How to Read Iceberg V2 Row-Level Deletes in Databricks - Copy-on-Write tables скачать в хорошем качестве
How to Read Iceberg V2 Row-Level Deletes in Databricks - Copy-on-Write tables
6 дней назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: How to Read Iceberg V2 Row-Level Deletes in Databricks - Copy-on-Write tables в качестве 4k
У нас вы можете посмотреть бесплатно How to Read Iceberg V2 Row-Level Deletes in Databricks - Copy-on-Write tables или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон How to Read Iceberg V2 Row-Level Deletes in Databricks - Copy-on-Write tables в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
How to Read Iceberg V2 Row-Level Deletes in Databricks - Copy-on-Write tables
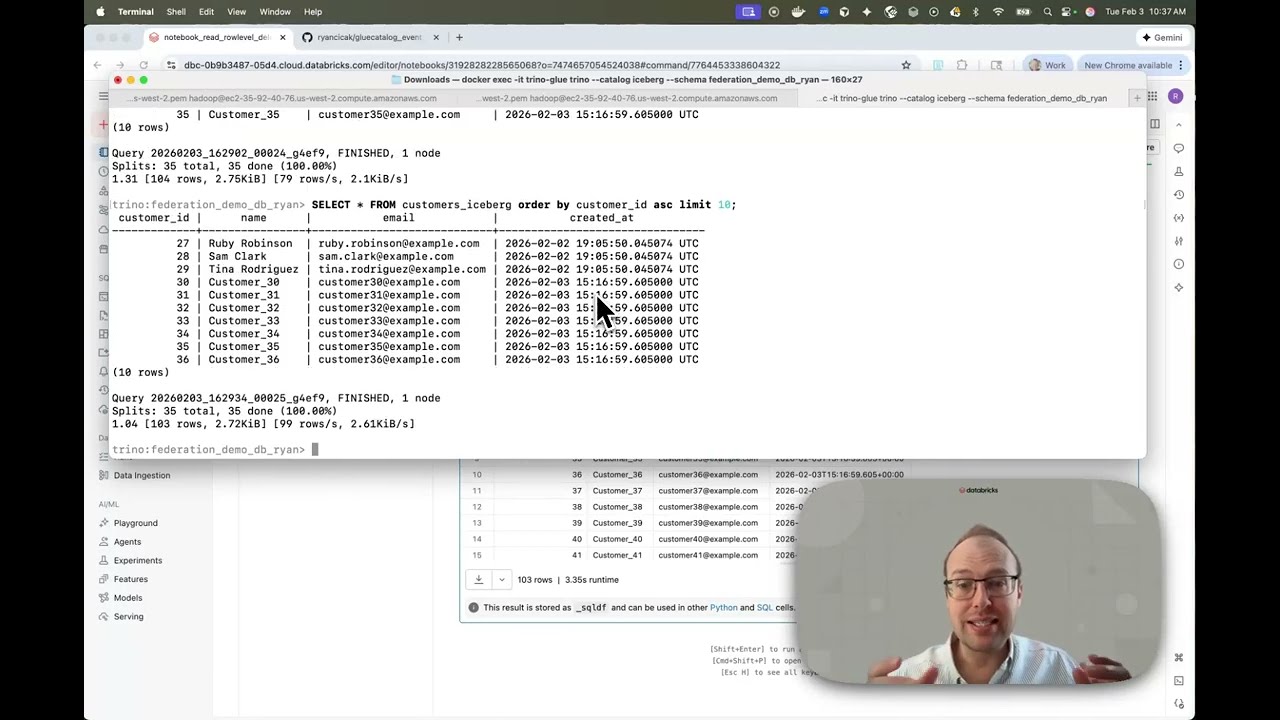
How to Read Iceberg V2 Row-Level Deletes in Databricks - Copy-on-Write Tables In my previous video, I showed an event-driven compaction solution for reading Iceberg V2 row-level deletes in Databricks. That approach works well when you need to keep Merge-on-Read (MoR) for engines like Trino that require it for deletes and updates. But what if you can switch to Copy-on-Write (CoW)? In this video, I walk through: How to convert an existing MoR table to CoW with a single DDL statement Running compaction to clean up existing delete files (you may need to run this more than once to fully clear them) Confirming Databricks can read the table after conversion Demonstrating that Trino can still READ from CoW tables (it just can't issue deletes or updates) Why CoW makes sense for streaming workloads with batch appends, where you want to avoid continuous compaction overhead The bottom line: If your engine issuing deletes and updates supports CoW (Spark, Databricks, etc.) and Trino is read-only in your architecture, CoW is the simpler path. One DDL change, run compaction until delete files are cleared, done. GitHub repo: https://github.com/ryancicak/gluecata...
Comments














![Как происходит модернизация остаточных соединений [mHC]](https://imager.clipsaver.ru/jYn_1PpRzxI/max.jpg)


![Детектирование виртуальных машин: как оно работает и как его обходят [RU]](https://imager.clipsaver.ru/W-KGmGH_IZ4/max.jpg)