Associating protein residues with structural data скачать в хорошем качестве
Associating protein residues with structural data
4 дня назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Associating protein residues with structural data в качестве 4k
У нас вы можете посмотреть бесплатно Associating protein residues with structural data или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Associating protein residues with structural data в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Associating protein residues with structural data
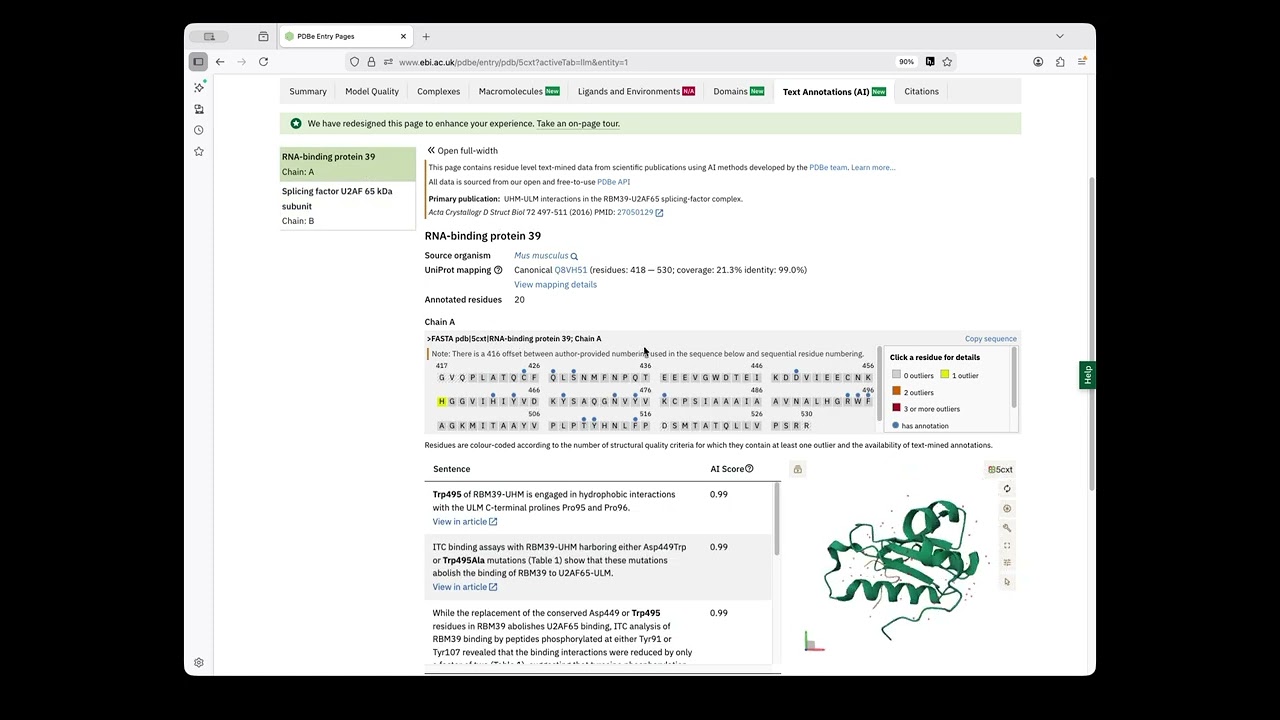
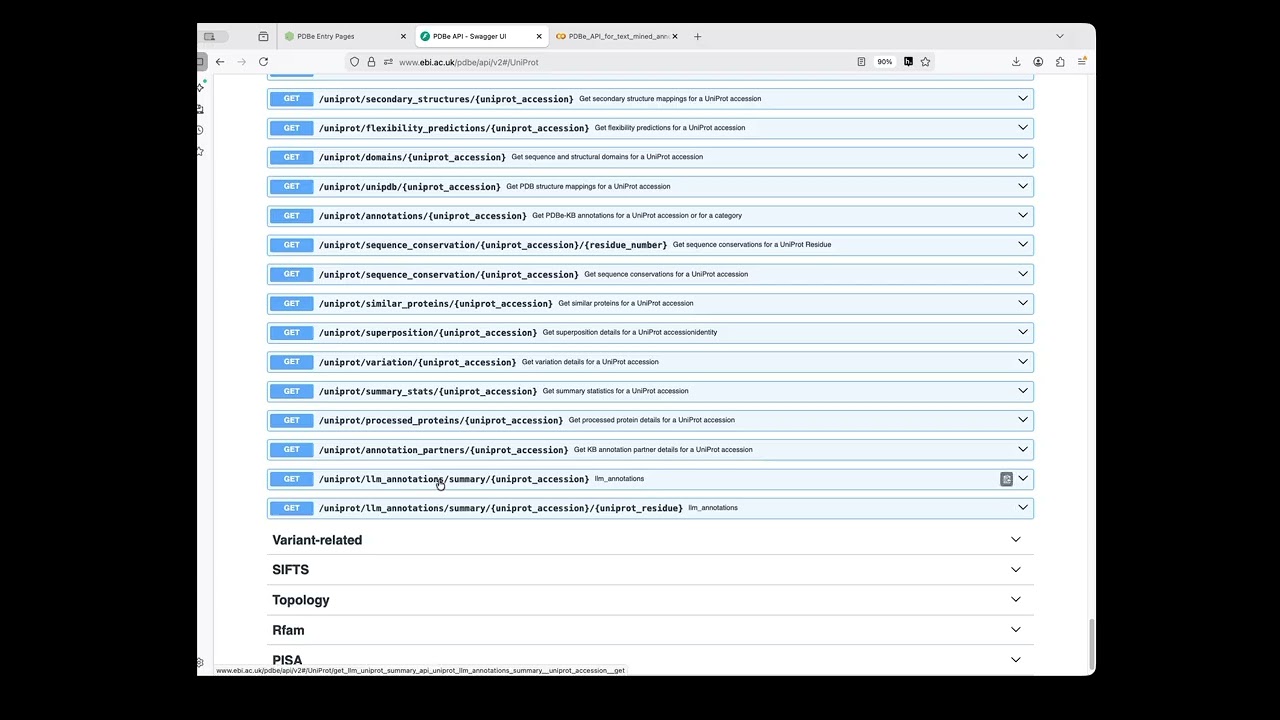
Supplementary Video S3. Published in Acta Cryst. D https://doi.org/10.1107/S205979832600... Associating protein residues in the literature with structural data Protein structures are crucial in understanding the function, mechanism and disease-causing variants of proteins within any living cell. A number of experimental techniques are employed by researchers to determine such structures. Through structure inspection in molecular viewers, combined with supporting biochemical and biophysical experiments, scientists are able to identify the function of a protein, its reaction mechanism and effects caused by sequence variation. These detailed findings, supported by experimental results, are documented by being described in the scientific literature and by making the accompanying data open source. However, it has become increasingly difficult for a reader, in particular a non-expert, to access the correct additional information and assess the validity of the conclusions drawn based on experimental results. A reader is often required to resort to a number of different software packages to access the different data types. Here, we present a first-of-its-kind implementation of an artificial intelligence- and text-mining-supported software tool that allows the association of mentions in the text of one or more specific protein residues with their corresponding counterparts in the respective protein structure or structures. Our application allows a researcher to explore a residue of interest in the context of a publication and its respective protein structure, supported by its experimental evidence, in a single view. We describe model implementation, annotation extraction, downstream processing, dissemination and visualization at the IUCr and PDBe. The application presented is primarily aimed at readers of IUCr publications and users visiting the PDBe entry pages. However, we believe that in the future our application will be a valuable tool for reviewers of new submissions to IUCr journals and may even be useful as a curation tool involving the authors of a publication as annotation validators.
Comments