Building makemore Part 3: Activations & Gradients, BatchNorm скачать в хорошем качестве
Building makemore Part 3: Activations & Gradients, BatchNorm
3 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Building makemore Part 3: Activations & Gradients, BatchNorm в качестве 4k
У нас вы можете посмотреть бесплатно Building makemore Part 3: Activations & Gradients, BatchNorm или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Building makemore Part 3: Activations & Gradients, BatchNorm в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Building makemore Part 3: Activations & Gradients, BatchNorm
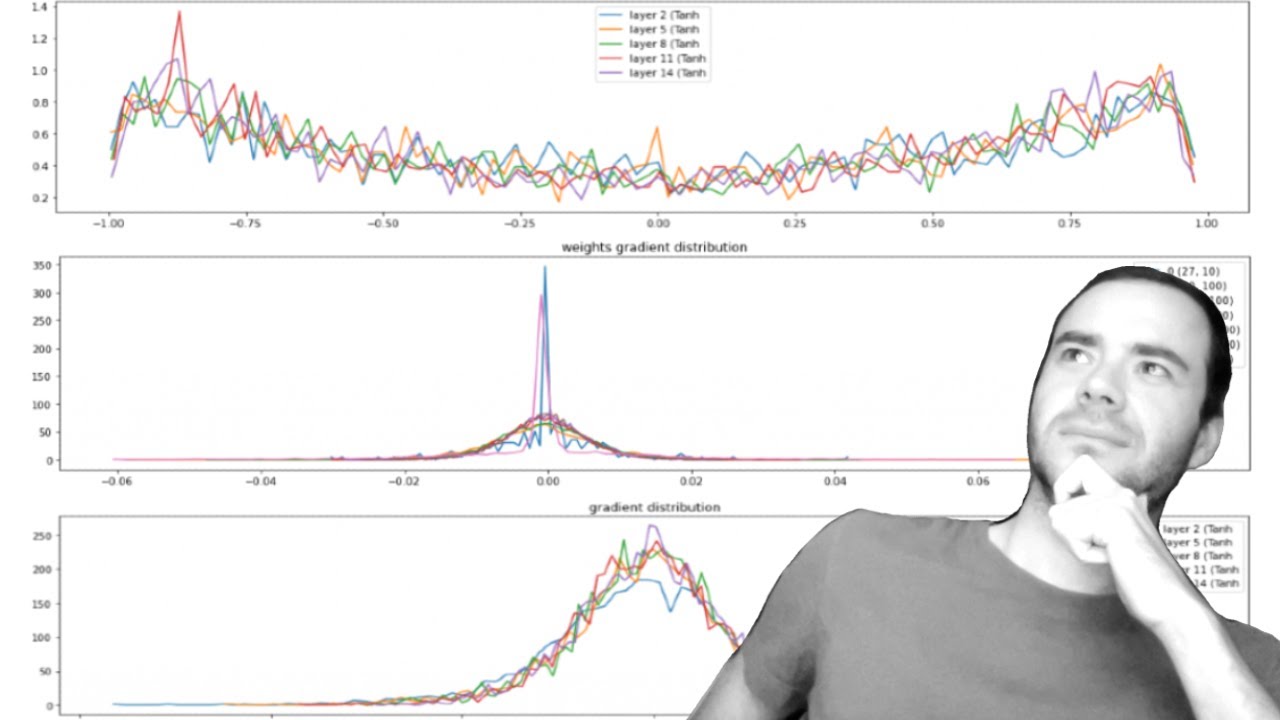
We dive into some of the internals of MLPs with multiple layers and scrutinize the statistics of the forward pass activations, backward pass gradients, and some of the pitfalls when they are improperly scaled. We also look at the typical diagnostic tools and visualizations you'd want to use to understand the health of your deep network. We learn why training deep neural nets can be fragile and introduce the first modern innovation that made doing so much easier: Batch Normalization. Residual connections and the Adam optimizer remain notable todos for later video. Links: makemore on github: https://github.com/karpathy/makemore jupyter notebook I built in this video: https://github.com/karpathy/nn-zero-t... collab notebook: https://colab.research.google.com/dri... my website: https://karpathy.ai my twitter: / karpathy Discord channel: / discord Useful links: "Kaiming init" paper: https://arxiv.org/abs/1502.01852 BatchNorm paper: https://arxiv.org/abs/1502.03167 Bengio et al. 2003 MLP language model paper (pdf): https://www.jmlr.org/papers/volume3/b... Good paper illustrating some of the problems with batchnorm in practice: https://arxiv.org/abs/2105.07576 Exercises: E01: I did not get around to seeing what happens when you initialize all weights and biases to zero. Try this and train the neural net. You might think either that 1) the network trains just fine or 2) the network doesn't train at all, but actually it is 3) the network trains but only partially, and achieves a pretty bad final performance. Inspect the gradients and activations to figure out what is happening and why the network is only partially training, and what part is being trained exactly. E02: BatchNorm, unlike other normalization layers like LayerNorm/GroupNorm etc. has the big advantage that after training, the batchnorm gamma/beta can be "folded into" the weights of the preceeding Linear layers, effectively erasing the need to forward it at test time. Set up a small 3-layer MLP with batchnorms, train the network, then "fold" the batchnorm gamma/beta into the preceeding Linear layer's W,b by creating a new W2, b2 and erasing the batch norm. Verify that this gives the same forward pass during inference. i.e. we see that the batchnorm is there just for stabilizing the training, and can be thrown out after training is done! pretty cool. Chapters: 00:00:00 intro 00:01:22 starter code 00:04:19 fixing the initial loss 00:12:59 fixing the saturated tanh 00:27:53 calculating the init scale: “Kaiming init” 00:40:40 batch normalization 01:03:07 batch normalization: summary 01:04:50 real example: resnet50 walkthrough 01:14:10 summary of the lecture 01:18:35 just kidding: part2: PyTorch-ifying the code 01:26:51 viz #1: forward pass activations statistics 01:30:54 viz #2: backward pass gradient statistics 01:32:07 the fully linear case of no non-linearities 01:36:15 viz #3: parameter activation and gradient statistics 01:39:55 viz #4: update:data ratio over time 01:46:04 bringing back batchnorm, looking at the visualizations 01:51:34 summary of the lecture for real this time
Comments