Triton Blocked Matrix Multiplication | A MyTorch Sidequest! скачать в хорошем качестве
Triton Blocked Matrix Multiplication | A MyTorch Sidequest!
5 часов назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
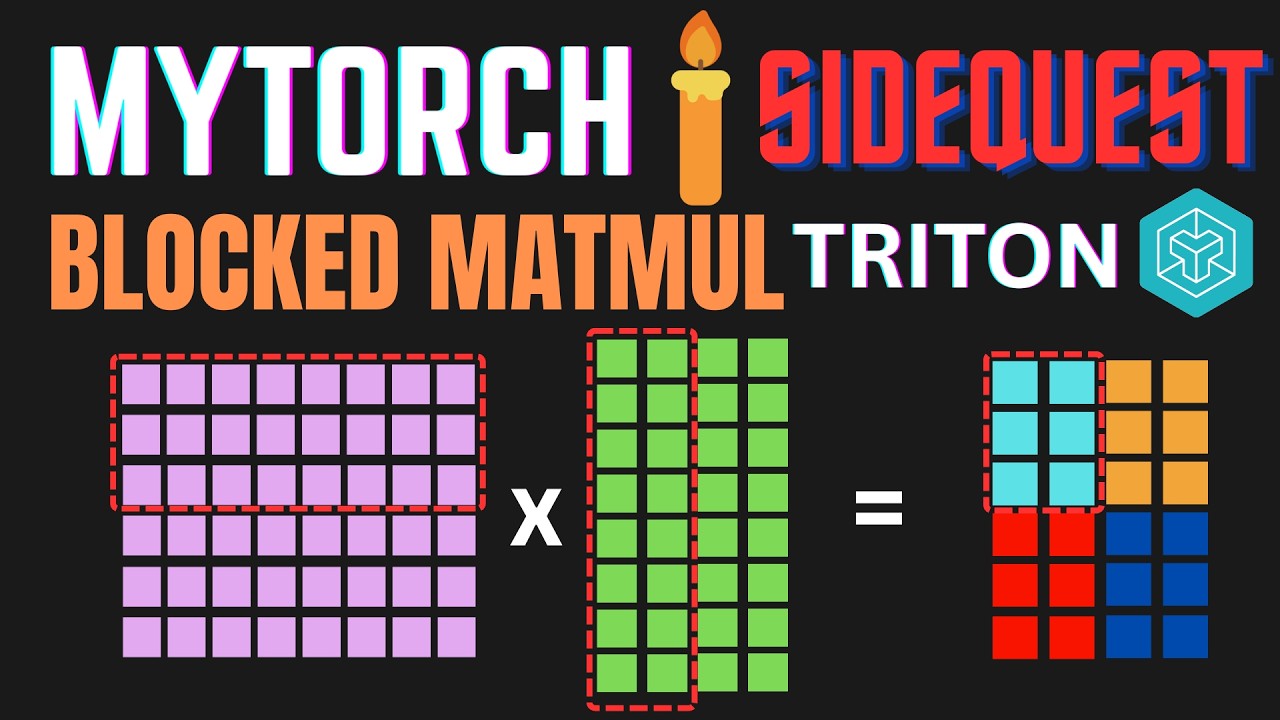
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Triton Blocked Matrix Multiplication | A MyTorch Sidequest! в качестве 4k
У нас вы можете посмотреть бесплатно Triton Blocked Matrix Multiplication | A MyTorch Sidequest! или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Triton Blocked Matrix Multiplication | A MyTorch Sidequest! в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Triton Blocked Matrix Multiplication | A MyTorch Sidequest!
Code: https://github.com/priyammaz/TritonKe... Previously we implemented a very slow Matrix Multiplication kernel in Triton. The main reason was that each PID was responsible for one of the outputs in the result of our matmul. Instead, we will now make every PID responsible for a block of outputs in the matmul, reducing the overall scheduling overhead and increasing throughput! Timestamps: 00:00:00 - What is Blocked Matmul? 00:03:00 - Lets write the Pseudocode! 00:10:00 - Start Triton Blocked MatMul 00:13:00 - How Offsets are computed 00:17:20 - Get our pointers to block of A and B 00:21:00 - Loop over inner dimension K in blocks 00:22:08 - Perform the Multiply Accumulate Operation 00:28:30 - Store results in final output array 00:30:13 - Triton Autotuner 00:33:48 - Dynamic grid calculation 00:36:05 - Quick bug fix 00:36:40 - Tensorfloat32 Precision Issues 00:39:00 - Performance comparisons Socials! X / data_adventurer Instagram / nixielights Linkedin / priyammaz Discord / discord 🚀 Github: https://github.com/priyammaz 🌐 Website: https://www.priyammazumdar.com/
Comments
-
 5 часов назад
5 часов назад
-
 2 недели назад
2 недели назад
-
 6 дней назад
6 дней назад
-
 2 недели назад
2 недели назад
-
 3 недели назад
3 недели назад
-
 3 месяца назад
3 месяца назад
-
 3 месяца назад
3 месяца назад
-
 4 дня назад
4 дня назад
-
 2 недели назад
2 недели назад
-
 Трансляция закончилась 15 часов назад
Трансляция закончилась 15 часов назад
-
 4 месяца назад
4 месяца назад
-
 1 год назад
1 год назад
-
 3 дня назад
3 дня назад
-
 10 дней назад
10 дней назад
-
 4 месяца назад
4 месяца назад
-
 4 месяца назад
4 месяца назад
-
 13 дней назад
13 дней назад
-
 2 года назад
2 года назад
-
 4 года назад
4 года назад
-
 1 день назад
1 день назад