Bank Customer churn prediction - Kaggle скачать в хорошем качестве
Bank Customer churn prediction - Kaggle
2 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Bank Customer churn prediction - Kaggle в качестве 4k
У нас вы можете посмотреть бесплатно Bank Customer churn prediction - Kaggle или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Bank Customer churn prediction - Kaggle в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Bank Customer churn prediction - Kaggle
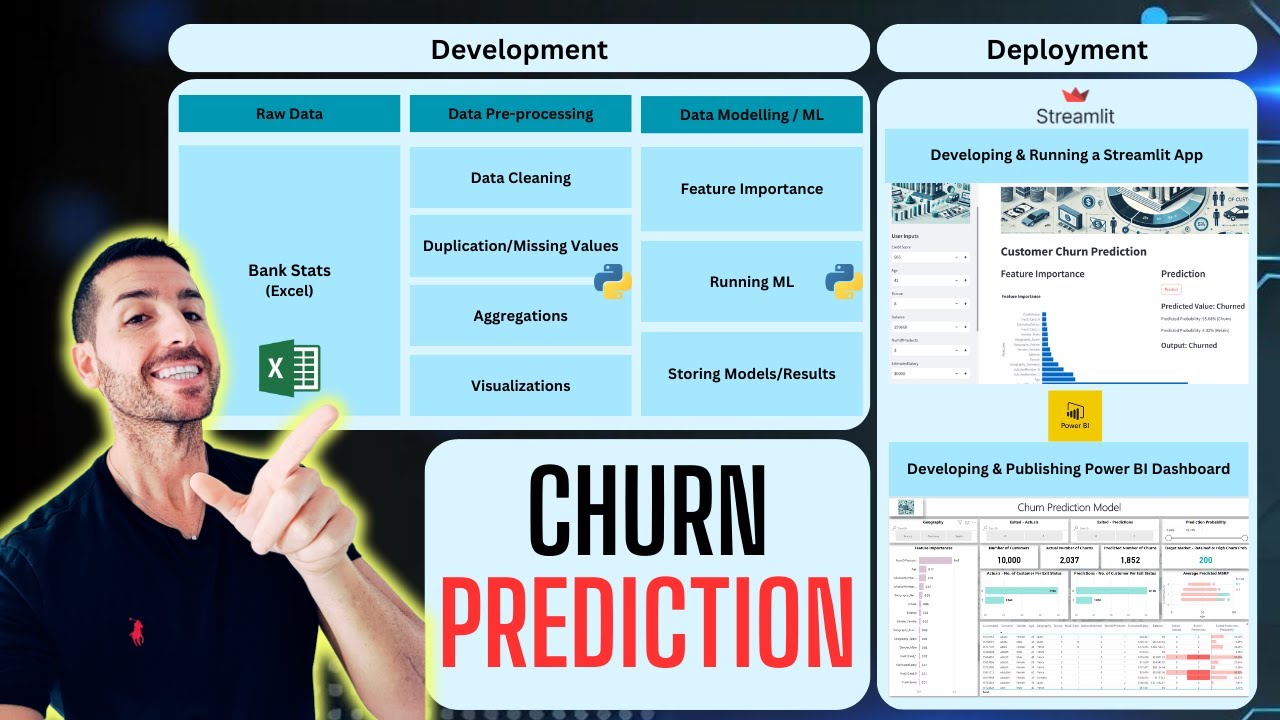
Data science Kaggle example. Link to the dataset - https://www.kaggle.com/datasets/radhe... Link to the code - https://drive.google.com/file/d/15e_U... A few things to keep in mind, if you try to classify imbalanced cases – 1) When splitting the dataset to train and test, do not forget to use stratify to make sure the distribution and proportion of the categories of the target variable is similar in each of the datasets. 2) If you use oversampling or undersampling methods, to balance the dataset, before modeling, it is recommended to use normalization/standardization first, since these methods use the KNN algorithm and because KNN is a distance-based method, it may be affected. 3) When evaluating the model, do not use the accuracy score, since it only counts the number of successes the model had and does not look at the success of each group (the minority and the majority classes. Moreover, this evaluation method gives more weight to the majority class. 4) More suitable evaluation methods that can be used are F1-score, Precision and recall. Recall is the ratio of the model’s success to predict the minority class divided by the total minority cases (TP/(TP+FN)). Precision is the ratio of the model’s success to predict the minority class divided the total times of the predicted minority cases (TP/(TP+FP)). F1 score is an average (harmonic mean) of recall and precision. Example – let’s say we ran a logistic regression and the recall we got was 0.6 and the precision was 0.5. That means that we were able to classify 60% of the minority classes correctly from the total cases (classified correctly 60% of the real churned customers), and for the precision is 50% so that means that the model will predict twice the cases in the minority class, even though only half of them belong to the minority class (I like to say it sort of noise. If the model predicted 200 churned cases, with precision of 50%, only 100 of these cases will churn). 5) There is a tradeoff between precision and recall. You can use the precision-recall curve to see the tradeoff over thresholds. TP = true positive cases (correctly predicted minority class instances) FP = false positive cases (misclassified majority class instances) FN = false negative cases (misclassified minority class instances)
Comments