From Chaos to Control Mastering ML Reproducibility at scale скачать в хорошем качестве
From Chaos to Control Mastering ML Reproducibility at scale
1 год назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: From Chaos to Control Mastering ML Reproducibility at scale в качестве 4k
У нас вы можете посмотреть бесплатно From Chaos to Control Mastering ML Reproducibility at scale или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон From Chaos to Control Mastering ML Reproducibility at scale в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
From Chaos to Control Mastering ML Reproducibility at scale
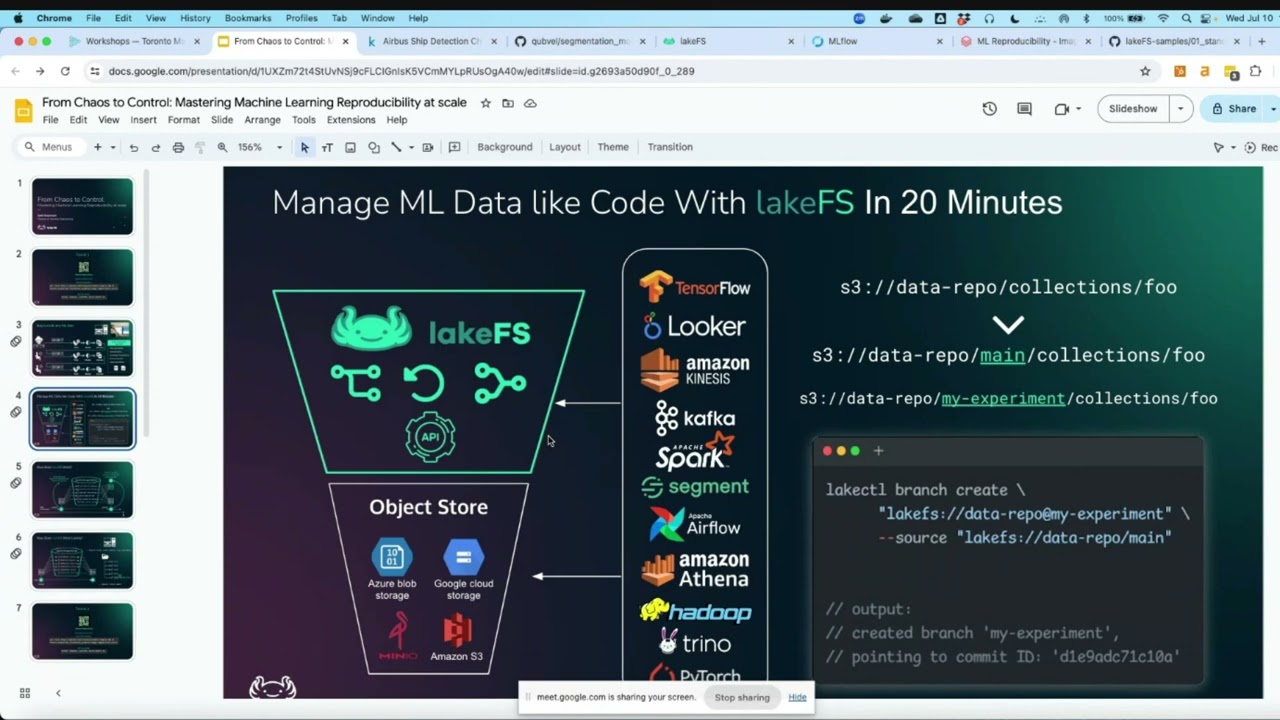
Speaker: Amit Kesarwani, Director, Solution Engineering, LakeFS Abstract: Machine learning workflows are not linear, where experimentation is an iterative & repetitive to and fro process between different components. What this often involves is experimentation with different data labeling techniques, data cleaning, preprocessing and feature selection methods during model training, just to arrive at an accurate model. Quality ML at scale is only possible when we can reproduce a specific iteration of the ML experiment–and this is where data is key. This means capturing the version of training data, ML code and model artifacts at each iteration is mandatory. However, to efficiently version ML experiments without duplicating code, data and models, data versioning tools are critical. Open-source tools like lakeFS make it possible to version all components of ML experiments without the need to keep multiple copies, and as an added benefit, save you storage costs as well.
Comments
















![Как внимание стало настолько эффективным [GQA/MLA/DSA]](https://imager.clipsaver.ru/Y-o545eYjXM/max.jpg)

![Как происходит модернизация остаточных соединений [mHC]](https://imager.clipsaver.ru/jYn_1PpRzxI/max.jpg)
