Transformers demystified: how do ChatGPT, GPT-4, LLaMa work? скачать в хорошем качестве
Transformers demystified: how do ChatGPT, GPT-4, LLaMa work?
1 год назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Transformers demystified: how do ChatGPT, GPT-4, LLaMa work? в качестве 4k
У нас вы можете посмотреть бесплатно Transformers demystified: how do ChatGPT, GPT-4, LLaMa work? или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Transformers demystified: how do ChatGPT, GPT-4, LLaMa work? в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Transformers demystified: how do ChatGPT, GPT-4, LLaMa work?
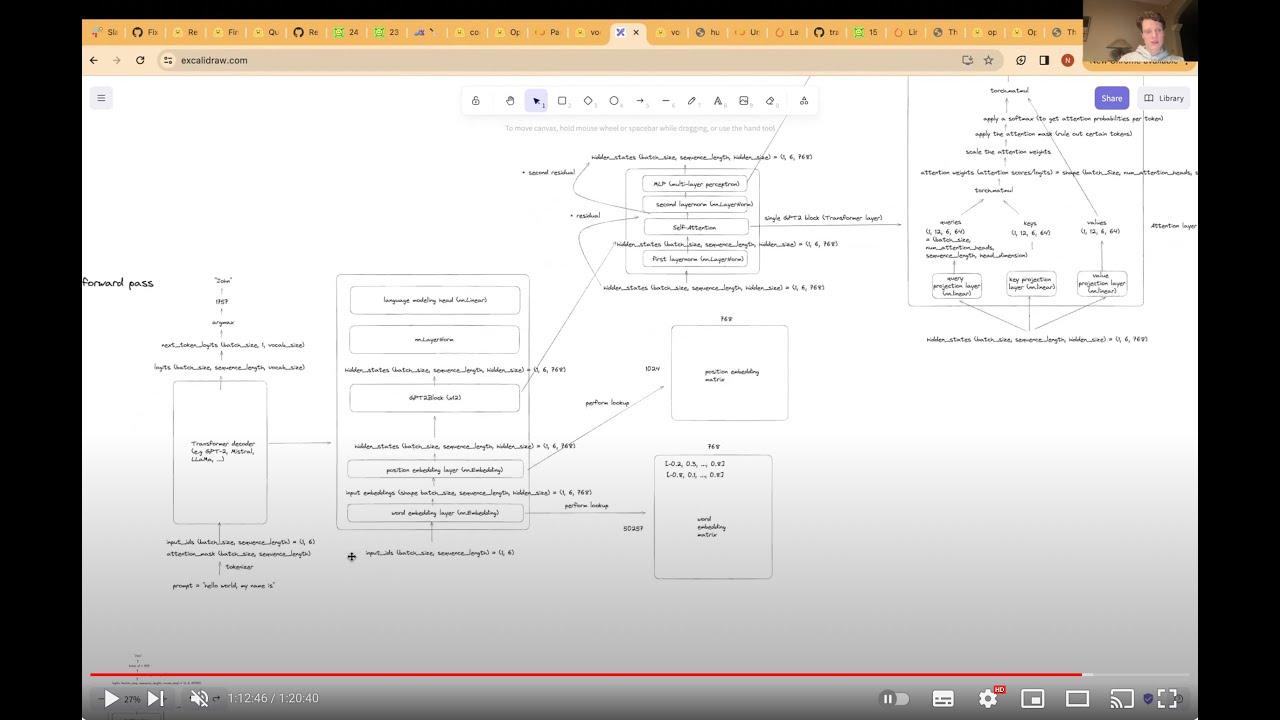
In this video, I explain in detail how large language models (LLMs) like GPT-2, ChatGPT, LLaMa, GPT-4, Mistral, etc. work, by going over the code as they are implemented in the Transformers library by Hugging Face. We start by converting text into so-called input_ids, which are integer indices in the vocabulary of a Transformer model. Internally, those get converted into so-called "hidden states", which are embeddings for each of the input tokens. Finally, the last hidden states get turned into so-called "logits" which are unnormalized scores. We can get the model's prediction for the next token by taking the logits of the last token in the sequence and performing an argmax operator on it. This gives us the index of the next token in the model's vocabulary. Note: there are some small tweaks among large language models: some use absolute position embeddings (as shown in this video for GPT-2), newer models like LLaMa and Mistral use RoPe or Alibi position embeddings (but position embeddings would deserve its own video) some models place the layernorms before or after the self-attention Those details were skipped to get the gist of the entire architecture of GPT-2.
Comments



















