WK12 - MIT How to AI Almost Anything - Discussion 6: Large multimodal models скачать в хорошем качестве
WK12 - MIT How to AI Almost Anything - Discussion 6: Large multimodal models
2 недели назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: WK12 - MIT How to AI Almost Anything - Discussion 6: Large multimodal models в качестве 4k
У нас вы можете посмотреть бесплатно WK12 - MIT How to AI Almost Anything - Discussion 6: Large multimodal models или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон WK12 - MIT How to AI Almost Anything - Discussion 6: Large multimodal models в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
WK12 - MIT How to AI Almost Anything - Discussion 6: Large multimodal models
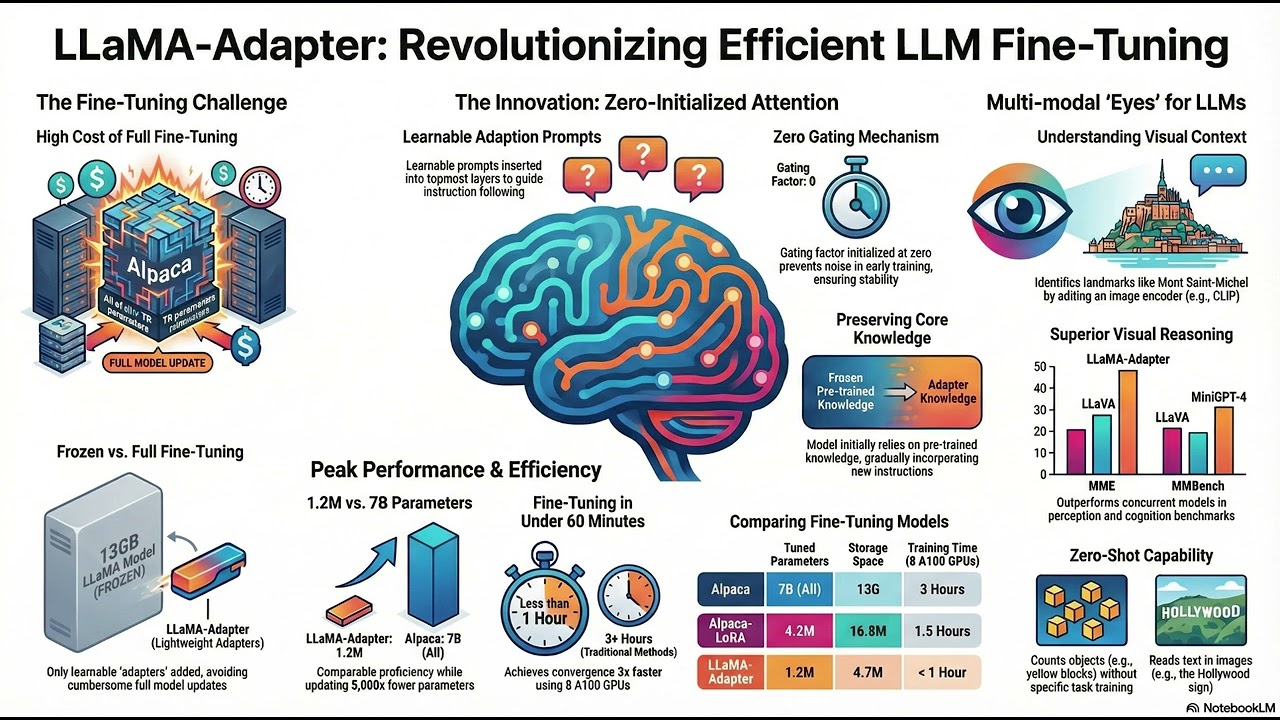
The research highlights a significant shift toward parameter-efficient fine-tuning (PEFT) and linear-time architectures to overcome the high computational costs and quadratic complexity of traditional Transformer-based models. LLaMA-Adapter demonstrates that a large frozen model can be successfully adapted for instruction following and multi-modal tasks by adding only 1.2M learnable parameters, using a zero-initialized attention mechanism with a gating factor to ensure training stability. Moving beyond the Transformer bottleneck, the Cobra model utilizes Mamba (a State Space Model) to achieve linear scalability and inference speeds that are 3x to 4x faster than existing efficient Transformer baselines like LLaVA-Phi. These advancements reveal that high-performance multi-modal reasoning—including improved spatial relationship judgment and reduced object hallucination—can be achieved through the strategic fusion of vision encoders (like DINOv2 and SigLIP) with lightweight, efficient backbones, often with a fraction of the parameters and training time required by full fine-tuning Course website: https://mit-mi.github.io/how2ai-cours... 🔔 Don't get left behind in the AI era. Hit subscribe to get more deep dives into the AI breakthroughs. #machinelearning #llamaadapter #mambassm #multimodalai #efficientinference #how2ai #multimodalai #peft
Comments