Tricks Learned from Training Large Open-Source Models | FOSDEM 2025 скачать в хорошем качестве
Tricks Learned from Training Large Open-Source Models | FOSDEM 2025
10 месяцев назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Tricks Learned from Training Large Open-Source Models | FOSDEM 2025 в качестве 4k
У нас вы можете посмотреть бесплатно Tricks Learned from Training Large Open-Source Models | FOSDEM 2025 или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Tricks Learned from Training Large Open-Source Models | FOSDEM 2025 в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Tricks Learned from Training Large Open-Source Models | FOSDEM 2025
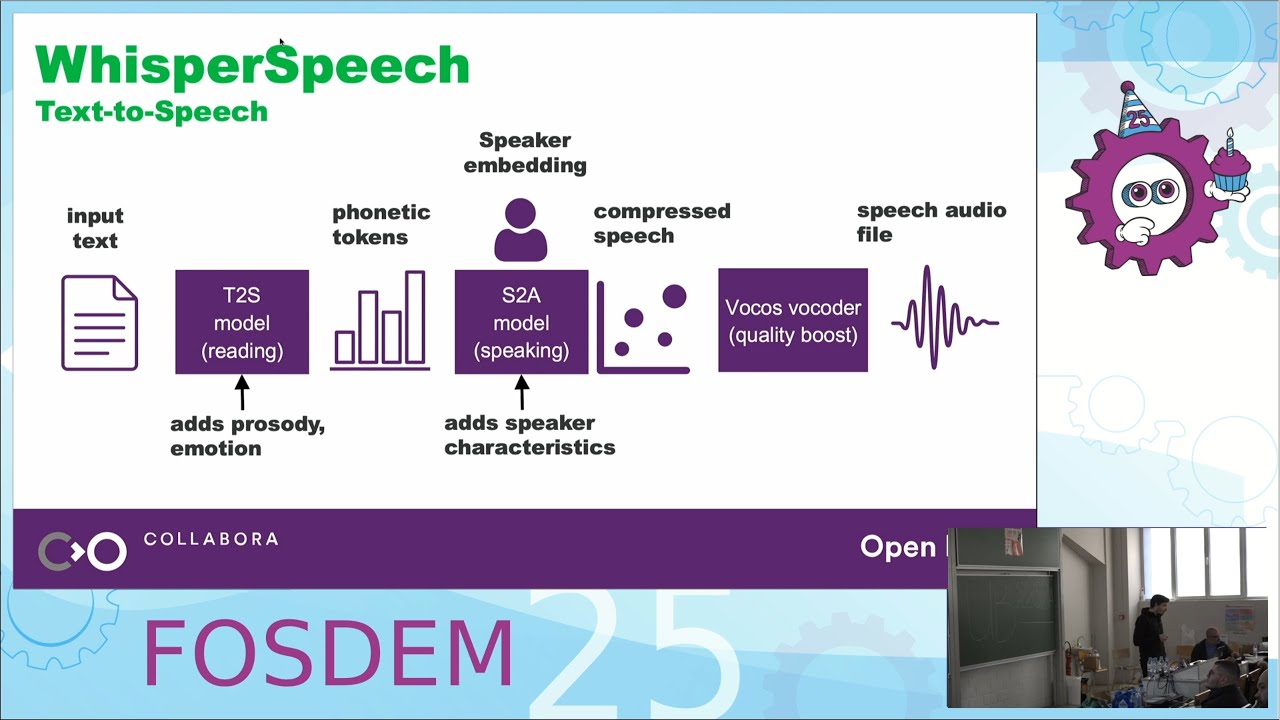
Tricks learned from training large open-source models on the example of WhisperSpeech, an open-source text-to-speech model. WhisperSpeech is a new open-source text-to-speech model created by Collabora. It is based on recent research from the biggest AI labs (Google, Meta, Microsoft, OpenAI). It delivers high-quality speech that it learned from tens of thousands of hours of human speech recordings. To deliver state-of-the-art quality, we scaled our models and training pipelines from hundreds to tens of thousands of hours of speech, and we share the lessons learned along the way. Nearly every component of your initial training process had to be replaced or tweaked heavily. Challenges we'll briefly cover: - Gone in 16 minutes: the importance of small-scale experiments. - Full throttle: is 100% GPU utilization enough? - Do you need a fancy framework? From single- to multi-GPU training. - Are SSDs fast enough? WebDataset brings a 10x improvement. - Does bigger always mean better? How to effortlessly scale AI models. - Clouds, enthusiasts, or clusters? How to hunt down GPUs. - Defending moats. How is a gaming 4090 different from an H100? Presented by Marcus Edel. #FOSDEM #WhisperSpeech #OpenSource #ML #AI
Comments