Boost Vector DB Search Speed with Caching - Step-by-Step Guide | Embeddings, Indexing, and Caching скачать в хорошем качестве
Boost Vector DB Search Speed with Caching - Step-by-Step Guide | Embeddings, Indexing, and Caching
3 месяца назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Boost Vector DB Search Speed with Caching - Step-by-Step Guide | Embeddings, Indexing, and Caching в качестве 4k
У нас вы можете посмотреть бесплатно Boost Vector DB Search Speed with Caching - Step-by-Step Guide | Embeddings, Indexing, and Caching или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Boost Vector DB Search Speed with Caching - Step-by-Step Guide | Embeddings, Indexing, and Caching в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Boost Vector DB Search Speed with Caching - Step-by-Step Guide | Embeddings, Indexing, and Caching
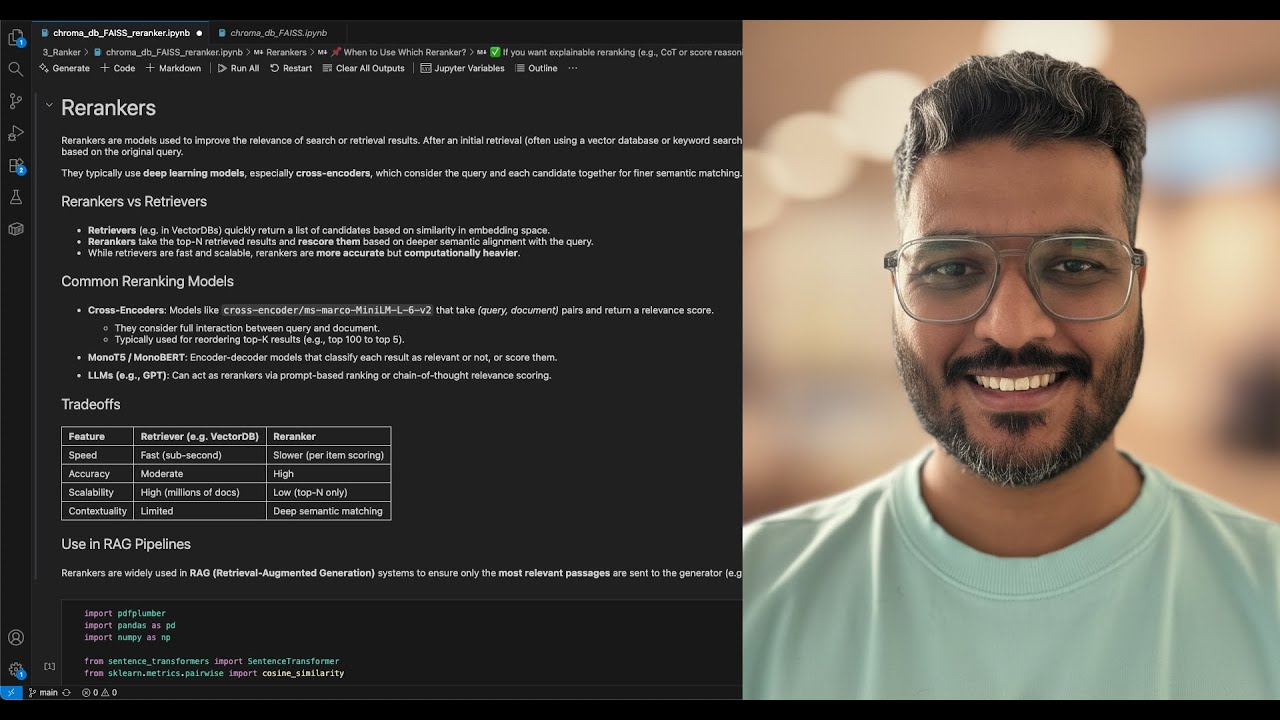
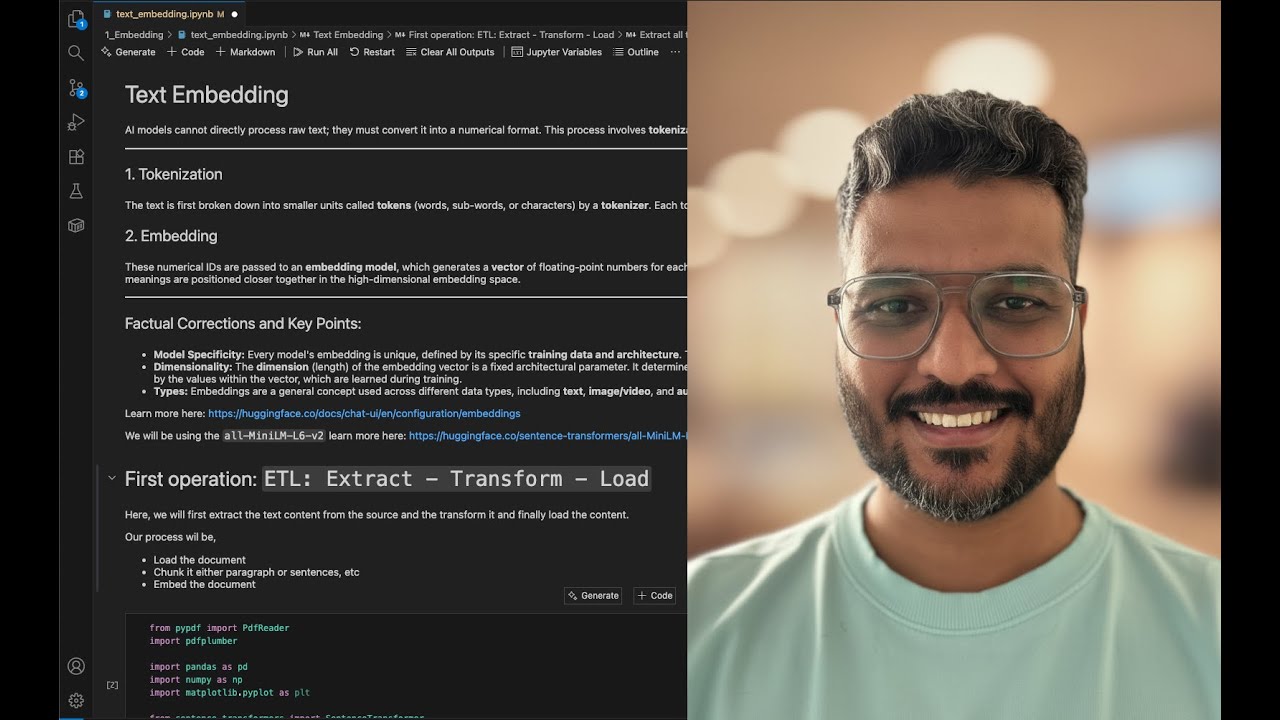
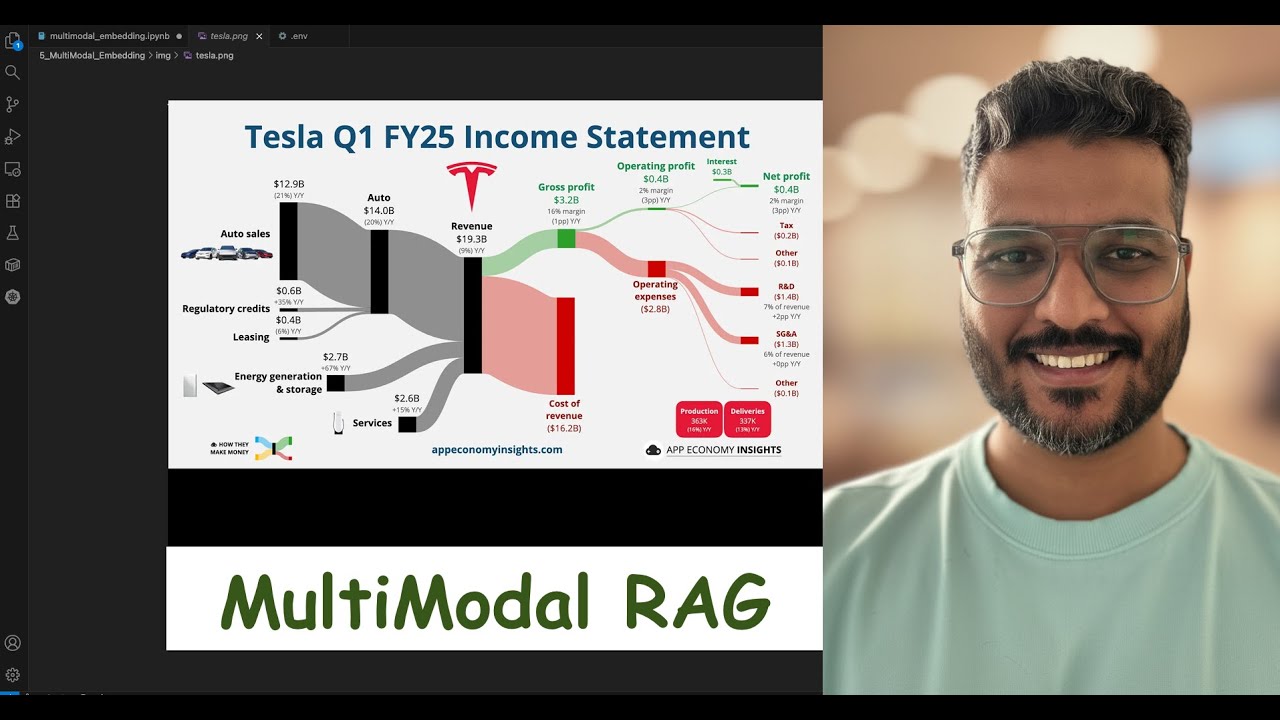
Learn how to build a powerful and efficient vector search system using ChromaDB with HNSW indexing and MiniLM-L6-v2 text embeddings. In this tutorial, we take a deep dive into optimizing performance by implementing query caching and only hitting the database when necessary—based on similarity thresholds. 🚀 What You'll Learn: How to set up and use ChromaDB with default HNSW index Integrating MiniLM-L6-v2 embeddings for text vectorization Implementing smart query caching to reduce redundant vector searches Dynamically checking similarity scores before querying the DB Practical example & code walkthrough 📦 Tools & Technologies: ChromaDB Hugging Face Transformers - MiniLM-L6-v2 HNSW Indexing Python 🧠 Whether you're building a chatbot, semantic search engine, or any NLP app, this technique can save compute and speed up response times. Previous Video: Text Embedding: • Text Embedding Guide: Query PDFs & Retriev... 📁 Code Repository: [https://github.com/mohitdb7/Youtube-T...] 👍 Like the video if it helped, and subscribe for more tutorials on AI, ML, and vector databases! #ChromaDB #VectorSearch #MiniLM #HNSW #SemanticSearch #Python #Embedding #AI #Tutorial #Caching #RAG
Comments