OpsWorker AI Solves Real Kubernetes Incidents: CPU Saturation & Memory Leak Demo скачать в хорошем качестве
OpsWorker AI Solves Real Kubernetes Incidents: CPU Saturation & Memory Leak Demo
2 недели назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: OpsWorker AI Solves Real Kubernetes Incidents: CPU Saturation & Memory Leak Demo в качестве 4k
У нас вы можете посмотреть бесплатно OpsWorker AI Solves Real Kubernetes Incidents: CPU Saturation & Memory Leak Demo или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон OpsWorker AI Solves Real Kubernetes Incidents: CPU Saturation & Memory Leak Demo в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
OpsWorker AI Solves Real Kubernetes Incidents: CPU Saturation & Memory Leak Demo
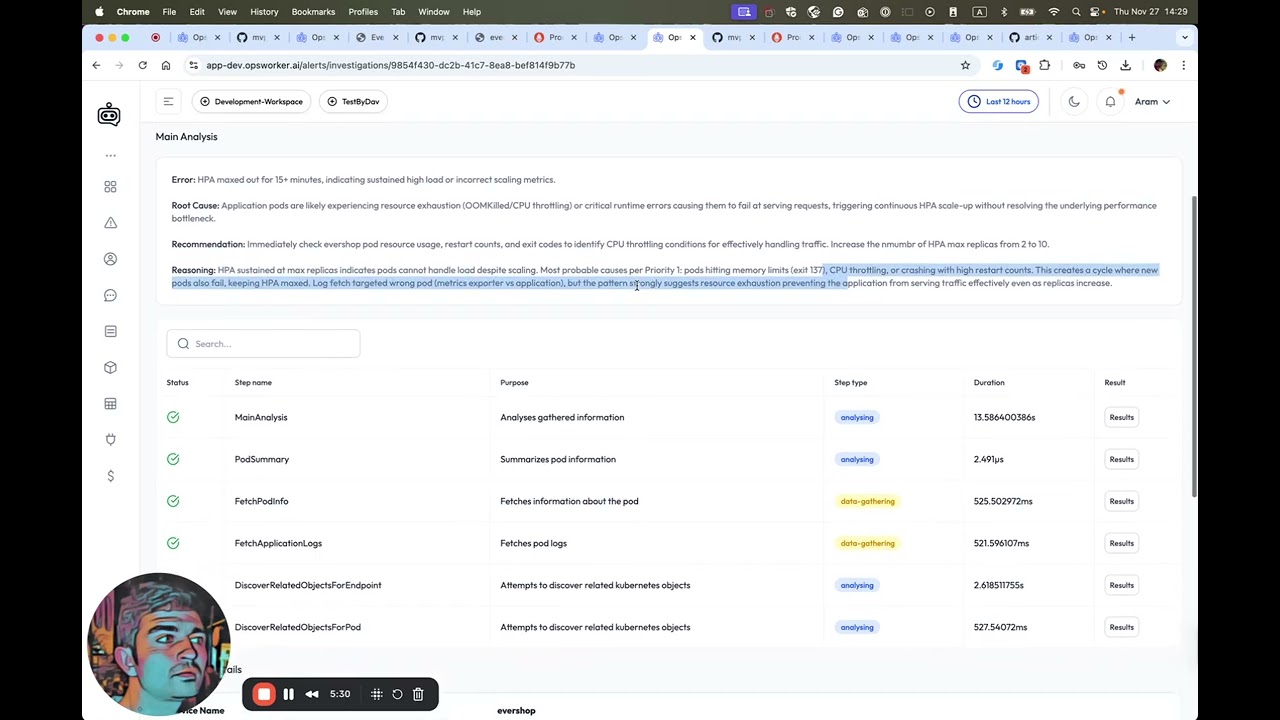
🚀 Watch OpsWorker AI automatically investigate and solve two common Kubernetes production incidents See how our AI SRE agent handles real-world failure scenarios—from alert to root cause to fix recommendations—in minutes, not hours. This demo shows OpsWorker tackling the incidents that wake you up at 3 AM: CPU saturation hitting HPA limits and memory leaks causing OOM kills. No manual log diving. No context switching across dashboards. Just fast, accurate root cause analysis delivered directly to your team. 🎯 INCIDENTS DEMONSTRATED: Scenario 1: CPU Saturation & HPA Limit [01:24] The Problem: Workload hitting 100% CPU usage Horizontal Pod Autoscaler (HPA) maxed out at configured replica limit Application performance degrading under load OpsWorker's Investigation: Traced alert back to source deployment Analyzed CPU metrics and HPA behavior Identified root cause: CPU saturation at max replica count Fix Recommendation: Increase HPA maximum replicas to handle peak load Scenario 2: Memory Leak → OOM Kill [03:55] The Problem: Container repeatedly killed with Out-Of-Memory errors Liveness probe failures after OOM kills 403 errors impacting users OpsWorker's Investigation: Detected OOM kill pattern in pod events Correlated memory usage trends with failures Identified root cause: Insufficient memory limits for workload Fix Recommendation: Increase memory limits (immediate) + investigate memory leak source (long-term) ⚡ KEY BENEFITS: Fast Answers Surface root cause in minutes, not hours. Drastically reduce Mean Time to Resolution (MTR). Automatic Investigation Pre-configure rules by namespace, severity, or labels. OpsWorker starts investigating the moment alerts fire. Clear Root Cause Analysis Get concrete RCA with: What happened (error description) Why it happened (root cause) How to fix it (immediate actions + preventive measures) Why this conclusion (explainable reasoning) Reduced On-Call Noise Configure investigation rules to focus only on what matters (e.g., production namespaces). Stop chasing false positives. Delivered Where You Work Investigation results in dashboard + Slack channels. No tool switching required. 