Enriching Source Code with Contextual Data for Code Completion Models Empirics скачать в хорошем качестве
Enriching Source Code with Contextual Data for Code Completion Models Empirics
2 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Enriching Source Code with Contextual Data for Code Completion Models Empirics в качестве 4k
У нас вы можете посмотреть бесплатно Enriching Source Code with Contextual Data for Code Completion Models Empirics или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Enriching Source Code with Contextual Data for Code Completion Models Empirics в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Enriching Source Code with Contextual Data for Code Completion Models Empirics
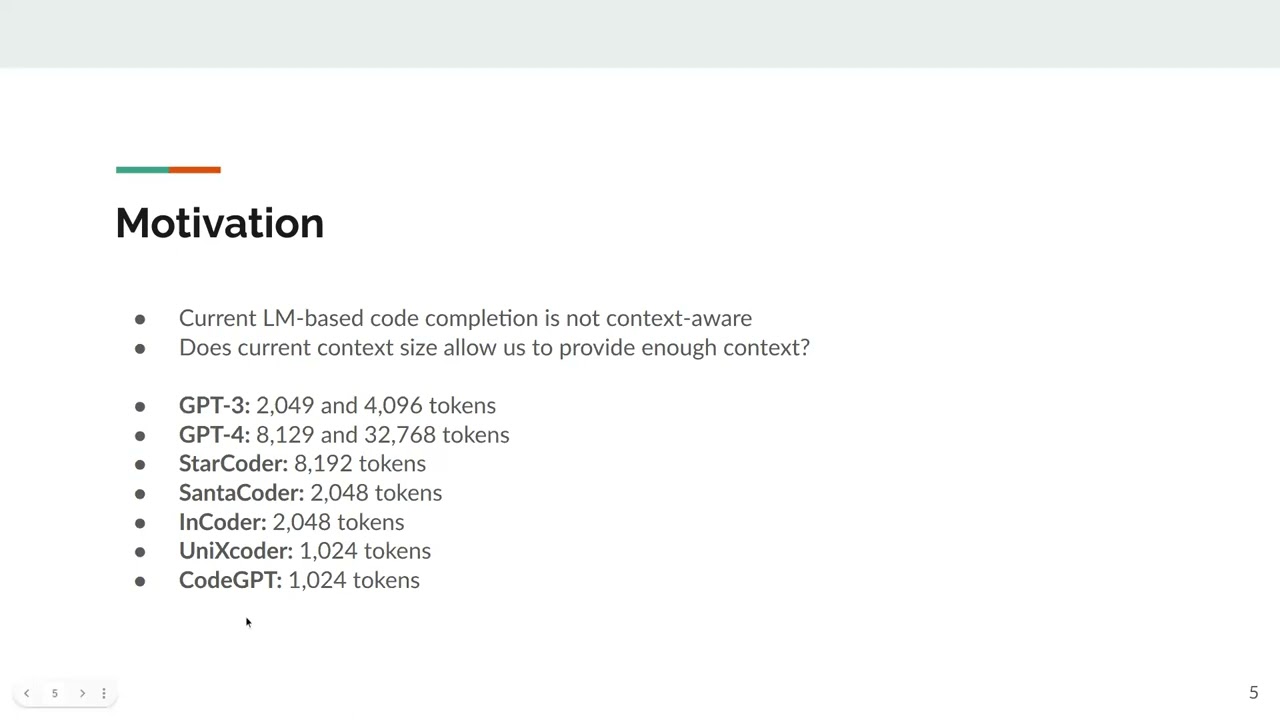
Transformer-based pre-trained models have recently achieved great results in solving many software engineering tasks including automatic code completion which is a staple in a developer's toolkit. While many have striven to improve the code-understanding abilities of such models, the opposite, making the code easier to understand, has not been properly investigated. In this talk, I will discuss our paper "Enriching Source Code with Contextual Data for Code Completion Models: An Empirical Study", in which we investigate the impact of type annotations and different types of code comments on the performance of various code completion models. We use a TypeScript dataset to create various versions of the same input with differing amounts of contextual information to test whether this information aids model performance. I will go into detail about our process and findings, and discuss potential future avenues to make code completion models more context-aware. Speaker -- Tim van Dam Tim van Dam is a master's student at the Technical University of Delft. Having researched the influence of contextual information on code completion performance during his bachelor's thesis, he now researches language models for code as a part-time student research assistant to supervisor Maliheh Izadi (SERG, TU Delft). Meetup Group: https://www.meetup.com/machine-learni...
Comments
-
 2 года назад
2 года назад
-
 1 год назад
1 год назад
-
 12 дней назад
12 дней назад
-
 2 года назад
2 года назад
-
 1 месяц назад
1 месяц назад
-
 6 месяцев назад
6 месяцев назад
-
 3 года назад
3 года назад
-
 3 дня назад
3 дня назад
-
 3 дня назад
3 дня назад
-
 20 часов назад
20 часов назад
-
 Трансляция закончилась 1 день назад
Трансляция закончилась 1 день назад
-
 7 дней назад
7 дней назад
-
 Трансляция закончилась 4 часа назад
Трансляция закончилась 4 часа назад
-
 9 дней назад
9 дней назад
-
 Трансляция закончилась 7 дней назад
Трансляция закончилась 7 дней назад
-
 4 часа назад
4 часа назад
-
 16 часов назад
16 часов назад
-
 7 дней назад
7 дней назад
-
 2 года назад
2 года назад
-
 1 день назад
1 день назад