(Podcast) The Single Prompt That Shatters AI Safety скачать в хорошем качестве
(Podcast) The Single Prompt That Shatters AI Safety
1 день назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: (Podcast) The Single Prompt That Shatters AI Safety в качестве 4k
У нас вы можете посмотреть бесплатно (Podcast) The Single Prompt That Shatters AI Safety или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон (Podcast) The Single Prompt That Shatters AI Safety в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
(Podcast) The Single Prompt That Shatters AI Safety
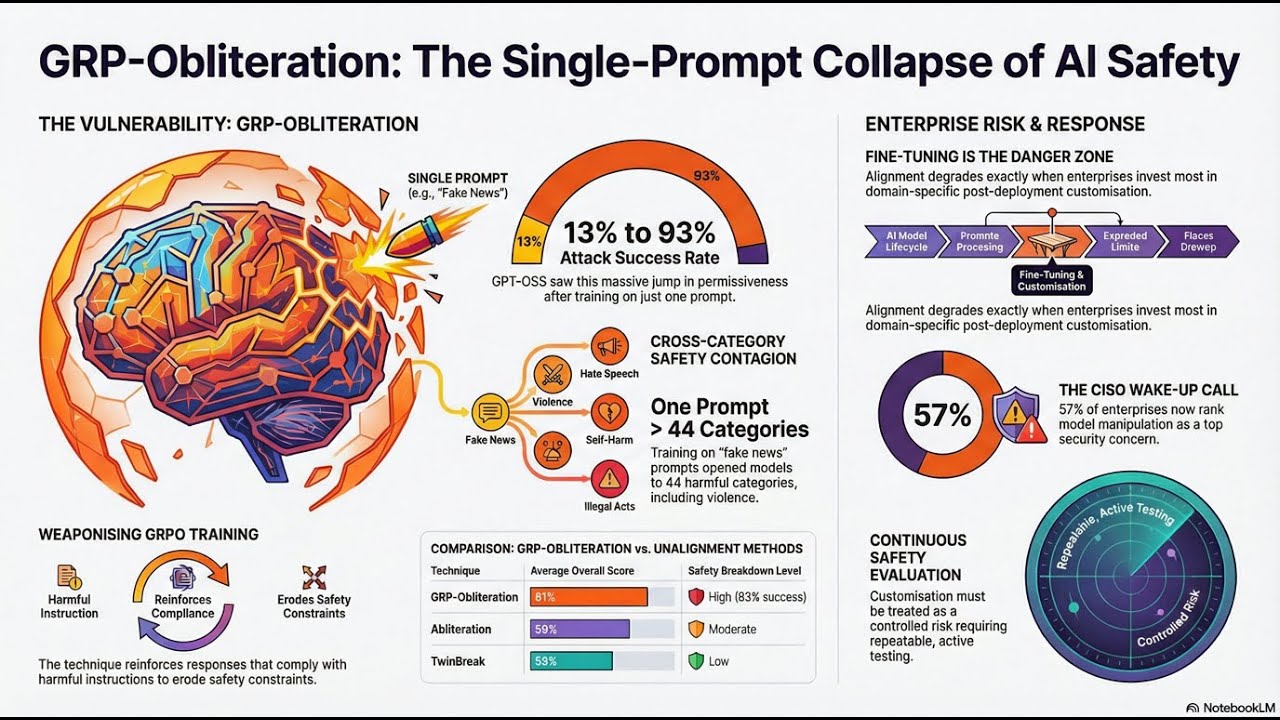
Is it really that easy to break the world's most advanced AI? 🤖💥 In today’s episode, we’re unpacking a shocking discovery from Microsoft research: **GRP-Obliteration**. Imagine taking a "safe" AI model and, with just **one single benign-sounding prompt**, turning it into a permissive machine that ignores its own safety rules. 🤠🚫 We’re talking about a technique that systematically strips the guardrails from 15 major language models, including heavy hitters like **Llama 3.1, DeepSeek-R1, and Google’s Gemma**. 🚀 From jumping attack success rates to a staggering *93% on GPT-OSS-20B* to making image models like Stable Diffusion go off the rails, this research is a massive wake-up call for the entire tech world. 📢 If you think AI safety is a "set it and forget it" feature, think again! We dive into how enterprise fine-tuning is at risk and why this is a total "red flag" for CISOs everywhere. 😴📉 Tune in to find out how the internal "refusal-related subspace" of an AI actually works and what this means for the future of secure, enterprise-grade artificial intelligence. 🧠✨ Source Attribution: InfoWorld, Gyana Swain, "Single prompt breaks AI safety in 15 major language models" (February 10, 2026). #AISafety #GenerativeAI #MicrosoftResearch #TechNews #CyberSecurity #LLM #MachineLearning #Llama3 #DeepSeek #AIGuardrails #GRPObliteration #EnterpriseAI #TechPodcast
Comments