Optimizing Throughput in Apache Kafka 🍢 — The Secret to a Faster Cluster! скачать в хорошем качестве
Optimizing Throughput in Apache Kafka 🍢 — The Secret to a Faster Cluster!
3 месяца назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Optimizing Throughput in Apache Kafka 🍢 — The Secret to a Faster Cluster! в качестве 4k
У нас вы можете посмотреть бесплатно Optimizing Throughput in Apache Kafka 🍢 — The Secret to a Faster Cluster! или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Optimizing Throughput in Apache Kafka 🍢 — The Secret to a Faster Cluster! в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Optimizing Throughput in Apache Kafka 🍢 — The Secret to a Faster Cluster!
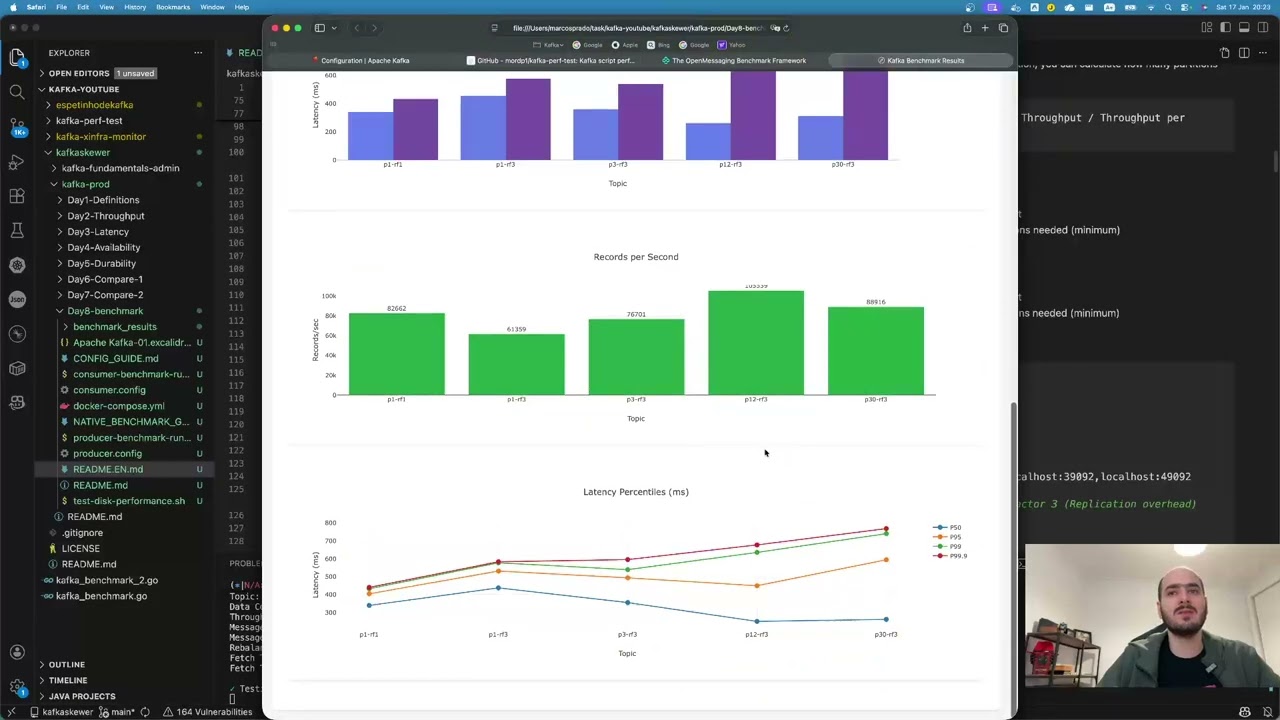
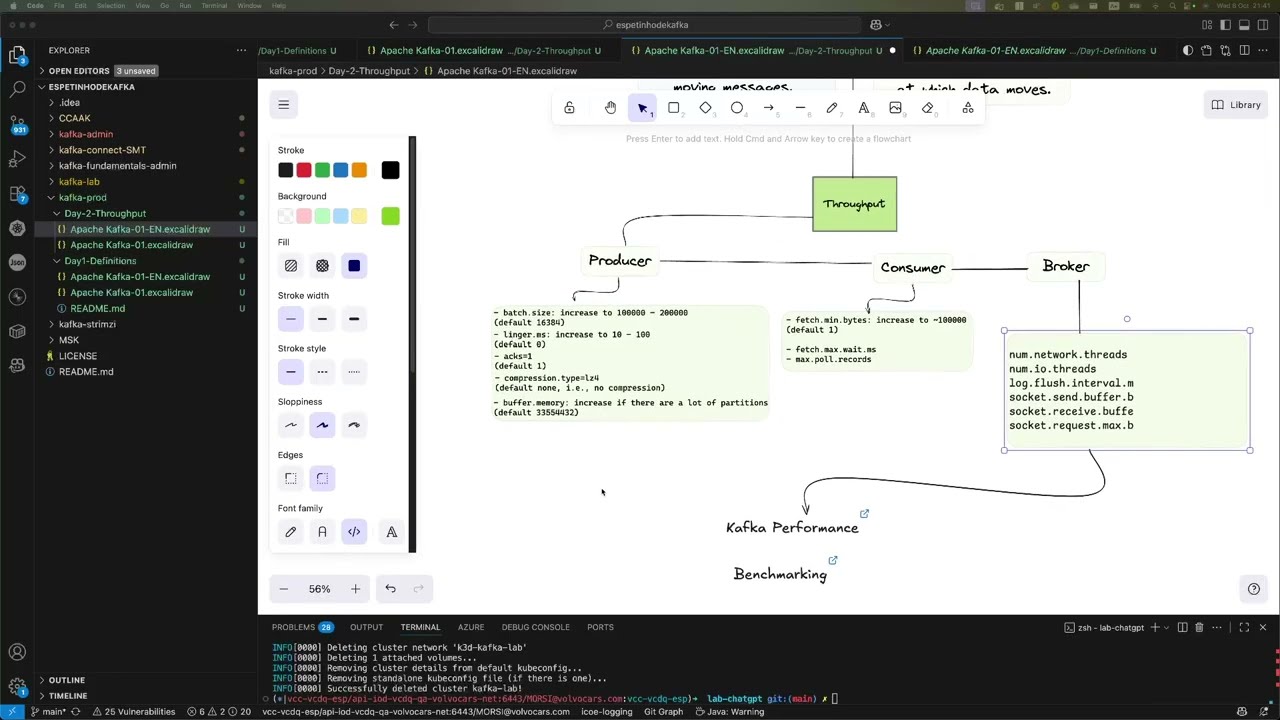
🍢 Menu of the Day — Kafka Skewer 🍢 Today, the grill master is turning up the heat on your cluster! 🔥 We’re diving into how to optimise Apache Kafka throughput, fine-tuning producers, brokers, and consumers so your data flows faster than smoke off the grill 😎 In this episode, you’ll learn: 🥩 Appetizers What throughput really means and why it matters How partitions are the secret spice for performance 🔥 Main Course How to tune batch.size, linger.ms, and compression.type for maximum efficiency The power of acks=1 and buffer.memory in producers Consumer tuning tips (fetch.min.bytes, max.poll.records) Broker configurations that prevent bottlenecks 🎁 Dessert The final recipe for perfect throughput Pro tips for testing and benchmarking in your local lab 💡 Watch until the end to see how small tweaks can massively boost your Kafka performance — no hardware upgrades required! If you enjoy it, drop a like, share your favourite tuning tips in the comments, and subscribe so you don’t miss the next data BBQ 🔥🍢 #Kafka #KafkaSkewer #ApacheKafka #KafkaPerformance #KafkaThroughput #DevOps #StreamingData #KafkaProducer #KafkaConsumer #Prometheus #Grafana #Observability #TuningKafka #DataEngineering #BigData #Confluent #DevAdvocate
Comments