How does Docker run machine learning on AI accelerators (NVIDIA GPUs, AWS Inferentia) скачать в хорошем качестве
How does Docker run machine learning on AI accelerators (NVIDIA GPUs, AWS Inferentia)
3 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: How does Docker run machine learning on AI accelerators (NVIDIA GPUs, AWS Inferentia) в качестве 4k
У нас вы можете посмотреть бесплатно How does Docker run machine learning on AI accelerators (NVIDIA GPUs, AWS Inferentia) или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон How does Docker run machine learning on AI accelerators (NVIDIA GPUs, AWS Inferentia) в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
How does Docker run machine learning on AI accelerators (NVIDIA GPUs, AWS Inferentia)
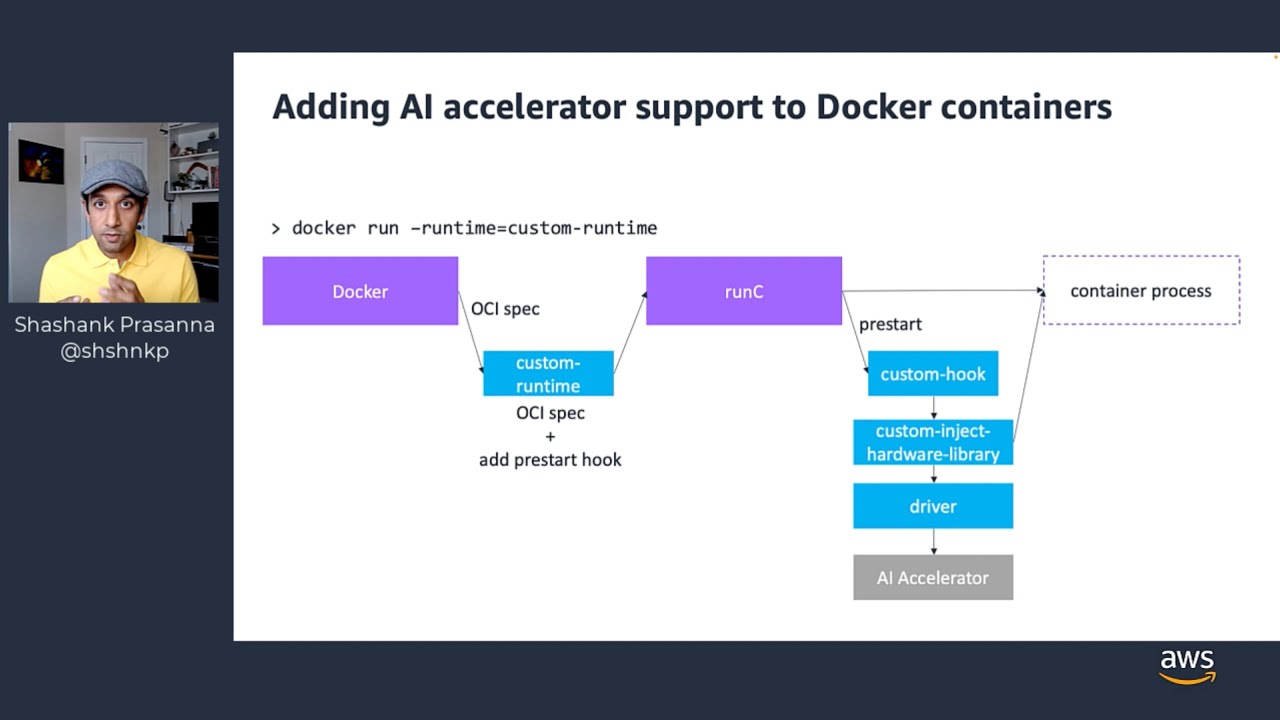
(This talk was presented at Docker Community All Hands) The use of specialized processors for specialized tasks date back to the 70s where CPUs were paired with coprocessor for floating-point calculation. Fast forward to today, most machine learning (ML) computations are run on a combination of CPUs and GPUs or specialized AI hardware accelerators such as AWS Inferentia and Intel Habana Gaudi. Docker and container technologies have become indispensable tools when it come to scaling machine learning, but how does it work when you have more than one type of processors on the same system? Does Docker still guarentee all its benefits when working with different processors? In this talk, I’ll discuss how Docker containers works on CPU-only systems and then discuss how you can use it in heterogenous systems with multiple processors. Based on current trends and the introduction of newer AI silicon (GPUs, TPUs, GraphCore, AWS Tranium & Inferentia, Intel Habana Gaudi and more) it’s evident that the future all machine learning workloads will run on multiple-processors and I’ll discuss the role of containers in this future.
Comments