Qwen 3.5 27B против 35B-A3B: локальное тестирование с 16 ГБ видеопамяти скачать в хорошем качестве
Qwen 3.5 27B против 35B-A3B: локальное тестирование с 16 ГБ видеопамяти
2 недели назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Qwen 3.5 27B против 35B-A3B: локальное тестирование с 16 ГБ видеопамяти в качестве 4k
У нас вы можете посмотреть бесплатно Qwen 3.5 27B против 35B-A3B: локальное тестирование с 16 ГБ видеопамяти или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Qwen 3.5 27B против 35B-A3B: локальное тестирование с 16 ГБ видеопамяти в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Qwen 3.5 27B против 35B-A3B: локальное тестирование с 16 ГБ видеопамяти
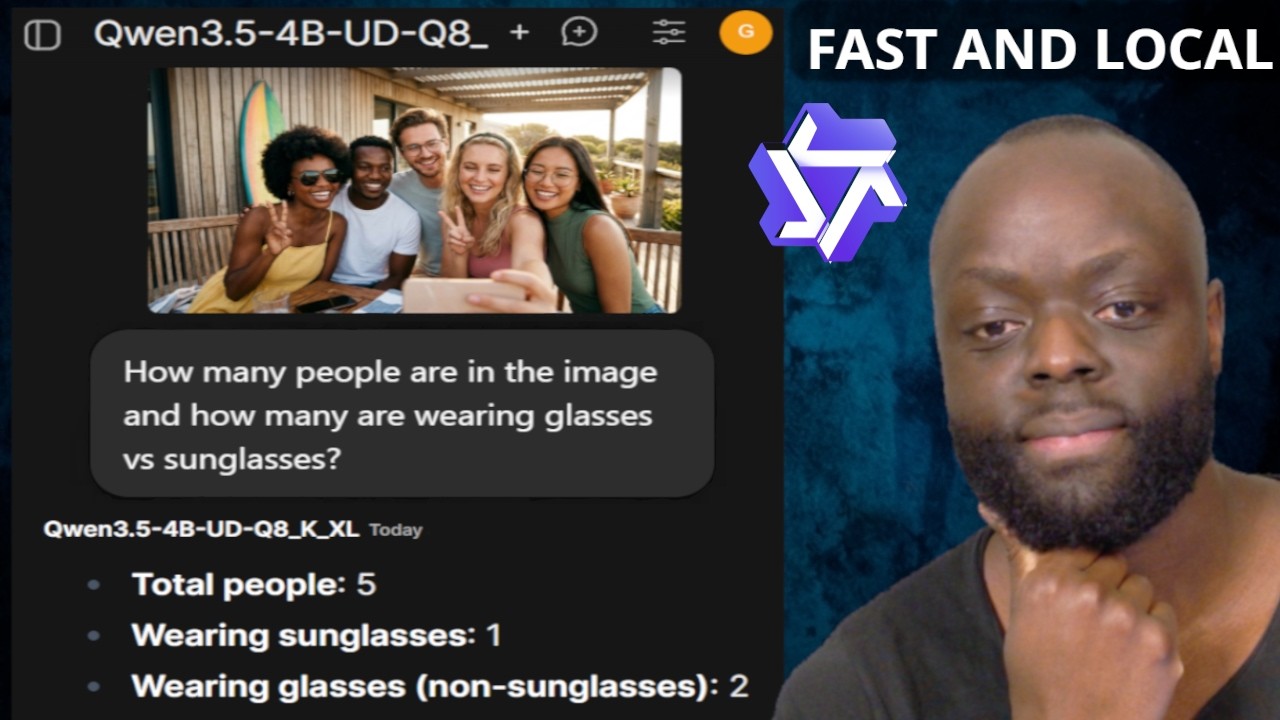
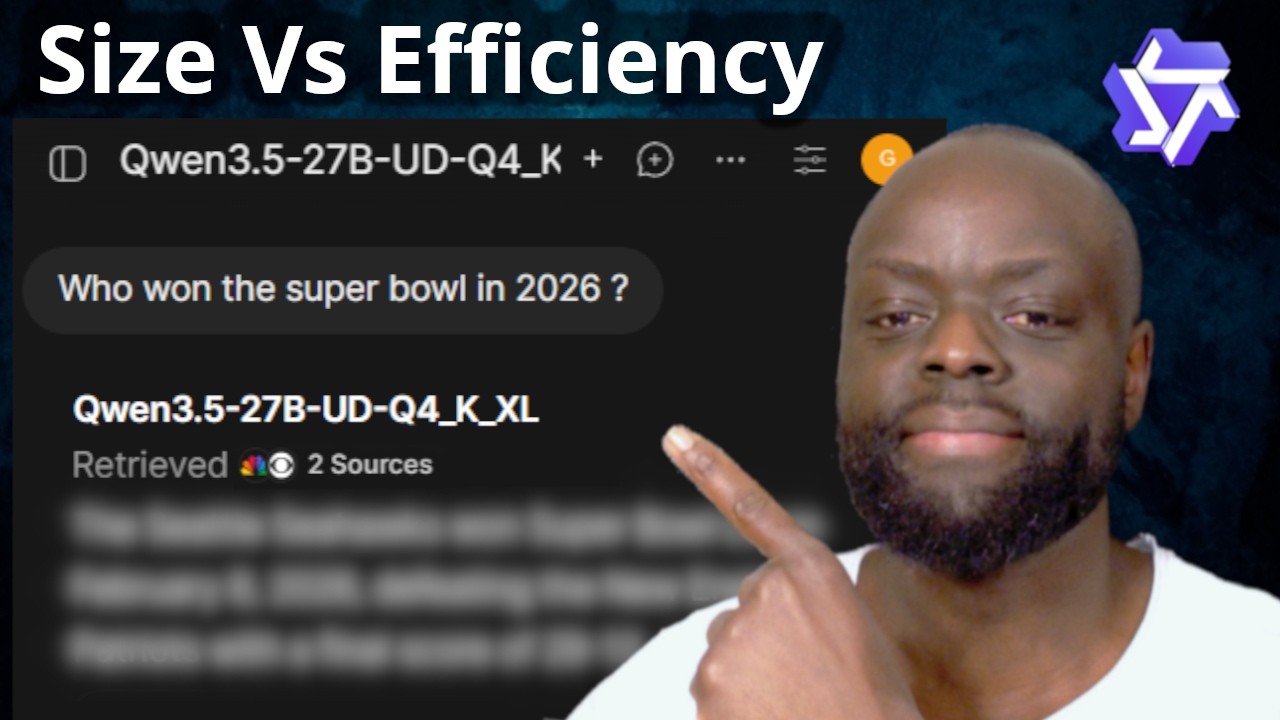
Запускайте самые современные LLM-модели с открытым исходным кодом локально! В этом видео я подвергну совершенно новые модели Qwen 3.5 27B (Dense) и 35B-A3B (Mixture of Experts) самому серьезному тесту. Я покажу вам, как эти модели конкурируют с проприетарными гигантами в области программирования, логического мышления и компьютерного зрения, и продемонстрирую их производительность на стандартном потребительском графическом процессоре всего с 16 ГБ видеопамяти. Я потратил время на тестирование этих моделей в 8 различных сценариях, от программирования 3D-игр для браузера на Three.js до сложного визуального анализа и вызова инструментов веб-поиска с помощью tavily, чтобы определить, какая из них лучше всего подходит для вашей повседневной работы. Что вы узнаете из этого урока: ✅ Архитектурные различия между Qwen 3.5 27B (Dense) и 35B-A3B (Mixture of Experts). ✅ Как запускать локально модели с более чем 30 миллиардами параметров, используя llama.cpp и Open WebUI. ✅ Тестирование кода в реальных условиях, включая полноценное портфолио на одной странице и интерактивную 3D-игру. ✅ Доведение до предела возможностей креативного письма и строгого соблюдения системных подсказок. ✅ Оценка парсинга документов (PDF) и вызова инструментов в реальном времени (веб-поиск с помощью Tavily). ✅ Тестирование возможностей мультимодального зрения на сложных групповых фотографиях. Используемые