#6.3 A3C (Asynchronous Advantage Actor-Critic) (ејәеҢ–еӯҰд№ Reinforcement Learning ж•ҷеӯҰ) СҒРәР°СҮР°СӮСҢ РІ С…РҫСҖРҫСҲРөРј РәР°СҮРөСҒСӮРІРө
#6.3 A3C (Asynchronous Advantage Actor-Critic) (ејәеҢ–еӯҰд№ Reinforcement Learning ж•ҷеӯҰ)
8 Р»РөСӮ РҪазаРҙ
РқРө СғРҙР°РөСӮСҒСҸ загСҖСғР·РёСӮСҢ Youtube-РҝР»РөРөСҖ. РҹСҖРҫРІРөСҖСҢСӮРө РұР»РҫРәРёСҖРҫРІРәСғ Youtube РІ РІР°СҲРөР№ СҒРөСӮРё.
РҹРҫРІСӮРҫСҖСҸРөРј РҝРҫРҝСӢСӮРәСғ...
РҹРҫРІСӮРҫСҖСҸРөРј РҝРҫРҝСӢСӮРәСғ...

РЎРәР°СҮР°СӮСҢ РІРёРҙРөРҫ СҒ СҺСӮСғРұ РҝРҫ СҒСҒСӢР»РәРө или СҒРјРҫСӮСҖРөСӮСҢ РұРөР· РұР»РҫРәРёСҖРҫРІРҫРә РҪР° СҒайСӮРө: #6.3 A3C (Asynchronous Advantage Actor-Critic) (ејәеҢ–еӯҰд№ Reinforcement Learning ж•ҷеӯҰ) РІ РәР°СҮРөСҒСӮРІРө 4k
РЈ РҪР°СҒ РІСӢ РјРҫР¶РөСӮРө РҝРҫСҒРјРҫСӮСҖРөСӮСҢ РұРөСҒРҝлаСӮРҪРҫ #6.3 A3C (Asynchronous Advantage Actor-Critic) (ејәеҢ–еӯҰд№ Reinforcement Learning ж•ҷеӯҰ) или СҒРәР°СҮР°СӮСҢ РІ РјР°РәСҒималСҢРҪРҫРј РҙРҫСҒСӮСғРҝРҪРҫРј РәР°СҮРөСҒСӮРІРө, РІРёРҙРөРҫ РәРҫСӮРҫСҖРҫРө РұСӢР»Рҫ загСҖСғР¶РөРҪРҫ РҪР° СҺСӮСғРұ. ДлСҸ загСҖСғР·РәРё РІСӢРұРөСҖРёСӮРө РІР°СҖРёР°РҪСӮ РёР· С„РҫСҖРјСӢ РҪРёР¶Рө:
-
РҳРҪС„РҫСҖРјР°СҶРёСҸ РҝРҫ загСҖСғР·РәРө:
РЎРәР°СҮР°СӮСҢ mp3 СҒ СҺСӮСғРұР° РҫСӮРҙРөР»СҢРҪСӢРј файлРҫРј. Р‘РөСҒРҝлаСӮРҪСӢР№ СҖРёРҪРіСӮРҫРҪ #6.3 A3C (Asynchronous Advantage Actor-Critic) (ејәеҢ–еӯҰд№ Reinforcement Learning ж•ҷеӯҰ) РІ С„РҫСҖРјР°СӮРө MP3:
Р•СҒли РәРҪРҫРҝРәРё СҒРәР°СҮРёРІР°РҪРёСҸ РҪРө
загСҖСғзилиСҒСҢ
РқРҗР–РңРҳРўР• ЗДЕСЬ или РҫРұРҪРҫРІРёСӮРө СҒСӮСҖР°РҪРёСҶСғ
Р•СҒли РІРҫР·РҪРёРәР°СҺСӮ РҝСҖРҫРұР»РөРјСӢ СҒРҫ СҒРәР°СҮРёРІР°РҪРёРөРј РІРёРҙРөРҫ, РҝРҫжалСғР№СҒСӮР° РҪР°РҝРёСҲРёСӮРө РІ РҝРҫРҙРҙРөСҖР¶РәСғ РҝРҫ Р°РҙСҖРөСҒСғ РІРҪРёР·Сғ
СҒСӮСҖР°РҪРёСҶСӢ.
