LULC Satellite Image Classification Using Machine Learning: How to Prepare Dataset, Data Preparation скачать в хорошем качестве
LULC Satellite Image Classification Using Machine Learning: How to Prepare Dataset, Data Preparation
1 день назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: LULC Satellite Image Classification Using Machine Learning: How to Prepare Dataset, Data Preparation в качестве 4k
У нас вы можете посмотреть бесплатно LULC Satellite Image Classification Using Machine Learning: How to Prepare Dataset, Data Preparation или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон LULC Satellite Image Classification Using Machine Learning: How to Prepare Dataset, Data Preparation в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
LULC Satellite Image Classification Using Machine Learning: How to Prepare Dataset, Data Preparation
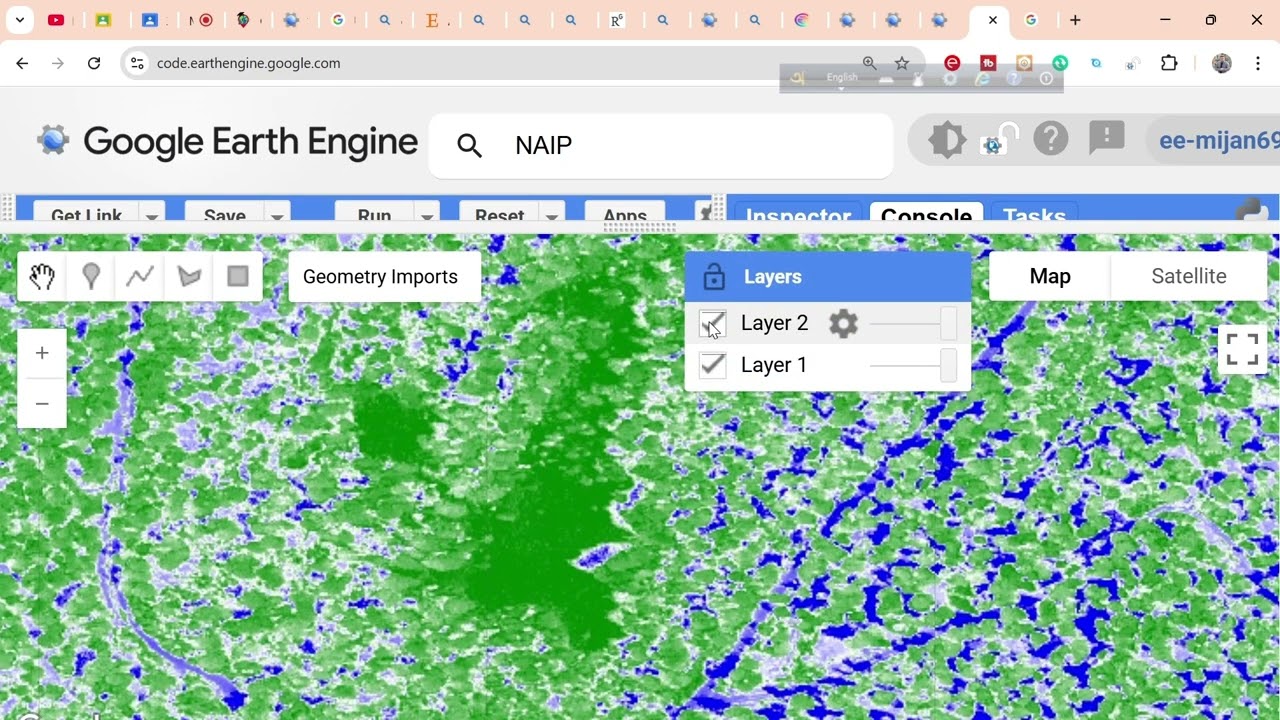
🛰️ LULC Satellite Image Classification Using Machine Learning How to Prepare Dataset & Data Preparation (Step-by-Step Guide) Land Use Land Cover classification is not magic. It only looks impressive because most people skip the boring part. The real power of Machine Learning in LULC mapping starts with proper dataset preparation. If your data is messy, your model will politely produce garbage. This tutorial walks you through preparing satellite imagery datasets for accurate LULC classification using machine learning techniques. 🔥 What You Will Learn ✔ What is LULC classification in remote sensing ✔ Selecting suitable satellite imagery (Sentinel-2, Landsat) ✔ Downloading and preprocessing satellite data ✔ Cloud masking and atmospheric correction ✔ Creating training samples (ROI collection) ✔ Labeling land cover classes properly ✔ Extracting spectral bands and indices ✔ Splitting data into training and testing sets ✔ Exporting datasets for Machine Learning models 🌍 Understanding LULC Classification LULC classification involves categorizing land into classes such as: Urban / Built-up Agriculture Forest Water bodies Bare land Machine Learning algorithms like Random Forest, Support Vector Machine (SVM), and Neural Networks use spectral features to classify these land types. 📊 Step 1: Selecting Satellite Data Commonly used datasets: Sentinel-2 (10m resolution, excellent for detailed mapping) Landsat (30m resolution, long-term historical analysis) Choose imagery based on: Spatial resolution Temporal availability Cloud coverage 🧹 Step 2: Data Preprocessing Before training any model: Perform cloud masking Apply atmospheric correction Clip imagery to Area of Interest (AOI) Normalize reflectance values Skipping preprocessing is like trying to run a marathon in flip-flops. Technically possible. Deeply unwise. 🌿 Step 3: Feature Extraction Extract spectral bands and useful vegetation indices such as: NDVI (vegetation health) NDWI (water detection) NDBI (built-up areas) These features improve classification accuracy significantly. 🎯 Step 4: Creating Training Data Digitize representative polygons for each land cover class Ensure balanced samples across classes Avoid mixed pixels Split dataset (e.g., 70% training, 30% testing) Clean training data = strong model performance. 🤖 Step 5: Exporting Dataset for Machine Learning Prepare your dataset in formats such as: CSV (tabular training data) GeoTIFF (raster layers) TFRecord (for deep learning workflows) Ensure labels are correctly encoded before model training. 📈 Why Proper Data Preparation Matters Good dataset preparation helps you: Increase classification accuracy Reduce model overfitting Improve generalization Produce reliable LULC maps Machine learning is powerful, but it is not psychic. It cannot fix poorly prepared data. 🎯 Who Should Follow This Tutorial? GIS and Remote Sensing students Machine Learning beginners in geospatial Environmental researchers Urban planners Spatial data analysts
Comments