Million Token Context Windows? Myth Busted—Limits & Fixes скачать в хорошем качестве
Million Token Context Windows? Myth Busted—Limits & Fixes
7 месяцев назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Million Token Context Windows? Myth Busted—Limits & Fixes в качестве 4k
У нас вы можете посмотреть бесплатно Million Token Context Windows? Myth Busted—Limits & Fixes или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Million Token Context Windows? Myth Busted—Limits & Fixes в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Million Token Context Windows? Myth Busted—Limits & Fixes
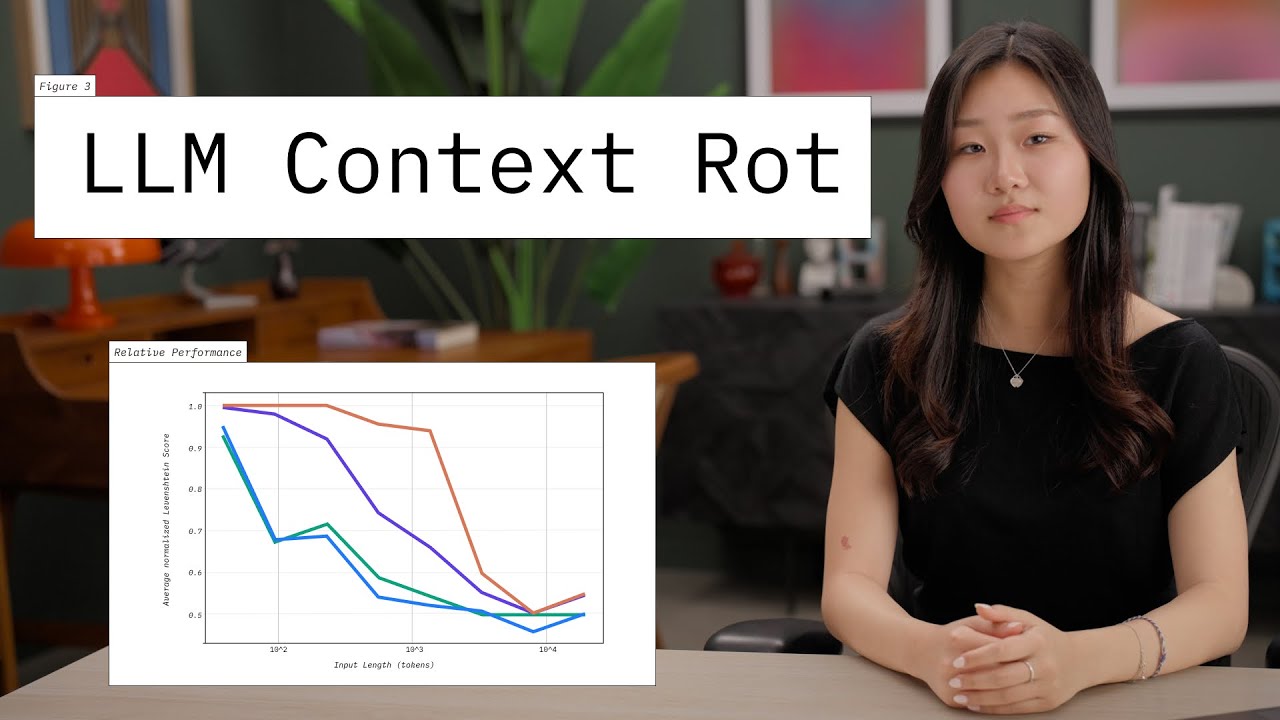
The story: https://open.substack.com/pub/natesne... My site: https://natebjones.com/ My links: https://linktr.ee/natebjones My substack: https://natesnewsletter.substack.com/ Takeaways: 1. Context-Window Reality Check: Million-token marketing claims crumble in practice—most models deliver reliable results for only ~128K tokens, leaving the remaining 90 % largely ineffective. 2. Edge-Bias in Attention: Transformers focus up to three times harder on the first and last tokens, creating a “U-shaped” comprehension curve that starves the middle of vital context. 3. Five Fixes That Work: Retrieval-Augmented Generation, summary chains, strategic chunking, strict context budgeting, and deliberate position-hacking together beat raw token brute-force every time. 4. Quadratic Cost Wall: Processing longer prompts scales to the fourth power, driving steep latency and energy bills and exposing hard thermodynamic ceilings for current architectures. 5. AGI Implications: If models can’t synthesize a single book today, betting they’ll seamlessly integrate a lifetime of experience tomorrow may be wishful thinking without a new attention breakthrough. 6. Demand Honest Benchmarks: Forget “needle-in-a-haystack” stunts—measure true synthesis across complex documents so builders can plan realistically and users know what they’re buying. Quotes: “Every million-token boast masks the truth: after about 128 K, performance falls off a cliff.” “Attention is 3× stronger at the beginning and end—everything in the middle is running on vibes.” “We can build transformative products today, but only if we treat tokens like precious RAM and design accordingly.” Summary: I unpack why massive context windows are more hype than help. Vendors tout million-token limits, but real-world tests show dependable comprehension tops out around 128 K tokens and degrades sharply in the middle. I outline five proven tactics—RAG, summary chains, strategic chunking, context budgeting, and position hacking—that let you squeeze real value from today’s models while slashing cost. Because attention scales quadratically, truly giant prompts hit energy and latency walls, raising doubts about current paths to AGI. Still, with disciplined context engineering, today’s LLMs are powerful enough to deliver transformative business and personal gains right now. Keywords: context window, transformer attention, LLM limitations, retrieval-augmented generation, summary chains, strategic chunking, context budgeting, position hacking, quadratic scaling, token economy, synthesis benchmarks, AGI skepticism, artificial general intelligence, vendor claims, document analysis
Comments