End-to-End Video Object Detection with Spatial-Temporal Transformers скачать в хорошем качестве
End-to-End Video Object Detection with Spatial-Temporal Transformers
4 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: End-to-End Video Object Detection with Spatial-Temporal Transformers в качестве 4k
У нас вы можете посмотреть бесплатно End-to-End Video Object Detection with Spatial-Temporal Transformers или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон End-to-End Video Object Detection with Spatial-Temporal Transformers в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
End-to-End Video Object Detection with Spatial-Temporal Transformers
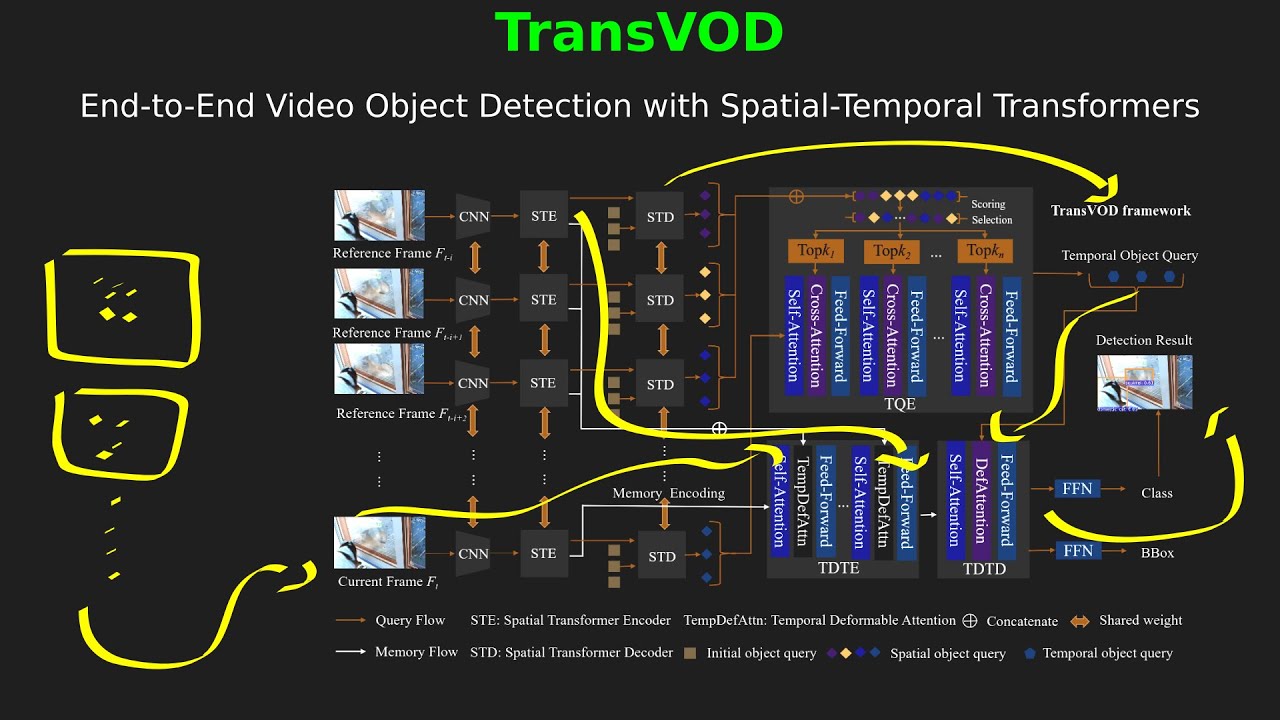
End-to-End Video Object Detection with Spatial-Temporal Transformers (Machine Learning Research Paper Explained) #machinelearning #transformers #objectdetection #pointclouds Sources: https://arxiv.org/abs/2105.10920 https://arxiv.org/abs/2005.12872 https://arxiv.org/abs/2010.04159 DETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. However, it suffers from slow convergence and limited feature spatial resolution, due to the limitation of Transformer attention modules in processing image feature maps. To mitigate these issues, we proposed Deformable DETR, whose attention modules only attend to a small set of key sampling points around a reference. Deformable DETR can achieve better performance than DETR (especially on small objects) with 10 times less training epochs. Extensive experiments on the COCO benchmark demonstrate the effectiveness of our approach. Code is released at this https URL. 0:00 Intro 0:28 Problem formulation 3:08 Overview 3:36 Architecture overview 6:06 Architecture deep-dive 32:53 Architecture Review 34:47 Results 41:33 Outro
Comments











![Почему работает теория шести рукопожатий? [Veritasium]](https://imager.clipsaver.ru/ggI1xKzoANs/max.jpg)