Learning Near-Optimal Intrusion Response for Large-Scale IT Infrastructures via Decomposition скачать в хорошем качестве
Learning Near-Optimal Intrusion Response for Large-Scale IT Infrastructures via Decomposition
2 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Learning Near-Optimal Intrusion Response for Large-Scale IT Infrastructures via Decomposition в качестве 4k
У нас вы можете посмотреть бесплатно Learning Near-Optimal Intrusion Response for Large-Scale IT Infrastructures via Decomposition или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Learning Near-Optimal Intrusion Response for Large-Scale IT Infrastructures via Decomposition в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Learning Near-Optimal Intrusion Response for Large-Scale IT Infrastructures via Decomposition
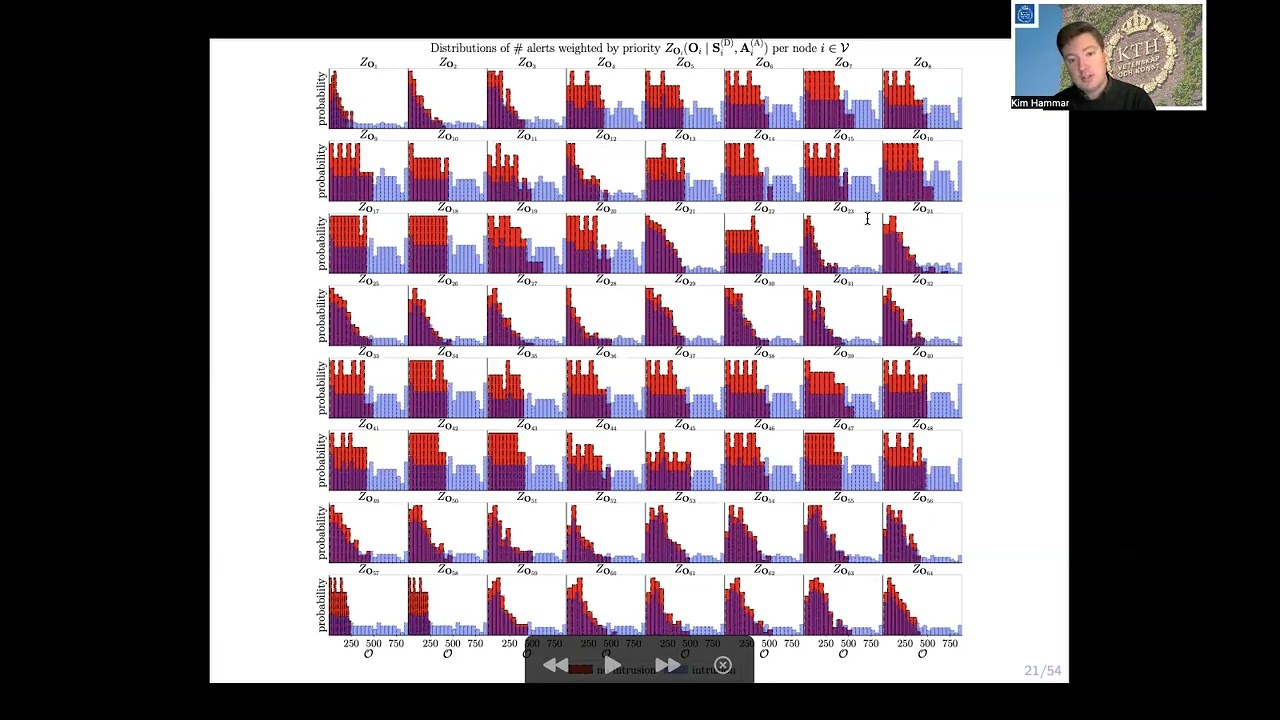
We study automated intrusion response and formulate the interaction between an attacker and a defender on an IT infrastructure as a stochastic game where attack and defense strategies evolve through reinforcement learning and self-play. Direct application of reinforcement learning to any non-trivial instantiation of this game is impractical due to the exponential growth of the state and action spaces with the number of components in the infrastructure. We propose a decompositional approach to deal with this challenge and prove that under assumptions generally met in practice the game decomposes into a) additive subgames on the workflow-level that can be optimized independently; and b) subgames on the component-level that satisfy the optimal substructure property. We further show that the optimal defender strategies on the component-level exhibit threshold structures. To solve the decomposed game we develop Decompositional Fictitious Self-Play (DFSP), an efficient fictitious self-play algorithm that learns Nash equilibria through stochastic approximation. We show that DFSP outperforms a state-of-the-art algorithm for our use case. To evaluate the learned strategies, we deploy them in a a virtual IT infrastructure in which we run real network intrusions and real response actions. From our experimental investigation we conclude that our approach can produce effective defender strategies for a practical IT infrastructure.
Comments
-
 1 год назад
1 год назад
-

-
 3 недели назад
3 недели назад
-
 Трансляция закончилась 15 часов назад
Трансляция закончилась 15 часов назад
-
 10 дней назад
10 дней назад
-
 14 часов назад
14 часов назад
-
 18 часов назад
18 часов назад
-
 15 часов назад
15 часов назад
-
 4 года назад
4 года назад
-

-
 11 дней назад
11 дней назад
-
 Трансляция закончилась 1 год назад
Трансляция закончилась 1 год назад
-
 1 день назад
1 день назад
-
 18 часов назад
18 часов назад
-

-
 2 года назад
2 года назад
-
 1 год назад
1 год назад
-
 3 года назад
3 года назад
-
 18 часов назад
18 часов назад
-
 Трансляция закончилась 12 часов назад
Трансляция закончилась 12 часов назад