● Apache Kafka, Flink and Pinot: Open Source Powering Uber's Real-Time Data Stack скачать в хорошем качестве
● Apache Kafka, Flink and Pinot: Open Source Powering Uber's Real-Time Data Stack
1 год назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: ● Apache Kafka, Flink and Pinot: Open Source Powering Uber's Real-Time Data Stack в качестве 4k
У нас вы можете посмотреть бесплатно ● Apache Kafka, Flink and Pinot: Open Source Powering Uber's Real-Time Data Stack или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон ● Apache Kafka, Flink and Pinot: Open Source Powering Uber's Real-Time Data Stack в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
● Apache Kafka, Flink and Pinot: Open Source Powering Uber's Real-Time Data Stack
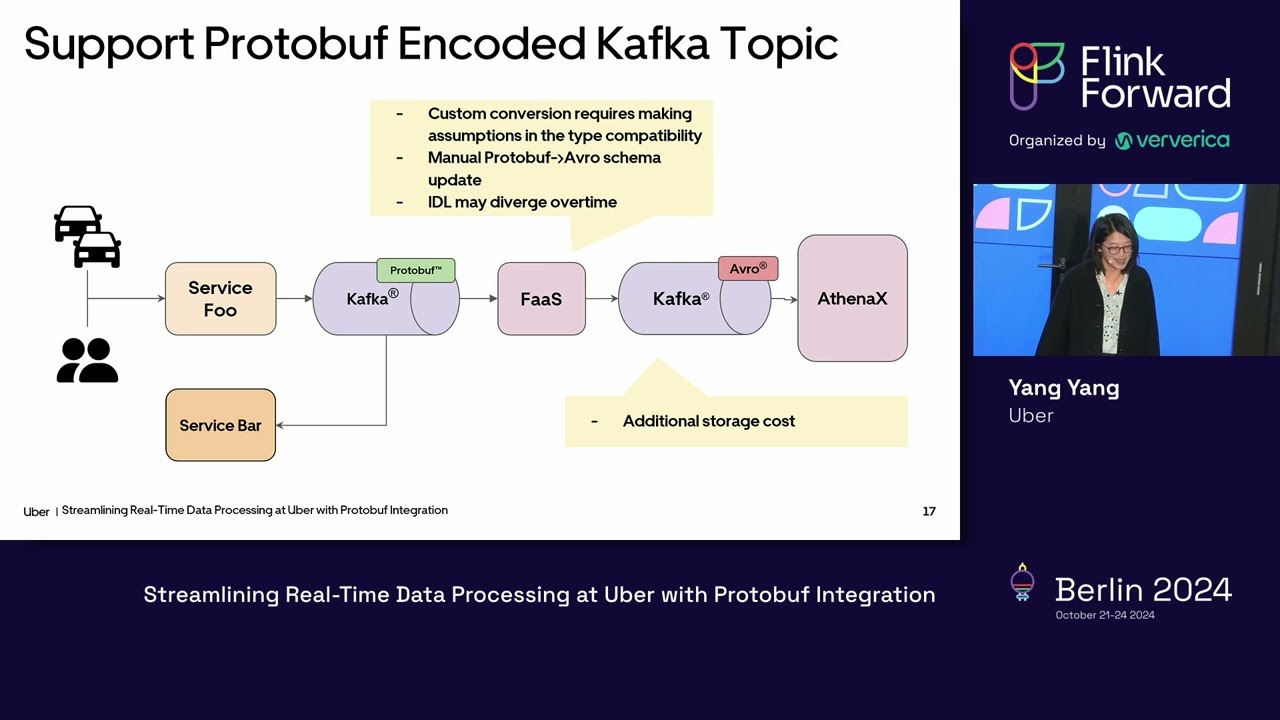
Building and scaling a real-time data infrastructure is a complex undertaking, fraught with challenges and valuable lessons. This episode takes a deep dive into Uber's journey, exploring the hurdles they encountered while managing petabytes of real-time data. We'll discuss the need for data consistency, availability, and freshness, the complexities of handling diverse use cases and user groups, and the constant need for system evolution. Tune in to learn from Uber's experiences and gain insights into building robust and scalable real-time data infrastructures. References: https://arxiv.org/pdf/2104.00087
Comments