Transformer Mini-Experiment (Pre-trained) | Global Context, Sequence Length & Compute скачать в хорошем качестве
Transformer Mini-Experiment (Pre-trained) | Global Context, Sequence Length & Compute
13 часов назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Transformer Mini-Experiment (Pre-trained) | Global Context, Sequence Length & Compute в качестве 4k
У нас вы можете посмотреть бесплатно Transformer Mini-Experiment (Pre-trained) | Global Context, Sequence Length & Compute или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Transformer Mini-Experiment (Pre-trained) | Global Context, Sequence Length & Compute в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Transformer Mini-Experiment (Pre-trained) | Global Context, Sequence Length & Compute
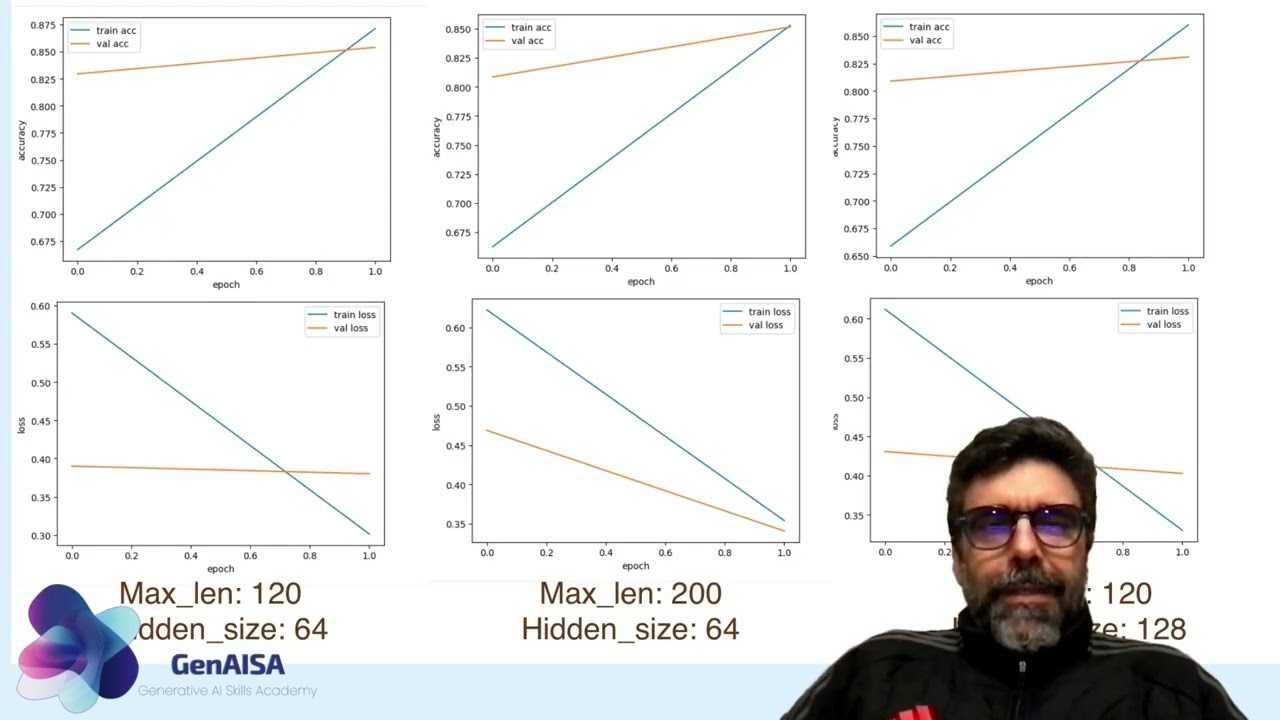
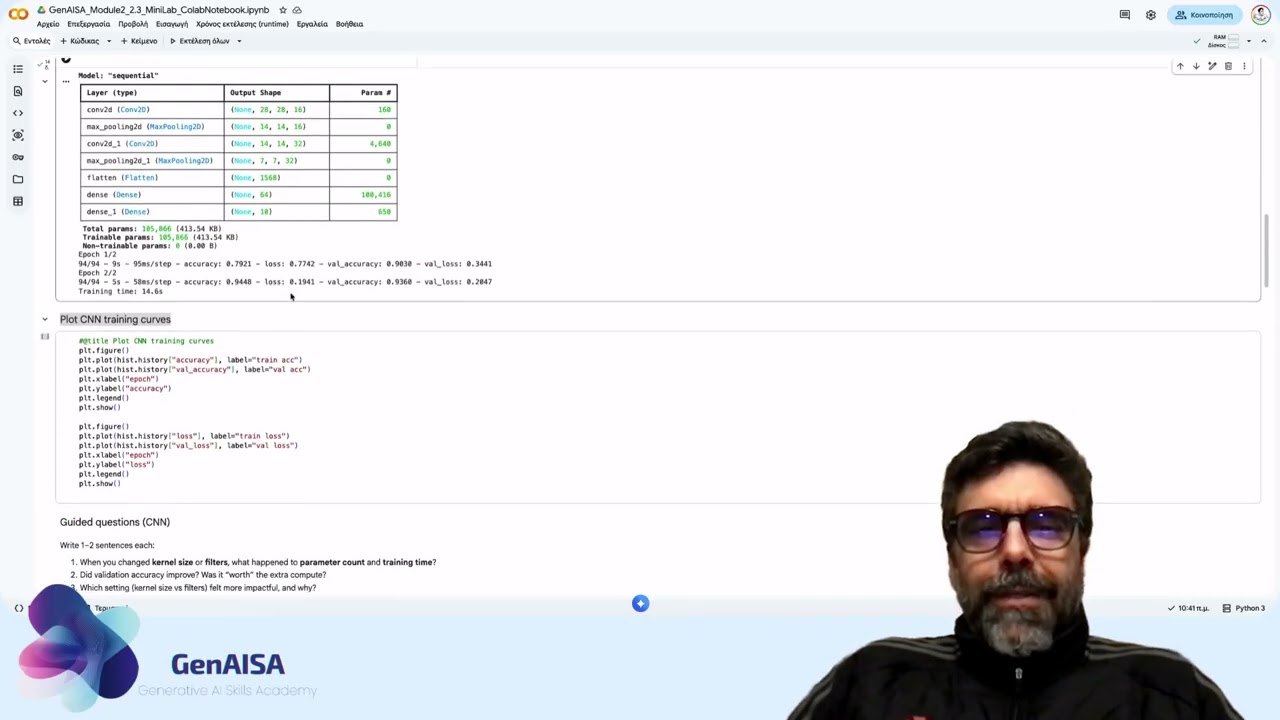
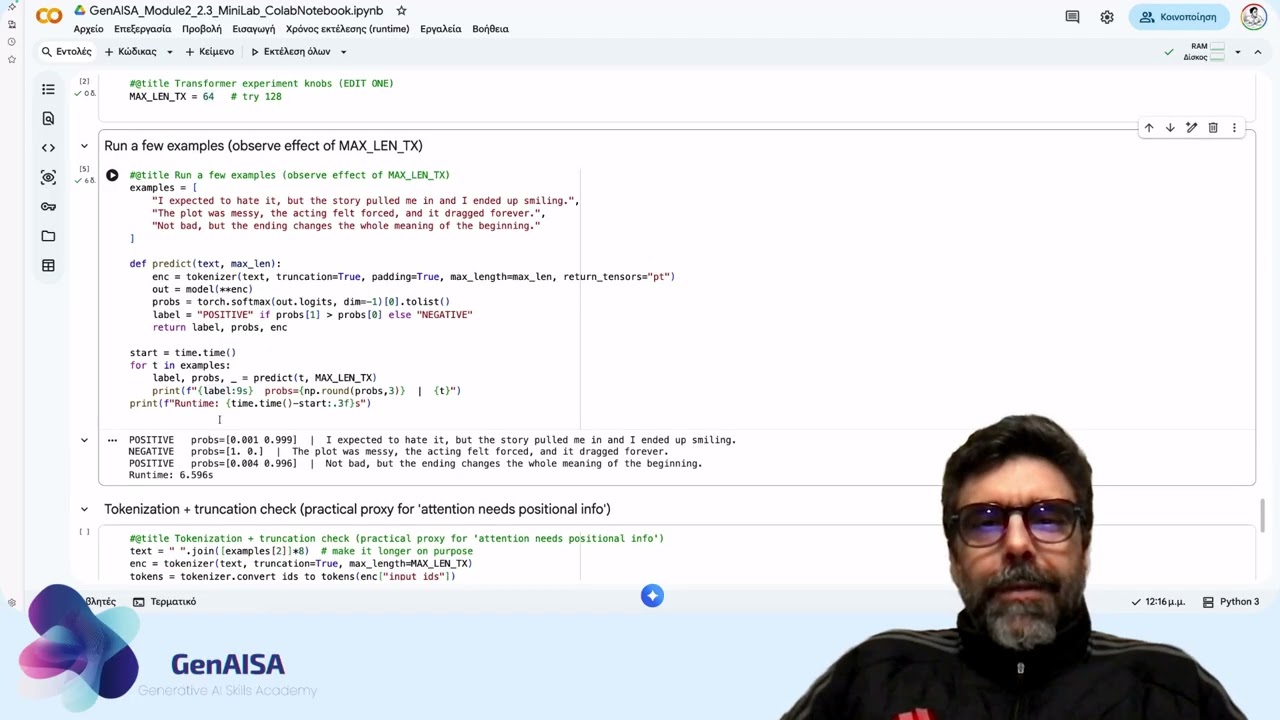
In this video, we run a hands-on mini-experiment with a pre-trained Transformer (DistilBERT) inside Google Colab. Instead of training a model, we focus on inference, global context, and architectural trade-offs. What you’ll see: How to load a pre-trained Transformer for sentiment classification How max sequence length affects tokenization and truncation Why longer context increases compute How attention relates to global context Why attention is not a perfect explanation When longer context changes predictions — and when it doesn’t We compare different sequence lengths (e.g., 64 vs 128 tokens) and observe: Prediction labels Confidence scores Runtime differences Truncation effects This experiment connects directly to: Locality (CNNs) Memory constraints (RNNs) Global context and compute trade-offs (Transformers) After watching, complete the 2.3.5 Lab Reflection: What surprised you? Where did theory appear in practice? Under real constraints, which architecture would you choose and why? This is where experimentation turns into engineering judgment. GenAISA project funded by the European Union. Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the European Education and Culture Executive Agency (EACEA). Neither the European Union nor EACEA can be held responsible for them.
Comments