Master LLM Prompt Caching: The Secret to Faster & Cheaper AI Apps with same LLM Model скачать в хорошем качестве
Master LLM Prompt Caching: The Secret to Faster & Cheaper AI Apps with same LLM Model
1 месяц назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Master LLM Prompt Caching: The Secret to Faster & Cheaper AI Apps with same LLM Model в качестве 4k
У нас вы можете посмотреть бесплатно Master LLM Prompt Caching: The Secret to Faster & Cheaper AI Apps with same LLM Model или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Master LLM Prompt Caching: The Secret to Faster & Cheaper AI Apps with same LLM Model в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Master LLM Prompt Caching: The Secret to Faster & Cheaper AI Apps with same LLM Model
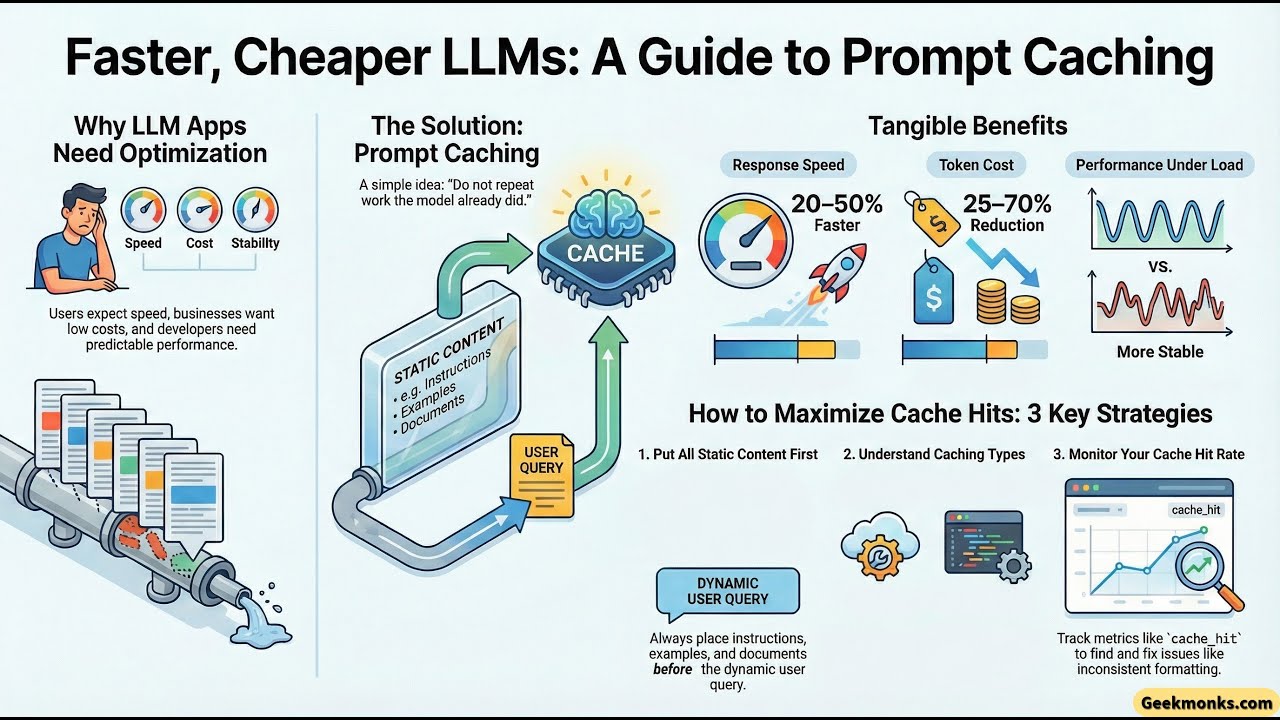
Check our website for in depth content. https://geekmonks.com/llm-eng/llm-pro... Are you looking to optimize your AI applications for production? In this video, we deep dive into Prompt Caching, a game-changing optimization technique that makes LLM apps faster, cheaper, and smarter without changing the underlying model. What is Prompt Caching? At its core, prompt caching is based on a simple idea: “Do not repeat work the model already did”. By identifying and storing the "static" parts of your prompts—such as system instructions, long documents, or conversation history—the model avoids re-processing the same data for every request. In this video, you will learn: • The Massive Benefits: See how caching leads to 20–50% faster responses and a staggering 25–70% reduction in costs. • How it Works (The Technical Side): We explain how LLMs compute internal Key-Value (KV) states—essentially the model's "memory" of a prompt—and store them for instant retrieval. • Implicit vs. Explicit Caching: ◦ Implicit (Provider-Side): Automatic detection by providers like OpenAI and Anthropic, requiring zero code changes. ◦ Explicit (Developer-Side): Advanced control used by Google Gemini and Amazon Bedrock, ideal for very long documents and RAG pipelines. • Design for Success: Learn the #1 rule—always put static content first—and how even a single extra space can break your "exact prefix match" and ruin your cache hit rate. Why it Matters for Developers: As applications move into production, performance and predictability are key. Whether you are building complex RAG systems, AI agents, or long reasoning pipelines, prompt caching is the key to maintaining stability under load while keeping your budget in check. #AI #LLM #PromptEngineering #GenerativeAI #PromptCaching #MachineLearning #AICostOptimization #SoftwareEngineering #Geekmonks #GPT4 #GeminiAI #RAG #TechTutorials
Comments
-
 1 месяц назад
1 месяц назад
-
 2 месяца назад
2 месяца назад
-
 2 месяца назад
2 месяца назад
-
 2 месяца назад
2 месяца назад
-
 2 недели назад
2 недели назад
-
 1 месяц назад
1 месяц назад
-
![🔴 EXPRESS BIEDRZYCKIEJ | ARKADIUSZ MYRCHA, PROF. MARCIN MATCZAK [NA ŻYWO]](https://imager.clipsaver.ru/VjhtZK5XJnU/max.jpg) Трансляция закончилась 3 часа назад
Трансляция закончилась 3 часа назад
-
 3 месяца назад
3 месяца назад
-
 1 месяц назад
1 месяц назад
-
 2 месяца назад
2 месяца назад
-
 1 месяц назад
1 месяц назад
-
 5 месяцев назад
5 месяцев назад
-
 2 года назад
2 года назад
-
 6 дней назад
6 дней назад
-
 2 года назад
2 года назад
-
 1 месяц назад
1 месяц назад
-
 4 месяца назад
4 месяца назад
-
 3 месяца назад
3 месяца назад
-
 1 месяц назад
1 месяц назад
-
 4 недели назад
4 недели назад