AngelSlim: A more accessible, comprehensive, and efficient toolkit for large model compression скачать в хорошем качестве
AngelSlim: A more accessible, comprehensive, and efficient toolkit for large model compression
13 часов назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: AngelSlim: A more accessible, comprehensive, and efficient toolkit for large model compression в качестве 4k
У нас вы можете посмотреть бесплатно AngelSlim: A more accessible, comprehensive, and efficient toolkit for large model compression или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон AngelSlim: A more accessible, comprehensive, and efficient toolkit for large model compression в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
AngelSlim: A more accessible, comprehensive, and efficient toolkit for large model compression
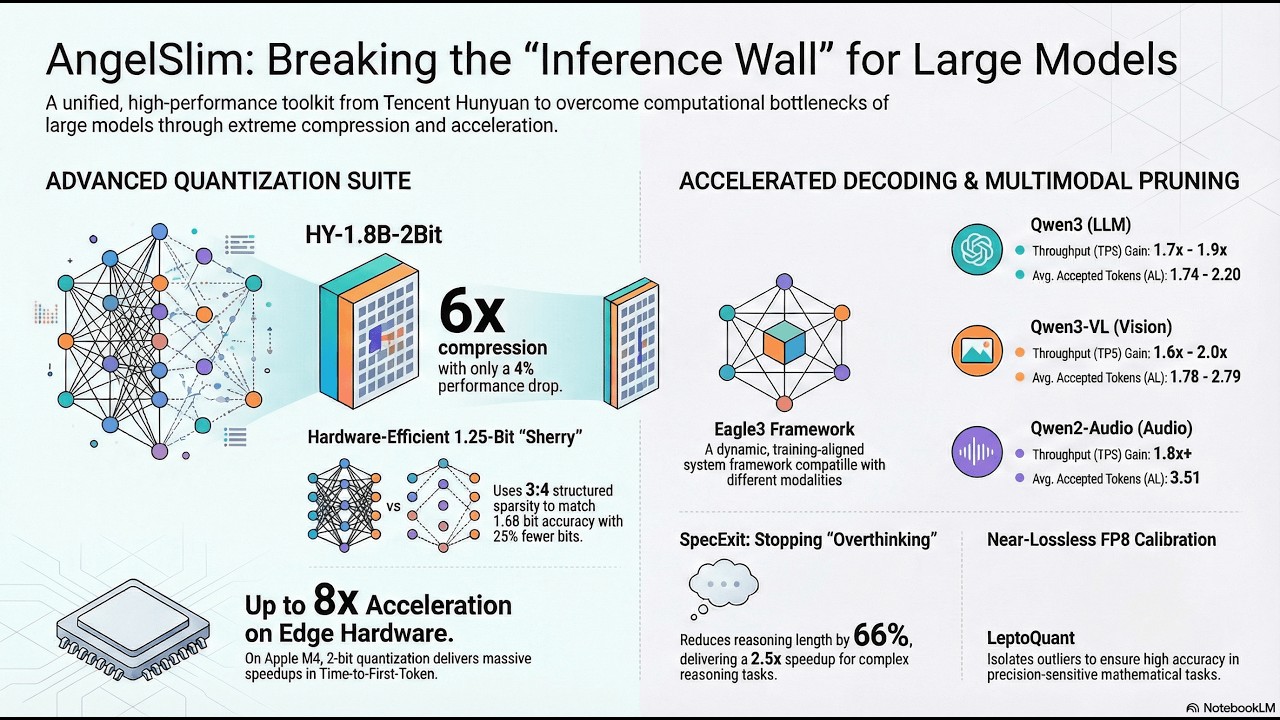
AngelSlim is a unified and comprehensive toolkit developed by the Tencent Hunyuan team for efficient compression and acceleration of large language and multimodal models. It aims to overcome the “Inference Wall” by integrating various cutting-edge optimization techniques into a single, cohesive pipeline, bridging the gap between theoretical compression and practical deployment. The toolkit features an advanced multi-tier quantization suite, including state-of-the-art FP8 and INT8 Post-Training Quantization (PTQ) and ultra-low-bit Quantization-Aware Training (QAT). Notably, AngelSlim introduces HY-1.8B-int2 as the first industrially viable 2-bit large model, alongside novel ternary quantization strategies like 1.58-Bit Tequila and 1.25-Bit Sherry. Beyond quantization, it incorporates a training-aligned speculative decoding framework, achieving significant throughput gains (1.8x-2.0x) for multimodal architectures. AngelSlim also provides a training-free sparse attention framework to reduce Time-to-First-Token (TTFT) in long-context scenarios. For multimodal models, specialized token pruning strategies like IDPruner (for vision tokens) and Samp (for audio tokens) are included. By integrating these diverse methods, AngelSlim enables hardware-aware optimization, allowing large models to operate at reduced computational cost without compromising performance or integrity. This holistic approach facilitates algorithm-focused research and tool-assisted deployment of compressed large models. #AngelSlim #ModelCompression #LLMs #MultimodalAI #Quantization #SpeculativeDecoding #SparseAttention #TokenPruning #AIOptimization #InferenceEfficiency paper - https://huggingface.co/AngelSlim/HY-1... subscribe - https://t.me/arxivpaper donations: USDT: 0xAA7B976c6A9A7ccC97A3B55B7fb353b6Cc8D1ef7 BTC: bc1q8972egrt38f5ye5klv3yye0996k2jjsz2zthpr ETH: 0xAA7B976c6A9A7ccC97A3B55B7fb353b6Cc8D1ef7 SOL: DXnz1nd6oVm7evDJk25Z2wFSstEH8mcA1dzWDCVjUj9e created with NotebookLM
Comments



















