DeepSeek-OCR: Contexts Optical Compression скачать в хорошем качестве
DeepSeek-OCR: Contexts Optical Compression
3 месяца назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: DeepSeek-OCR: Contexts Optical Compression в качестве 4k
У нас вы можете посмотреть бесплатно DeepSeek-OCR: Contexts Optical Compression или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон DeepSeek-OCR: Contexts Optical Compression в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
DeepSeek-OCR: Contexts Optical Compression
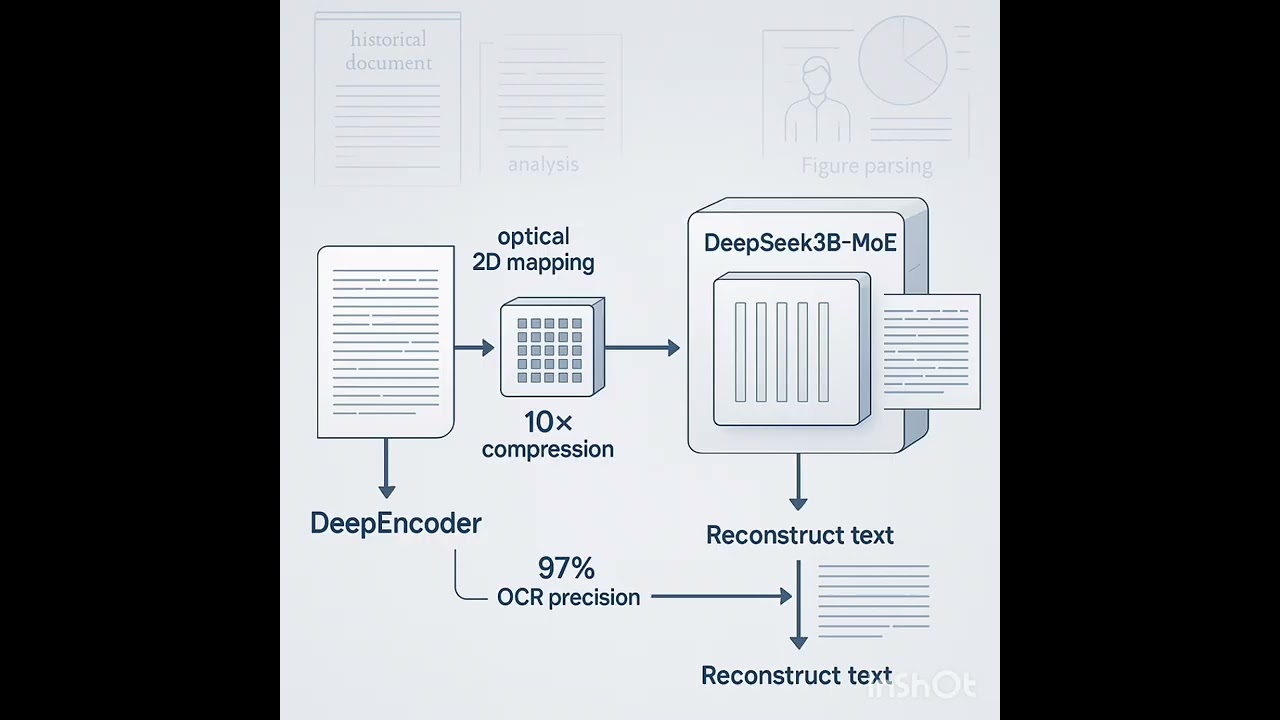
The paper introduces DeepSeek-OCR, a vision-language model designed to explore the concept of contexts optical compression, which uses visual modality to efficiently compress long textual contexts for Large Language Models (LLMs). DeepSeek-OCR consists of the DeepEncoder and a DeepSeek3B-MoE decoder, with the DeepEncoder specifically engineered to achieve high compression ratios while managing a low number of vision tokens. Experiments on benchmarks like Fox and OmniDocBench demonstrate that the model can maintain high Optical Character Recognition (OCR) precision, even at compression ratios up to 10×, showcasing its potential to mitigate the computational challenges of processing lengthy text sequences. Beyond its theoretical research value in memory forgetting mechanisms and context compression, DeepSeek-OCR proves highly practical, achieving state-of-the-art OCR performance with fewer vision tokens than competitors and capable of generating substantial training data for other LLMs and VLMs.
Comments



