инструменты и модели: llama.cpp: Лучший механизм вывода для локального запуска моделей GGUF. Open WebUI: Для удобного интерфейса, похожего на ChatGPT, и встроенной обертки для веб-поиска. API Tavily: Для выполнения запросов веб-поиска во время наших тестов вызова инструментов. Qwen 3.5 27B: Традиционная, плотная и мощная модель. Qwen 3.5 35B-A3B: Высокоэффективная модель с разреженным смешиванием экспертов (MoE). Характеристики ПК: Видеокарта: Nvidia RTX 5060 Ti 16 ГБ: https://amzn.to/4rU7xRy Оперативная память: 64 ГБ 4x16 ГБ Kingston Fury: https://amzn.to/473HoaG Используемая модель: Qwen3.5-27B-UD-Q4_K_XL (GGUF) Qwen3.5-35B-A3B-UD-Q4_K_XL (GGUF) Совет: Если вам нужна невероятно высокая скорость, выбирайте модель 35B-A3B MoE! Поскольку в процессе вывода активируется всего 3 миллиарда параметров, вы получаете скорость генерации, сравнимую с крошечной моделью (более 40 токенов в секунду), но с глубокими возможностями анализа, сравнимыми с масштабной моделью с 35 миллиардами параметров. Если это сравнение моделей LLM оказалось для вас полезным, не забудьте поставить лайк, подписаться и нажать на колокольчик уведомлений, чтобы получать больше подробных обзоров инструментов и моделей на основе ИИ! Instagram: / kintugk X: https://x.com/gk_kintu Контакты: kintutech@gmail.com Временные метки: 0:00 - Вступление и характеристики оборудования 1:10 - Обзор модели и архитектуры Qwen 3.5 3:40 - Настройка пользовательского интерфейса (Llama.cpp и Open WebUI) 5:17 - Тест 1: Создание HTML/CSS портфолио 8:05 - Тест 2: Создание 3D браузерной игры (Three.js) 10:10 - Тест 3: Творческое письмо и ограничения 11:22 - Тест 4: Соблюдение системных подсказок (Dog AI) 14:06 - Тест 5: Генерация интерактивных HTML-уроков 17:05 - Тест 6: Анализ и суммирование PDF-файлов 18:46 - Тест 7: Мультимодальное зрение Возможности 20:07 - Тест 8: Вызов инструментов и веб-поиск 20:57 - Заключительные мысли и заключение Учебное пособие по перемещению Wan: • Wan Move - Image2Video - Video Motion to I... #Qwen #LocalLLM #OpenSourceAI #LlamaCPP #MachineLearning #AITutorial #Nvidia5060Ti #CodingAI #MixtureOfExperts #AIWorkflow #Qwen3_5
Comments