policy iteration and value iteration - Reinforcement learning или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон RL 6: Policy iteration and value iteration - Reinforcement learning в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
RL 6: Policy iteration and value iteration - Reinforcement learning
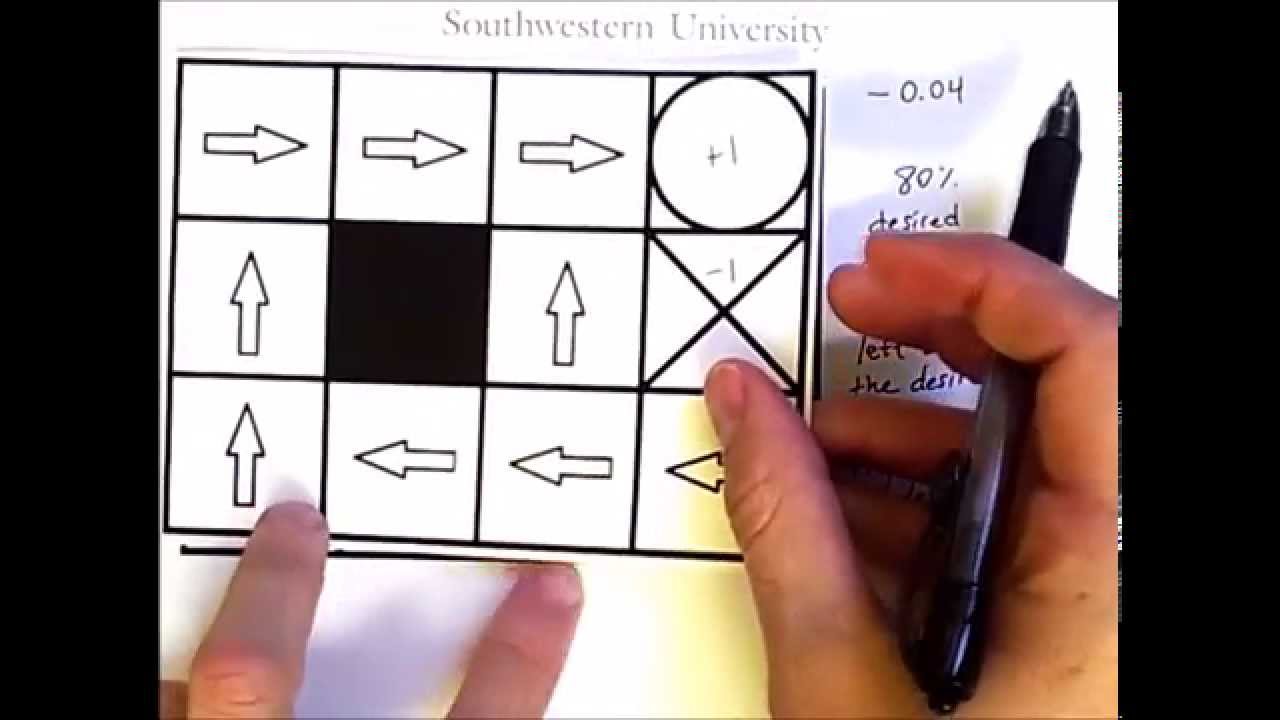
Policy iteration and value iteration - Policy iteration and value iterations are two very interesting as well as important algorithms in Reinforcement learning.These two algorithms are based on dynamic programming and Bellman equation. Value iteration algorithm and policy iteration algorithm are very useful for finding the optimal policy when the agent knows sufficient details about the environment model. In this video we alo talkabout Bellman optimality equation and optimal value function in reinforcement learning. Reinforcement learning tutorial series: 1. Multi-armed Bandits: • RL 1: Multi-armed Bandits 1 2. Multi-Armed Bandits - Action value estimation: • RL 2: Multi-Armed Bandits 2 - Action value... 3. Upper confidence bound: • RL 3: Upper confidence bound (UCB) to solv... 4. Thompson Sampling: • RL 4: Thompson Sampling - Multi-armed bandits 5. Markov Decision Process - MDP: • RL 5: Markov Decision Process - MDP | Rein... 6. Policy iteration and value iteration: • RL 6: Policy iteration and value iteration...
Comments