DEVS Reinforcement Learning and ParaDEVS enable smarter, faster, and adaptable policies for Trading скачать в хорошем качестве
DEVS Reinforcement Learning and ParaDEVS enable smarter, faster, and adaptable policies for Trading
10 дней назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: DEVS Reinforcement Learning and ParaDEVS enable smarter, faster, and adaptable policies for Trading в качестве 4k
У нас вы можете посмотреть бесплатно DEVS Reinforcement Learning and ParaDEVS enable smarter, faster, and adaptable policies for Trading или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон DEVS Reinforcement Learning and ParaDEVS enable smarter, faster, and adaptable policies for Trading в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
DEVS Reinforcement Learning and ParaDEVS enable smarter, faster, and adaptable policies for Trading
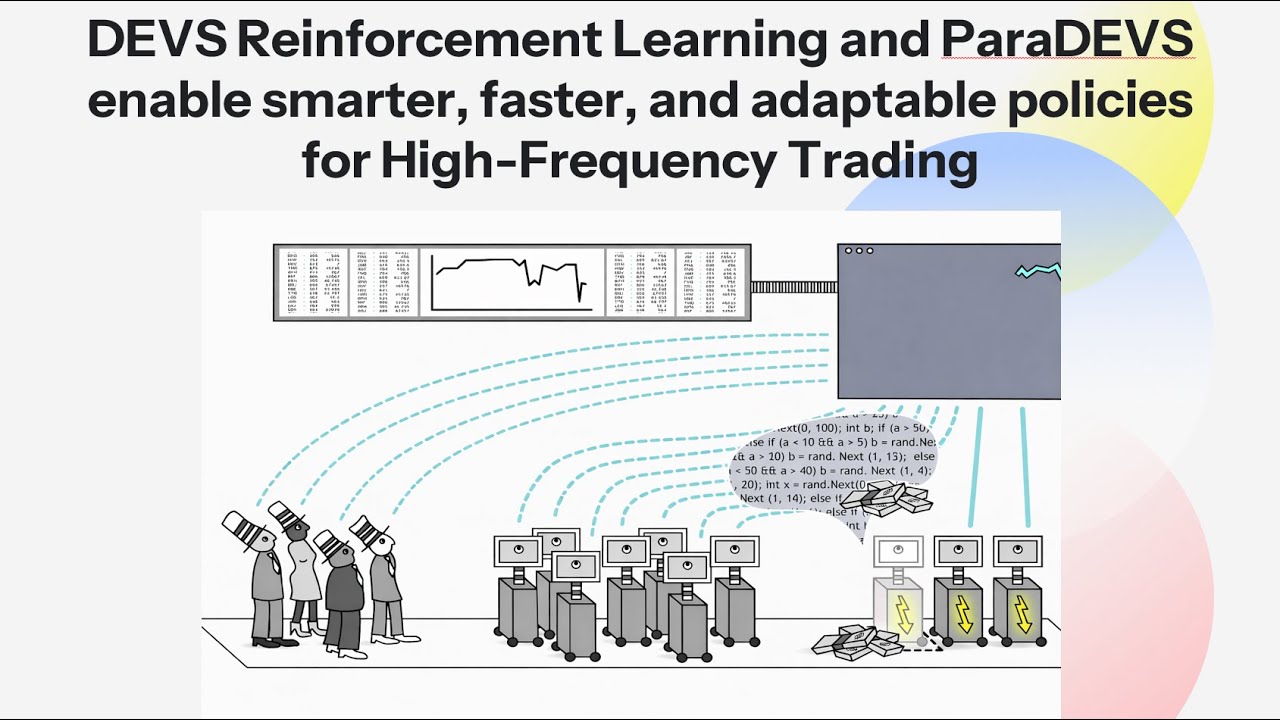
DEVS Reinforcement Learning (RL) and ParaDEVS model asynchronous, event‑driven behavior with mathematical rigor, capturing the true microstructure of electronic markets where microsecond timing, message sequencing, and latency dictate success or failure. DEVS RL and Paratemporal DEVS (ParaDEVS) not only accelerate computation but also provides greater efficiency, accuracy, and adaptability than traditional Reinforcement Learning. In this case study, we showcase how DEVS‑based Reinforcement Learning (DEVS RL) and the Paratemporal DEVS (ParaDEVS) framework deliver smarter, faster, and more adaptable policy construction for high‑frequency trading — outperforming traditional RL approaches that struggle with real‑world complexity. Modern electronic markets are event‑driven ecosystems, where microsecond timing, message sequencing, and latency dictate success or failure. Traditional RL methods, built on time‑stepped simulations or simplified back‑testing, often miss these critical dynamics. DEVS RL changes the game: it models asynchronous, event‑driven behavior with mathematical rigor, capturing the true microstructure of markets. This makes Discrete Vent System Specification (DEVS) a natural fit for reinforcement learning in high‑frequency trading, where precision and realism are non‑negotiable. Our case study demonstrates three key innovations: High‑fidelity DEVS exchange model with realistic order book and message routing. MS4 ME execution environment, ensuring correct event timing and modular scalability. ParaDEVS simulation framework, enabling efficient reward estimation and policy evaluation at scale. Together, these deliver accuracy, speed, and adaptability that traditional RL approaches cannot match. With DEVS, the exchange model is modular and future‑proof. Components can be added or reconfigured without costly redesigns. Capabilities include: Integration of historical market data Realistic limit order book matching engine Explicit latency modeling Multi‑agent