Decoder Architecture in Transformers | Step-by-Step from Scratch скачать в хорошем качестве
Decoder Architecture in Transformers | Step-by-Step from Scratch
10 месяцев назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Decoder Architecture in Transformers | Step-by-Step from Scratch в качестве 4k
У нас вы можете посмотреть бесплатно Decoder Architecture in Transformers | Step-by-Step from Scratch или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Decoder Architecture in Transformers | Step-by-Step from Scratch в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Decoder Architecture in Transformers | Step-by-Step from Scratch
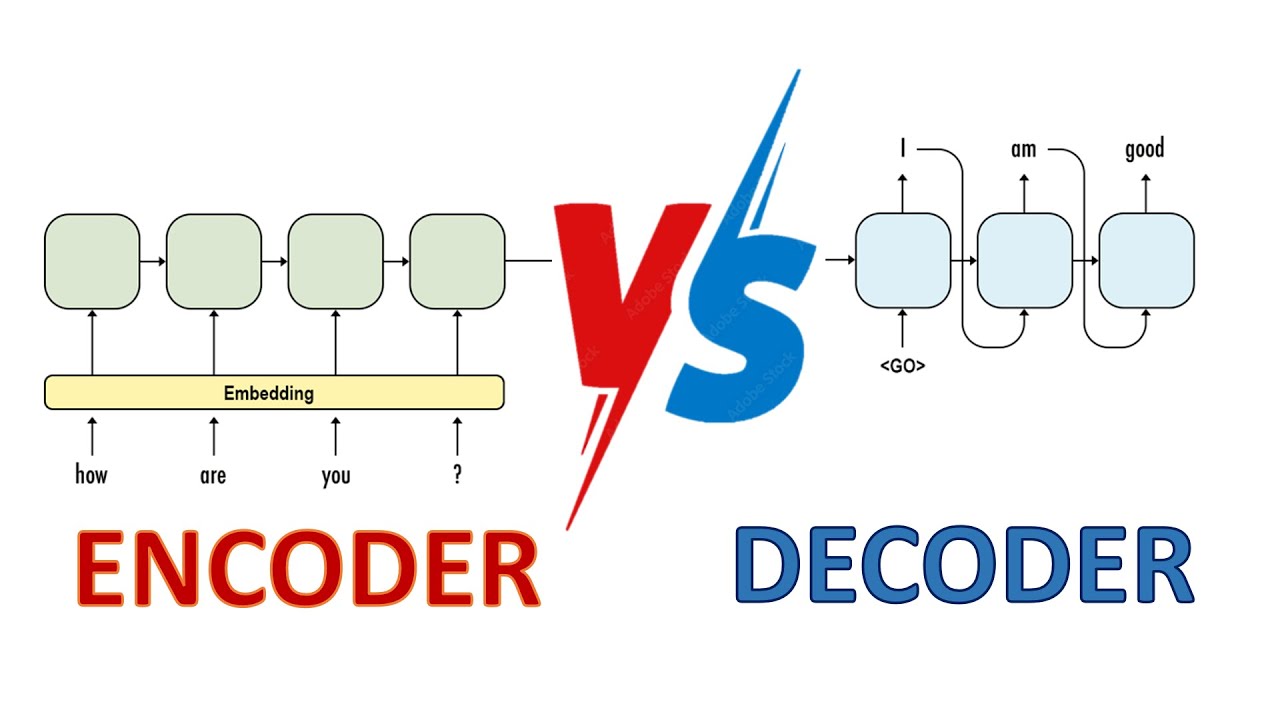
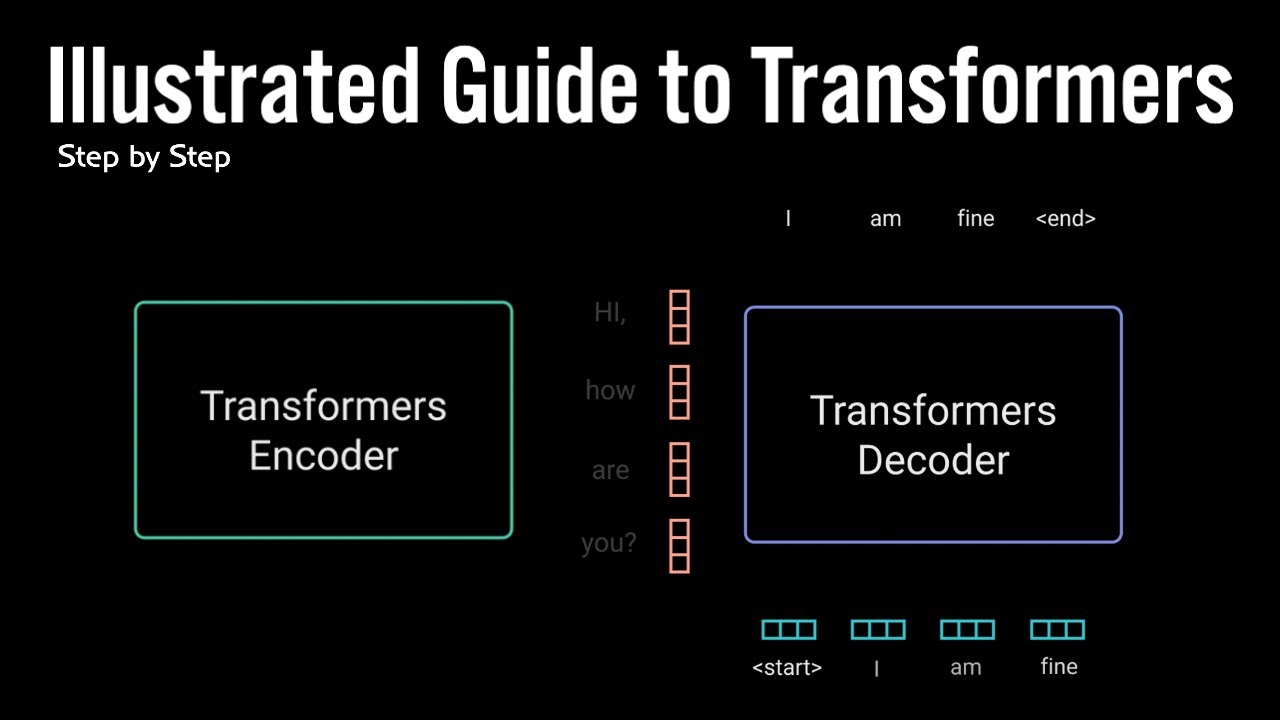
Transformers have revolutionized deep learning, but have you ever wondered how the decoder in a transformer actually works? 🤔 In this video, we break down Decoder Architecture in Transformers step by step! 💡 What You’ll Learn: ✅ The fundamentals of encoding-decoding in deep learning and how it's different in Transformers. ✅ The role of each layer in the decoder and how they work together. ✅ A deep dive into masked self-attention, cross-attention, and feed-forward networks in the decoder. ✅ How transformers generate meaningful sequences in tasks like language modeling, machine translation, and text generation. By the end of this video, you'll have be able to map the entire Decoder Architecture in Transformers by hand, using a pen & a paper and understand why it's so powerful! 