–Ш–Ј–Њ–±—А–∞–ґ–µ–љ–Є–µ —Б—В–Њ–Є—В 16x16 —Б–ї–Њ–≤: –Ґ—А–∞–љ—Б—Д–Њ—А–Љ–µ—А—Л –і–ї—П –Љ–∞—Б—И—В–∞–±–љ–Њ–≥–Њ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П –Є–Ј–Њ–±—А–∞–ґ–µ–љ–Є–є (—Б –њ–Њ—П—Б–љ–µ–љ–Є—П... —Б–Ї–∞—З–∞—В—М –≤ —Е–Њ—А–Њ—И–µ–Љ –Ї–∞—З–µ—Б—В–≤–µ
–Ш–Ј–Њ–±—А–∞–ґ–µ–љ–Є–µ —Б—В–Њ–Є—В 16x16 —Б–ї–Њ–≤: –Ґ—А–∞–љ—Б—Д–Њ—А–Љ–µ—А—Л –і–ї—П –Љ–∞—Б—И—В–∞–±–љ–Њ–≥–Њ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П –Є–Ј–Њ–±—А–∞–ґ–µ–љ–Є–є (—Б –њ–Њ—П—Б–љ–µ–љ–Є—П...
5 –ї–µ—В –љ–∞–Ј–∞–і
–Э–µ —Г–і–∞–µ—В—Б—П –Ј–∞–≥—А—Г–Ј–Є—В—М Youtube-–њ–ї–µ–µ—А. –Я—А–Њ–≤–µ—А—М—В–µ –±–ї–Њ–Ї–Є—А–Њ–≤–Ї—Г Youtube –≤ –≤–∞—И–µ–є —Б–µ—В–Є.
–Я–Њ–≤—В–Њ—А—П–µ–Љ –њ–Њ–њ—Л—В–Ї—Г...
–Я–Њ–≤—В–Њ—А—П–µ–Љ –њ–Њ–њ—Л—В–Ї—Г...
–°–Ї–∞—З–∞—В—М –≤–Є–і–µ–Њ —Б —О—В—Г–± –њ–Њ —Б—Б—Л–ї–Ї–µ –Є–ї–Є —Б–Љ–Њ—В—А–µ—В—М –±–µ–Ј –±–ї–Њ–Ї–Є—А–Њ–≤–Њ–Ї –љ–∞ —Б–∞–є—В–µ: –Ш–Ј–Њ–±—А–∞–ґ–µ–љ–Є–µ —Б—В–Њ–Є—В 16x16 —Б–ї–Њ–≤: –Ґ—А–∞–љ—Б—Д–Њ—А–Љ–µ—А—Л –і–ї—П –Љ–∞—Б—И—В–∞–±–љ–Њ–≥–Њ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П –Є–Ј–Њ–±—А–∞–ґ–µ–љ–Є–є (—Б –њ–Њ—П—Б–љ–µ–љ–Є—П... –≤ –Ї–∞—З–µ—Б—В–≤–µ 4k
–£ –љ–∞—Б –≤—Л –Љ–Њ–ґ–µ—В–µ –њ–Њ—Б–Љ–Њ—В—А–µ—В—М –±–µ—Б–њ–ї–∞—В–љ–Њ –Ш–Ј–Њ–±—А–∞–ґ–µ–љ–Є–µ —Б—В–Њ–Є—В 16x16 —Б–ї–Њ–≤: –Ґ—А–∞–љ—Б—Д–Њ—А–Љ–µ—А—Л –і–ї—П –Љ–∞—Б—И—В–∞–±–љ–Њ–≥–Њ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П –Є–Ј–Њ–±—А–∞–ґ–µ–љ–Є–є (—Б –њ–Њ—П—Б–љ–µ–љ–Є—П... –Є–ї–Є —Б–Ї–∞—З–∞—В—М –≤ –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ–Љ –і–Њ—Б—В—Г–њ–љ–Њ–Љ –Ї–∞—З–µ—Б—В–≤–µ, –≤–Є–і–µ–Њ –Ї–Њ—В–Њ—А–Њ–µ –±—Л–ї–Њ –Ј–∞–≥—А—Г–ґ–µ–љ–Њ –љ–∞ —О—В—Г–±. –Ф–ї—П –Ј–∞–≥—А—Г–Ј–Ї–Є –≤—Л–±–µ—А–Є—В–µ –≤–∞—А–Є–∞–љ—В –Є–Ј —Д–Њ—А–Љ—Л –љ–Є–ґ–µ:
-
–Ш–љ—Д–Њ—А–Љ–∞—Ж–Є—П –њ–Њ –Ј–∞–≥—А—Г–Ј–Ї–µ:
–°–Ї–∞—З–∞—В—М mp3 —Б —О—В—Г–±–∞ –Њ—В–і–µ–ї—М–љ—Л–Љ —Д–∞–є–ї–Њ–Љ. –С–µ—Б–њ–ї–∞—В–љ—Л–є —А–Є–љ–≥—В–Њ–љ –Ш–Ј–Њ–±—А–∞–ґ–µ–љ–Є–µ —Б—В–Њ–Є—В 16x16 —Б–ї–Њ–≤: –Ґ—А–∞–љ—Б—Д–Њ—А–Љ–µ—А—Л –і–ї—П –Љ–∞—Б—И—В–∞–±–љ–Њ–≥–Њ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П –Є–Ј–Њ–±—А–∞–ґ–µ–љ–Є–є (—Б –њ–Њ—П—Б–љ–µ–љ–Є—П... –≤ —Д–Њ—А–Љ–∞—В–µ MP3:
–Х—Б–ї–Є –Ї–љ–Њ–њ–Ї–Є —Б–Ї–∞—З–Є–≤–∞–љ–Є—П –љ–µ
–Ј–∞–≥—А—Г–Ј–Є–ї–Є—Б—М
–Э–Р–Ц–Ь–Ш–Ґ–Х –Ч–Ф–Х–°–ђ –Є–ї–Є –Њ–±–љ–Њ–≤–Є—В–µ —Б—В—А–∞–љ–Є—Ж—Г
–Х—Б–ї–Є –≤–Њ–Ј–љ–Є–Ї–∞—О—В –њ—А–Њ–±–ї–µ–Љ—Л —Б–Њ —Б–Ї–∞—З–Є–≤–∞–љ–Є–µ–Љ –≤–Є–і–µ–Њ, –њ–Њ–ґ–∞–ї—Г–є—Б—В–∞ –љ–∞–њ–Є—И–Є—В–µ –≤ –њ–Њ–і–і–µ—А–ґ–Ї—Г –њ–Њ –∞–і—А–µ—Б—Г –≤–љ–Є–Ј—Г
—Б—В—А–∞–љ–Є—Ж—Л.
–°–њ–∞—Б–Є–±–Њ –Ј–∞ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ —Б–µ—А–≤–Є—Б–∞ ClipSaver.ru
–Ш–Ј–Њ–±—А–∞–ґ–µ–љ–Є–µ —Б—В–Њ–Є—В 16x16 —Б–ї–Њ–≤: –Ґ—А–∞–љ—Б—Д–Њ—А–Љ–µ—А—Л –і–ї—П –Љ–∞—Б—И—В–∞–±–љ–Њ–≥–Њ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П –Є–Ј–Њ–±—А–∞–ґ–µ–љ–Є–є (—Б –њ–Њ—П—Б–љ–µ–љ–Є—П...
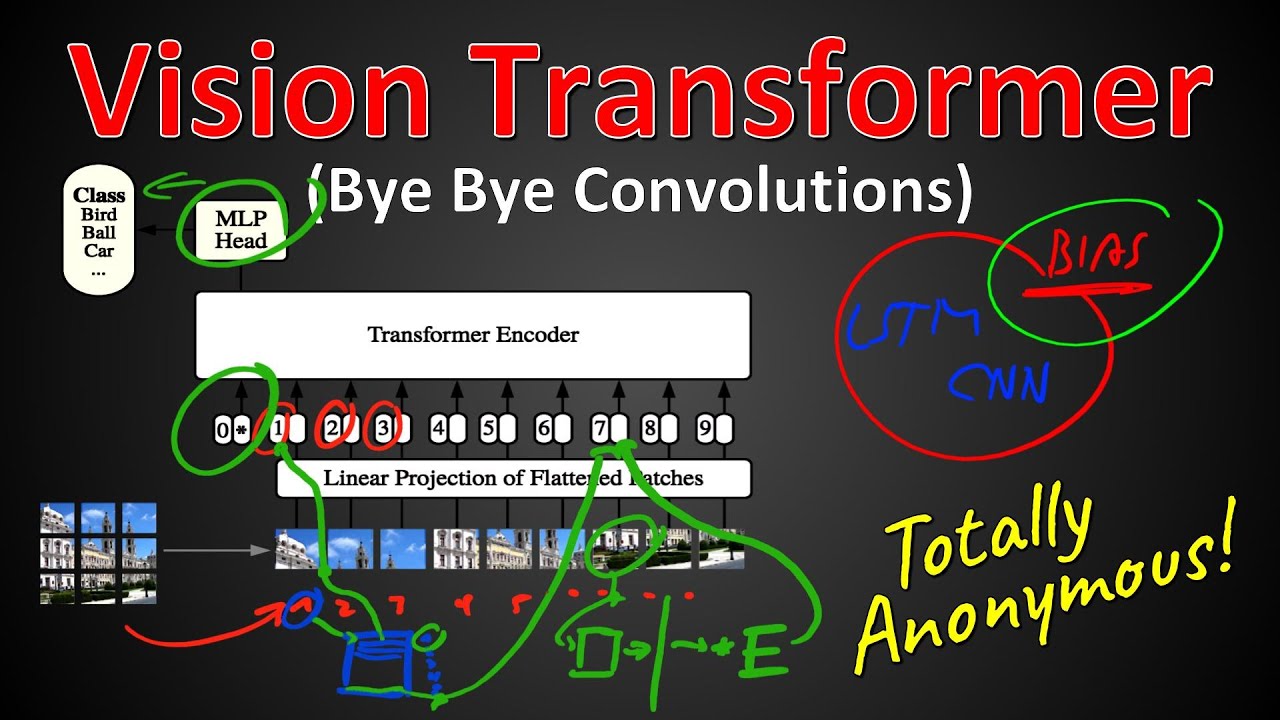
