Training LLM to play chess using Deepseek GRPO reinforcement learning скачать в хорошем качестве
Training LLM to play chess using Deepseek GRPO reinforcement learning
1 год назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Training LLM to play chess using Deepseek GRPO reinforcement learning в качестве 4k
У нас вы можете посмотреть бесплатно Training LLM to play chess using Deepseek GRPO reinforcement learning или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Training LLM to play chess using Deepseek GRPO reinforcement learning в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Training LLM to play chess using Deepseek GRPO reinforcement learning
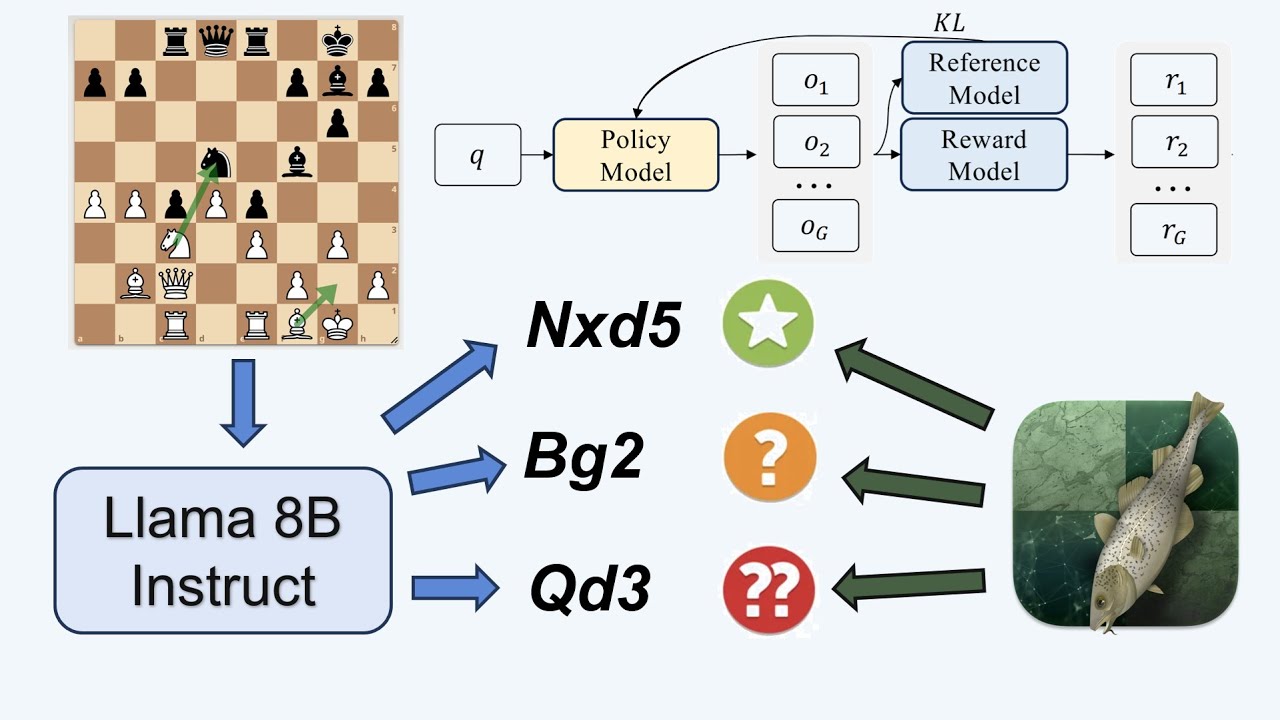
Try Voice Writer - speak your thoughts and let AI handle the grammar: https://voicewriter.io In this video, we see how popular LLMs like GPT-4o, o1 Reasoning, and DeepSeek R1 show some understanding of chess, they often fail to play legal moves. To address this, we train our own reasoning-focused chess LLM using the Group Relative Policy Optimization (GRPO) method introduced in DeepSeek R1. We walk through how GRPO differs from traditional PPO (Proximal Policy Optimization) and fine-tune LLaMA 8B and Qwen 7B using TRL (Transformers Reinforcement Learning) and Unsloth libraries - the results are surprising! Finally, we review some other chess-playing neural networks like Deepmind's Grandmaster Chess without Search and ChessGPT. 0:00 - Introduction 1:18 - Chess RL Strategy 3:51 - How well do the best LLMs understand chess? 6:41 - Picking a base model 8:31 - Unsloth and TRL libraries for RL with LLMs 9:38 - LoRA (Low Rank Adaptation) 10:55 - GSM8K reasoning example 12:06 - PPO (Proximal Policy Optimization) 14:12 - GRPO (Group Relative Policy Optimization) 17:15 - GRPO training results 18:11 - Analysis of results for LLaMA and Qwen 20:52 - Limitations of GRPO on small models 23:29 - Grandmaster-level chess without search 27:10 - ChessGPT and other LLMs that play chess
Comments