V-JEPA 2.1: объяснение функции потерь при плотном прогнозировании и многомодальной токенизации. М... скачать в хорошем качестве
V-JEPA 2.1: объяснение функции потерь при плотном прогнозировании и многомодальной токенизации. М...
21 час назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: V-JEPA 2.1: объяснение функции потерь при плотном прогнозировании и многомодальной токенизации. М... в качестве 4k
У нас вы можете посмотреть бесплатно V-JEPA 2.1: объяснение функции потерь при плотном прогнозировании и многомодальной токенизации. М... или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон V-JEPA 2.1: объяснение функции потерь при плотном прогнозировании и многомодальной токенизации. М... в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
V-JEPA 2.1: объяснение функции потерь при плотном прогнозировании и многомодальной токенизации. М...
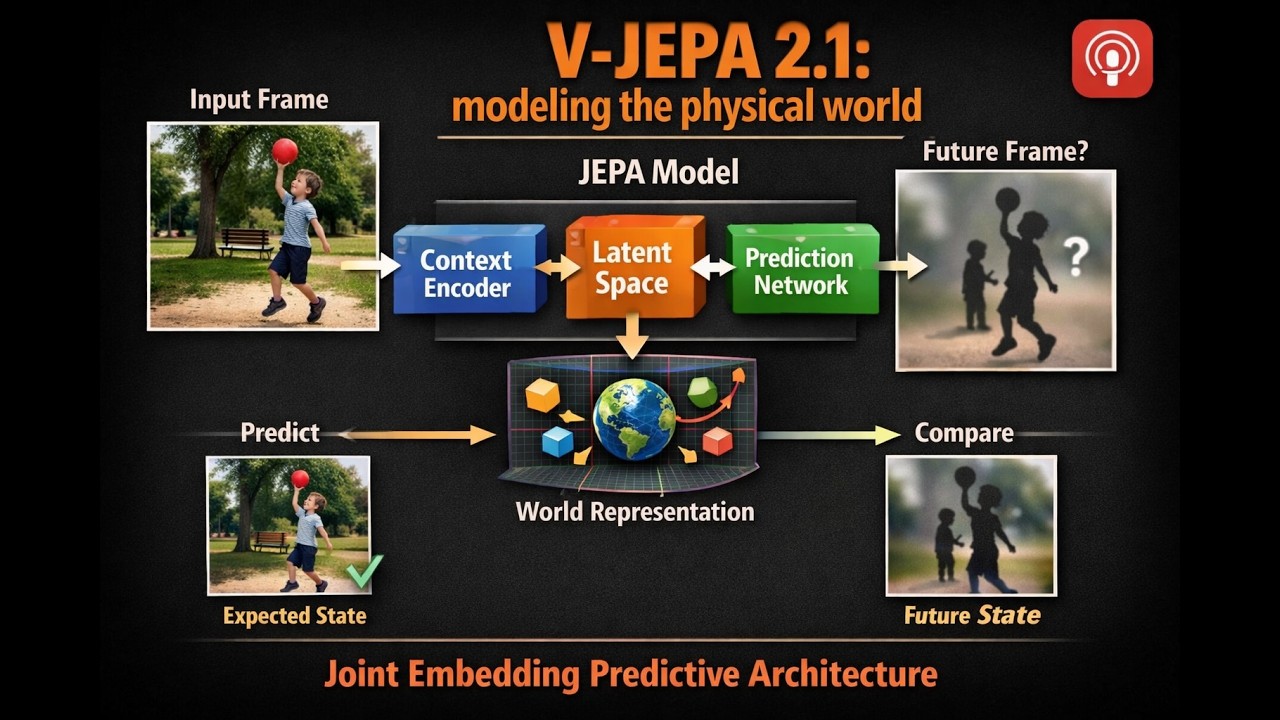
Мы часто думаем об ИИ как о чем-то, что «видит» изображения, но действительно ли он понимает пространство, на которое смотрит? В мире робототехники и компьютерного зрения существует огромная разница между идентификацией чашки и точным пониманием того, на каком расстоянии она находится, какова её форма и как она будет двигаться, если её коснуться. Сегодня мы рассмотрим огромный шаг вперед в том, как машины моделируют нашу физическую реальность. Мы разберем V-JEPA 2.1: Advancing Dense Visual Understanding and World Modeling (Усовершенствованное понимание плотной визуальной информации и моделирование мира). Разработанная исследователями из Meta и Университета Сарагосы, это не просто небольшое обновление — это фундаментальный сдвиг в том, как ИИ обучается посредством самообучения. Выходя за рамки простых меток и переходя к плотной предсказательной функции потерь и многомодальной токенизации, V-JEPA 2.1 учит машины предсказывать скрытую структуру самого мира. От монокулярной оценки глубины до роботизированного манипулирования без предварительного обучения, мы исследуем, как эта модель устанавливает новый золотой стандарт для искусственного восприятия. Что мы будем изучать: За пределами глобального обзора: Как «плотная функция потерь прогнозирования» позволяет модели понимать каждый пиксель и кадр, а не только «общую картину». Глубокое самообучение: Почему обучение нескольких слоев кодировщика создает более надежный «цифровой двойник» физического мира. Мультимодальный токенизатор: Секретный ингредиент, позволяющий V-JEPA обрабатывать изображения и видео с беспрецедентной эффективностью. От пикселей к роботам: Реальные результаты семантической сегментации и то, как эта технология дает роботам «пространственную интуицию», которой им не хватало.
Comments

![Как представить 10 измерений? [3Blue1Brown]](https://imager.clipsaver.ru/tCIARwH01Ac/max.jpg)








![Пожалуй, главное заблуждение об электричестве [Veritasium]](https://imager.clipsaver.ru/6Hv2GLtnf2c/max.jpg)






![Почему взрываются батарейки и аккумуляторы? [Veritasium]](https://imager.clipsaver.ru/a3-3R9zwyGY/max.jpg)

![[Think LLM]Трансформеры в деконструкции: масштабные активации, источники внимания и артефакты дон...](https://imager.clipsaver.ru/ncnN0ikSobc/max.jpg)