РЎРҝР°СҒРёРұРҫ Р·Р° РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРө СҒРөСҖРІРёСҒР° ClipSaver.ru
#6.3 A3C (Asynchronous Advantage Actor-Critic) (ејәеҢ–еӯҰд№ Reinforcement Learning ж•ҷеӯҰ)
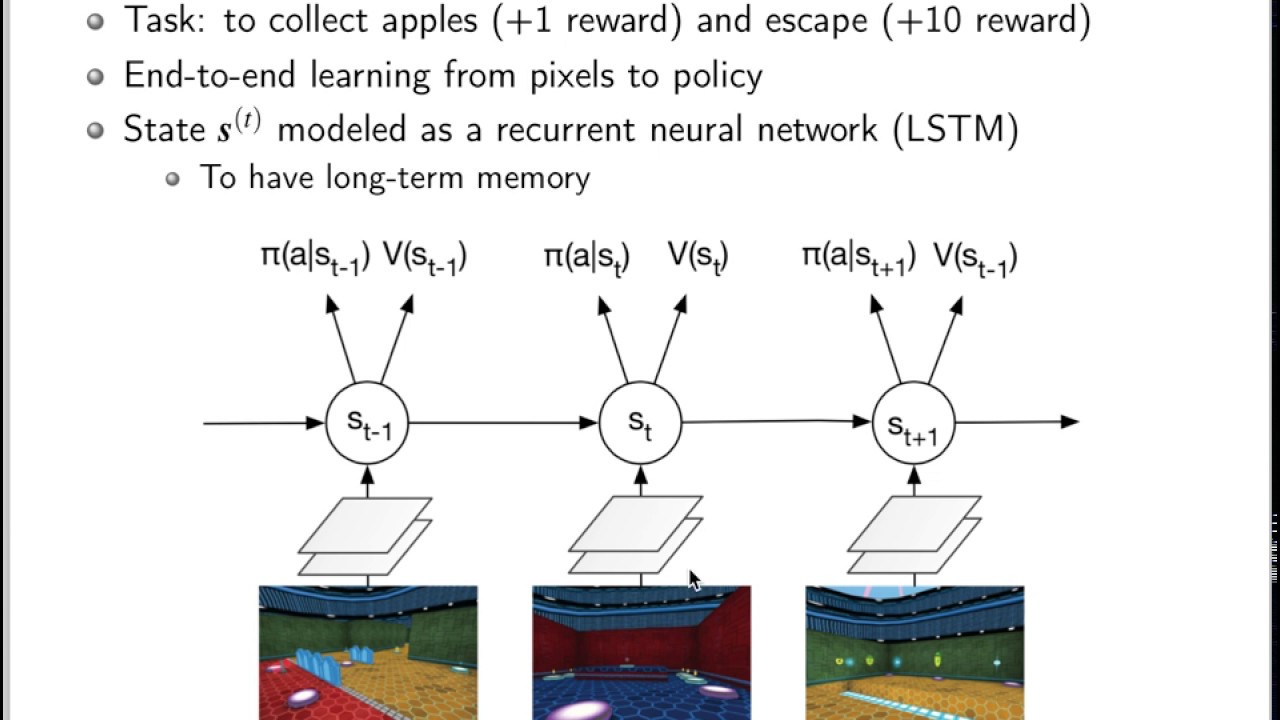
Google DeepMind жҸҗеҮәзҡ„дёҖз§Қи§ЈеҶі Actor-Critic дёҚ收ж•ӣй—®йўҳзҡ„з®—жі•. е®ғдјҡеҲӣе»әеӨҡдёӘ并иЎҢзҡ„зҺҜеўғ, и®©еӨҡдёӘжӢҘжңүеүҜз»“жһ„зҡ„ agent еҗҢж—¶еңЁиҝҷдәӣ并иЎҢзҺҜеўғдёҠжӣҙж–°дё»з»“жһ„дёӯзҡ„еҸӮж•°. 并иЎҢдёӯзҡ„ agent 们дә’дёҚе№Іжү°, иҖҢдё»з»“жһ„зҡ„еҸӮж•°жӣҙж–°еҸ—еҲ°еүҜз»“жһ„жҸҗдәӨжӣҙж–°зҡ„дёҚиҝһз»ӯжҖ§е№Іжү°, жүҖд»Ҙжӣҙж–°зҡ„зӣёе…іжҖ§иў«йҷҚдҪҺ, 收ж•ӣжҖ§жҸҗй«ҳ. иҜҰз»Ҷзҡ„ж–Үеӯ—ж•ҷзЁӢ: https://morvanzhou.github.io/tutorial... If you like this, please like my code on Github as well. Code: https://github.com/MorvanZhou/Reinfor...
Comments
-
 8 Р»РөСӮ РҪазаРҙ
8 Р»РөСӮ РҪазаРҙ
-
 1 РіРҫРҙ РҪазаРҙ
1 РіРҫРҙ РҪазаРҙ
-
 1 РіРҫРҙ РҪазаРҙ
1 РіРҫРҙ РҪазаРҙ
-
 7 Р»РөСӮ РҪазаРҙ
7 Р»РөСӮ РҪазаРҙ
-
 6 Р»РөСӮ РҪазаРҙ
6 Р»РөСӮ РҪазаРҙ
-
 5 Р»РөСӮ РҪазаРҙ
5 Р»РөСӮ РҪазаРҙ
-
 2 РҙРҪСҸ РҪазаРҙ
2 РҙРҪСҸ РҪазаРҙ
-
 1 РҙРөРҪСҢ РҪазаРҙ
1 РҙРөРҪСҢ РҪазаРҙ
-
 3 РҙРҪСҸ РҪазаРҙ
3 РҙРҪСҸ РҪазаРҙ
-
 4 РіРҫРҙР° РҪазаРҙ
4 РіРҫРҙР° РҪазаРҙ
-
 5 Р»РөСӮ РҪазаРҙ
5 Р»РөСӮ РҪазаРҙ
-
 8 Р»РөСӮ РҪазаРҙ
8 Р»РөСӮ РҪазаРҙ
-
 4 РҙРҪСҸ РҪазаРҙ
4 РҙРҪСҸ РҪазаРҙ
-
 1 РіРҫРҙ РҪазаРҙ
1 РіРҫРҙ РҪазаРҙ
-
 1 РҙРөРҪСҢ РҪазаРҙ
1 РҙРөРҪСҢ РҪазаРҙ
-
 3 РіРҫРҙР° РҪазаРҙ
3 РіРҫРҙР° РҪазаРҙ
-
 3 РјРөСҒСҸСҶР° РҪазаРҙ
3 РјРөСҒСҸСҶР° РҪазаРҙ
-
 8 Р»РөСӮ РҪазаРҙ
8 Р»РөСӮ РҪазаРҙ
-
 6 Р»РөСӮ РҪазаРҙ
6 Р»РөСӮ РҪазаРҙ
-
 4 РіРҫРҙР° РҪазаРҙ
4 РіРҫРҙР° РҪазаРҙ