🔧 DEMONSTRATED FEATURES: Alert configuration and rule-based auto-investigation Namespace-specific investigation triggers (e.g., evershop only) Real-time RCA as incidents occur Actionable fix recommendations with reasoning Slack integration for team collaboration Historical investigation tracking and trends 📋 TIMESTAMPS: 0:00 - Introduction: OpsWorker AI for Real Incidents 0:14 - How OpsWorker Handles Production Scenarios 0:27 - Two Common Kubernetes Failure Modes 0:54 - Alert Configuration Review (Namespace Filtering) 1:24 - Scenario 1: CPU Saturation & HPA Limit 2:32 - OpsWorker's Investigation Process (CPU) 3:15 - RCA & Fix Recommendations (CPU Issue) 3:55 - Scenario 2: Memory Leak → OOM Kill 4:30 - OpsWorker's Analysis of OOM Incident 4:52 - RCA & Fix Recommendations (Memory Leak) 5:23 - Summary: Reducing MTR & On-Call Noise 5:52 - Coming Next: Multi-Agent SRE Investigation Team Watch multiple specialized agents coordinate to solve incidents that require cross-domain expertise. 📅 Subscribe to catch the series! 🔗 RESOURCES: OpsWorker Website: https://www.opsworker.ai Technical Deep-Dive: Intelligent Investigation Join Beta Program:https://calendly.com/opsworker Previous Update: User Experience & Features 🎯 WHO SHOULD WATCH: SREs tired of manual incident investigation DevOps engineers dealing with K8s alert fatigue Platform teams supporting multiple development teams Engineering leaders looking to reduce MTTR Anyone running production Kubernetes workloads 📊 THE OPSWORKER DIFFERENCE: Traditional Incident Response: Alert fires at 3 AM Wake up, context switch Check logs, metrics, events across tools Build hypothesis, test, repeat Find root cause after 2+ hours Fix and document With OpsWorker AI: Alert fires OpsWorker auto-investigates Receive RCA + fix in Slack in less than 5 minutes Review reasoning, apply fix Back to sleep (or stay focused on strategic work) 📢 ABOUT OPSWORKER: OpsWorker is your 24/7 AI SRE co-worker that lives inside your Kubernetes environment. We eliminate operational toil through intelligent automation that augments your engineering team—never replaces them. Our Mission: Give every team access to senior SRE-level incident investigation, regardless of team size or budget. Follow Us: LinkedIn: https://de.linkedin.com/company/opsworker-ai Twitter/X: https://x.com/OpsWorker_ai Blog: https://www.opsworker.ai/blog #️⃣ TAGS: #OpsWorkerAI #Kubernetes #K8s #SRE #DevOps #AIOps #IncidentResponse #RootCauseAnalysis #Automation #KubernetesMonitoring #OOMKill #CPUSaturation #HPA #MemoryLeak #techdemo #CloudNative #SiteReliabilityEngineering #MTTR #AlertFatigue #ProductionIncidents
Comments