support for both learning and non‑learning traders This modularity and fidelity ensure RL agents train in an environment that mirrors real market complexity, not oversimplified abstractions. Once the DEVS model is created, it is executed within MS4 ME, a software architecture built specifically to run DEVS models with precise event timing and sequencing. MS4 ME eliminates the need for developers to manually program low‑level elements such as simulation clocks or event queues, allowing them to concentrate on the core model logic. In addition, its GUI‑based configuration tools make it easy to design, modify, and expand models quickly, supporting a flexible and modular development process. Our exchange is built as a high fidelity event driven ecosystem, with clients, brokers, ports, and a matching engine working together to mirror real market dynamics. Latency, compliance checks, and order sequencing are all modeled with precision, ensuring a simulation environment that feels as close to live trading as possible. This delivers the realism and rigor traditional RL frameworks often miss. MS4 ME offers both programmatic and graphical interfaces, making simulations easy to run and analyze. You can debug market behavior down to individual events while still scaling confidently to large, complex simulations. It’s the perfect balance of granular insight and enterprise‑level scalability. The ParaDEVS framework is used for the value estimation component for reinforcement learning architectures. Rather than relying on a single simulated trajectory, ParaDEVS allows the simulation to branch, enabling either single-path sampling or full utilization of the policy tree. The ParaDEVS framework is agnostic to the specific reinforcement learning algorithm used. Whether the user employs policy gradients, PPO, CVaR-based objectives, or a proprietary method, the DEVS, MS4 ME, and ParaDEVS layers remain unchanged. This separation of concerns allows researchers and practitioners to focus on policy design while relying on a rigorously defined simulation backbone. Traditional RL often relies on single simulated trajectories, limiting exploration and slowing convergence. ParaDEVS revolutionizes this process: Enables branching simulations across multiple paths Supports both single‑path sampling and full policy tree exploration Dramatically improves value estimation quality This means RL agents can explore uncertainty in market responses and risk outcomes without prohibitive computational costs. With ParaDEVS, execution time drops from exponential to polynomial growth when exploring deep stochastic paths. That’s a quantum leap in efficiency — making sophisticated RL strategies computationally feasible where traditional methods stall. For more information on ParaDEVS, please visit https://rtsync.com/paradevs or contact us at [email protected].
Comments



















