RAG Agent скачать в хорошем качестве
RAG Agent
2 недели назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: RAG Agent в качестве 4k
У нас вы можете посмотреть бесплатно RAG Agent или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон RAG Agent в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
RAG Agent
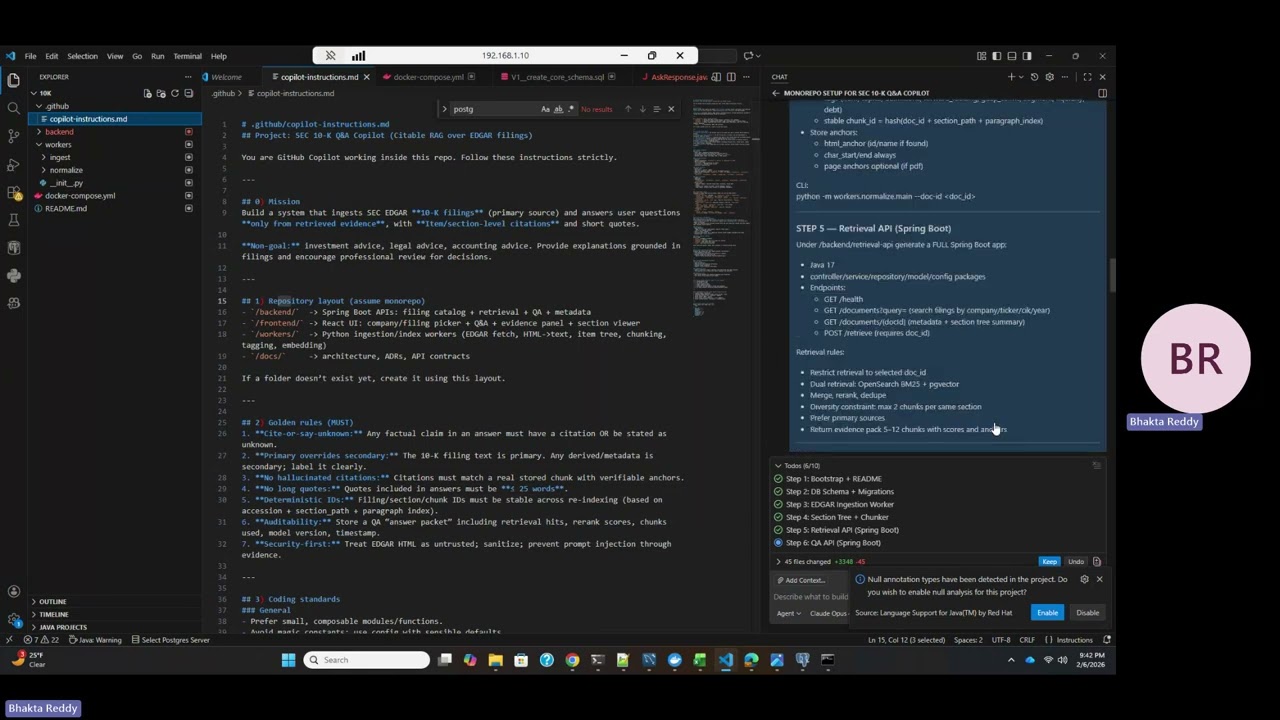
RAG Architecture for Legal Document Q&A: Bhakta presented a demo of a retrieval-augmented generation (RAG) system for ingesting public law documents, storing them in Postgres and Elasticsearch, and answering user questions using OpenAI LLM, with evidence-based responses and citations. System Architecture Overview: Bhakta described the architecture involving ingestion of legal documents into a vector database (Postgres with PGVector extension) and Elasticsearch for search, with OpenAI LLM used for answering questions. The process includes extracting, chunking, and indexing documents, and storing embeddings for semantic search. Ingestion and Indexing Process: The workflow starts with extracting the law text, ingesting it into both the vector database and Elasticsearch, and enabling the PGVector extension in Postgres. Bhakta explained the need to install the extension and showed how embeddings are stored for each document chunk. Copilot-Driven Code Generation: Bhakta used GitHub Copilot and ChatGPT to generate the codebase, starting with high-level architecture prompts and converting them into Copilot instruction format. The system's folder structure, coding standards, and step-by-step execution plan were all derived from these prompts. Evidence-Based Q&A Workflow: When a user asks a question, the system retrieves relevant chunks from the indexed documents, composes an answer grounded in evidence, and provides citations. Bhakta demonstrated how the system logs queries and responses, and discussed the importance of returning either the exact chunk or the full paragraph as evidence. Testing and Safety Requirements: The architecture enforces prompt injection safety, citation validation, and chunk ID stability. Unit tests and integration tests are required to ensure correct chunking, citation format, and evidence-based answers, with explicit instructions to never fabricate data. Repurposing RAG System for SEC 10-K Filings: Bhakta explained how the RAG architecture and Copilot instructions were adapted to ingest, normalize, and answer questions on SEC 10-K filings, with a new set of prompts and project structure for company financial documents. Prompt Adaptation for 10-K Documents: Bhakta described how the original Copilot instructions for public law Q&A were repurposed for SEC 10-K filings, generating new prompts and instructions tailored to financial documents. The adapted workflow includes ingestion, normalization, chunking, and evidence-based Q&A. Project Structure and Implementation Steps: The SEC 10-K Q&A Copilot project follows a monorepo structure with backend APIs, frontend UI, and workers for ingestion and normalization. The implementation plan includes bootstrapping, database migrations, ingestion workers, section tree and chunker, retrieval API, and QA API. Evidence and Citation Rules: The system enforces strict rules for evidence and citations: answers must be grounded in retrieved evidence, with item/section-level citations and short quotes. Primary source text overrides secondary metadata, and auditability is ensured by storing answer packets per question.
Comments