🔔 Don’t forget to Like, Subscribe, and hit the Bell Icon so you never miss out on high-quality ML content! ➖➖➖➖➖➖➖➖➖➖➖➖➖➖➖ Timestamps: 0:00 Intro 0:56 Encoder-Decoder model in Deep Learning 2:24 Encoder-Decoder in Transformers 5:25 Parallelizing Training in Transformers 12:57 Masked Multi-head attention 19:29 Encoder-Decoder in training of Transformers 22:01 Positional Encodings 23:08 Add & Norm Layer 24:47 Cross Attention 32:33 Feed Forward Network 33:53 Stacking of Decoder blocks 34:42 Final Prediction Layer 37:06 Decoder during inference 40:05 Outro ➖➖➖➖➖➖➖➖➖➖➖➖➖➖➖ 📕 Check my Encoder Architecture video: • Encoder Architecture in Transformers | Ste... ➖➖➖➖➖➖➖➖➖➖➖➖➖➖➖ Follow my entire Transformers playlist : 📕 Transformers Playlist: • Transformers in Deep Learning | Introducti... ➖➖➖➖➖➖➖➖➖➖➖➖➖➖➖ ✔ RNN Playlist: • What is Recurrent Neural Network in Deep L... ✔ CNN Playlist: • What is CNN in deep learning? Convolutiona... ✔ Complete Neural Network: • How Neural Networks work in Machine Learni... ✔ Complete Logistic Regression Playlist: • Logistic Regression Machine Learning Examp... ✔ Complete Linear Regression Playlist: • What is Linear Regression in Machine Learn... ➖➖➖➖➖➖➖➖➖➖➖➖➖➖➖
Comments




![Как внимание стало настолько эффективным [GQA/MLA/DSA]](https://imager.clipsaver.ru/Y-o545eYjXM/max.jpg)










![Как происходит модернизация остаточных соединений [mHC]](https://imager.clipsaver.ru/jYn_1PpRzxI/max.jpg)

