NumericalPrecision or BF16 and BF32 in LLM models скачать в хорошем качестве
NumericalPrecision or BF16 and BF32 in LLM models
1 год назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: NumericalPrecision or BF16 and BF32 in LLM models в качестве 4k
У нас вы можете посмотреть бесплатно NumericalPrecision or BF16 and BF32 in LLM models или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон NumericalPrecision or BF16 and BF32 in LLM models в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
NumericalPrecision or BF16 and BF32 in LLM models
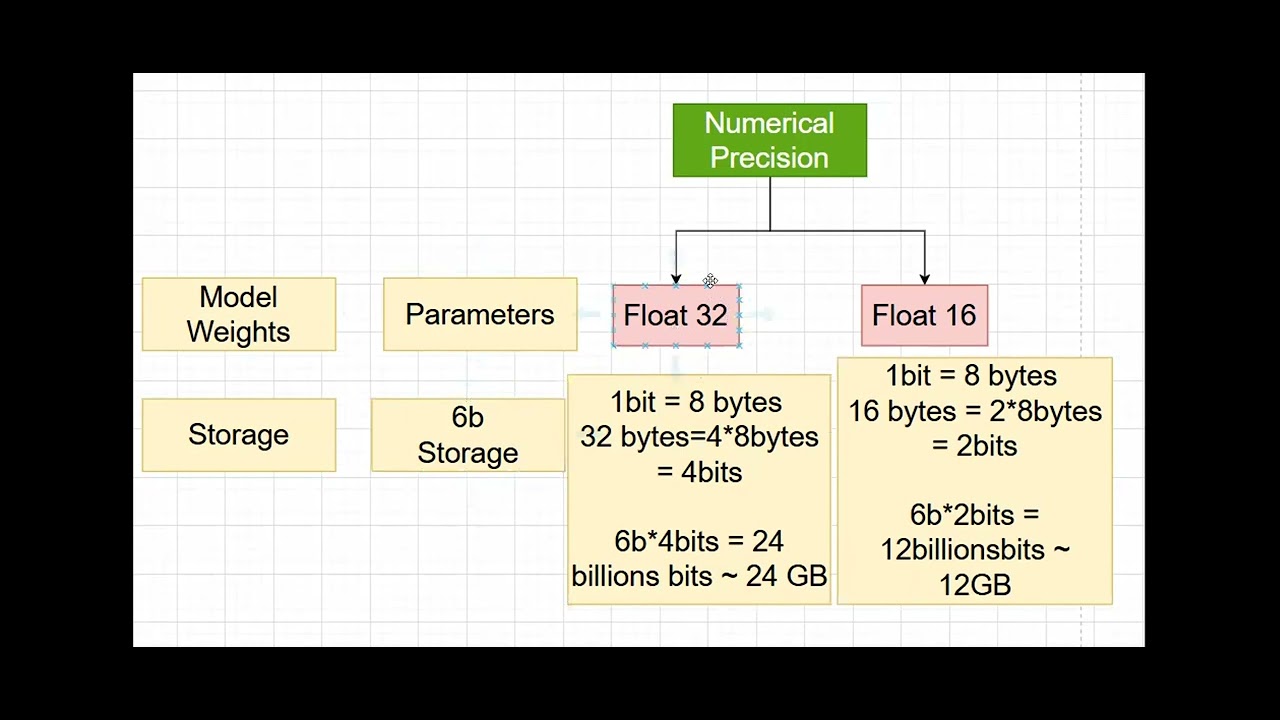
Playlist Video Title Suggestions: 1. *"Understanding Numerical Precision in LLM Models: BF16 vs BF32 Explained"* 2. *"BF16 and BF32 in LLM Models: A Deep Dive into Numerical Precision"* 3. *"Numerical Precision in Large Language Models: BF16, BF32 & Performance Insights"* Playlist Video Description: Explore the crucial role of numerical precision in large language models (LLMs) and how it impacts model performance, efficiency, and scalability. This playlist breaks down the differences between BF16 (Brain Floating Point 16) and BF32, examining their significance in LLMs and why these precision formats are essential for achieving high performance in deep learning applications. Whether you're working with AI, ML, or neural networks, understanding numerical precision is vital for optimizing model accuracy and computational efficiency. Dive into topics like precision trade-offs, performance benchmarking, and use cases for BF16 and BF32 in real-world LLM applications. Keywords: Numerical precision, BF16, BF32, large language models, LLM precision, neural network performance, Brain Floating Point 16, model precision in AI, deep learning precision, BF16 vs BF32, AI model efficiency, floating point formats, LLM performance optimization, precision in ML models, BF16 benefits, BF32 limitations, model accuracy in AI, high-performance computing, neural network precision, AI model scalability, deep learning applications, LLM model precision, AI performance benchmarking, precision trade-offs in ML, BF16 floating point, BF32 floating point, computational efficiency, model optimization, AI model precision, neural network scaling, precision in deep learning, high-performance AI, BF16 vs FP32, LLM architecture, training LLMs with BF16, floating point optimization Tags: Numerical precision, BF16, BF32, large language models, LLM precision, neural network performance, Brain Floating Point 16, model precision in AI, deep learning precision, BF16 vs BF32, AI model efficiency, floating point formats, LLM performance optimization, precision in ML models, BF16 benefits, BF32 limitations, model accuracy in AI, high-performance computing, neural network precision, AI model scalability, deep learning applications, LLM model precision, AI performance benchmarking, precision trade-offs in ML, BF16 floating point, BF32 floating point, computational efficiency, model optimization, AI model precision, neural network scaling, precision in deep learning, high-performance AI, BF16 vs FP32, LLM architecture, training LLMs with BF16, floating point optimization Hashtags: #NumericalPrecision #BF16 #BF32 #LargeLanguageModels #LLMPrecision #NeuralNetworkPerformance #BrainFloatingPoint #DeepLearning #AIModelOptimization #ModelPrecision #HighPerformanceAI #PrecisionInML #FloatingPointFormats #LLMOptimization #DeepLearningPrecision #ModelAccuracy #MachineLearning #AIResearch #NeuralNetworks #PrecisionTradeOffs #ModelEfficiency #MLPrecision #LLMTraining
Comments