#–Ш–Ш #–Є—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є—П #—В—А–∞–љ—Б—Д–Њ—А–Љ–µ—А—Л –Ґ—А–∞–љ—Б—Д–Њ—А–Љ–µ—А—Л –њ–Њ—А—В—П—В —Б–≤—С—А—В–Ї–Є. –Т —Н—В–Њ–є —Б—В–∞—В—М–µ, –љ–∞—Е–Њ–і—П—Й–µ–є—Б—П –љ–∞ —А–∞—Б—Б–Љ–Њ—В—А–µ–љ–Є–Є –≤ ICLR, –њ–Њ–Ї–∞–Ј–∞–љ–Њ, —З—В–Њ –њ—А–Є –љ–∞–ї–Є—З–Є–Є –і–Њ—Б—В–∞—В–Њ—З–љ–Њ–≥–Њ –Ї–Њ–ї–Є—З–µ—Б—В–≤–∞ –і–∞–љ–љ—Л—Е —Б—В–∞–љ–і–∞—А—В–љ—Л–є —В—А–∞–љ—Б—Д–Њ—А–Љ–µ—А –Љ–Њ–ґ–µ—В –њ—А–µ–≤–Ј–Њ–є—В–Є —Б–≤—С—А—В–Њ—З–љ—Л–µ –љ–µ–є—А–Њ–љ–љ—Л–µ —Б–µ—В–Є –≤ –Ј–∞–і–∞—З–∞—Е —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П –Є–Ј–Њ–±—А–∞–ґ–µ–љ–Є–є, –≤ –Ї–Њ—В–Њ—А—Л—Е –Ї–ї–∞—Б—Б–Є—З–µ—Б–Ї–Є –њ—А–µ—Г—Б–њ–µ–≤–∞—О—В —Б–≤–µ—А—В–Њ—З–љ—Л–µ –љ–µ–є—А–Њ–љ–љ—Л–µ —Б–µ—В–Є. –Т —Н—В–Њ–Љ –≤–Є–і–µ–Њ —П –Њ–±—К—П—Б–љ—П—О –∞—А—Е–Є—В–µ–Ї—В—Г—А—Г Vision Transformer (ViT), –Њ–±—К—П—Б–љ—П—О, –њ–Њ—З–µ–Љ—Г –Њ–љ —А–∞–±–Њ—В–∞–µ—В –ї—Г—З—И–µ, –Є –Ї—А–Є—В–Є–Ї—Г—О, –њ–Њ—З–µ–Љ—Г –і–≤—Г—Е—Б—В—А–Њ—З–љ–∞—П —Н–Ї—Б–њ–µ—А—В–љ–∞—П –Њ—Ж–µ–љ–Ї–∞ –љ–µ —А–∞–±–Њ—В–∞–µ—В. –Я–Ы–Р–Э: 0:00 - –Т–≤–µ–і–µ–љ–Є–µ 0:30 - –Ф–≤–Њ–є–љ–Њ–µ —Б–ї–µ–њ–Њ–µ —А–µ—Ж–µ–љ–Ј–Є—А–Њ–≤–∞–љ–Є–µ –љ–µ —А–∞–±–Њ—В–∞–µ—В 5:20 - –Ю–±–Ј–Њ—А 6:55 - –Ґ—А–∞–љ—Б—Д–Њ—А–Љ–µ—А—Л –і–ї—П –Є–Ј–Њ–±—А–∞–ґ–µ–љ–Є–є 10:40 - –Р—А—Е–Є—В–µ–Ї—В—Г—А–∞ Vision Transformer 16:30 - –≠–Ї—Б–њ–µ—А–Є–Љ–µ–љ—В–∞–ї—М–љ—Л–µ —А–µ–Ј—Г–ї—М—В–∞—В—Л 18:45 - –І–µ–Љ—Г —Г—З–Є—В—Б—П –Љ–Њ–і–µ–ї—М? 21:00 - –Я–Њ—З–µ–Љ—Г —В—А–∞–љ—Б—Д–Њ—А–Љ–∞—В–Њ—А—Л –≤—Б—С –њ–Њ—А—В—П—В 27:45 - –Ш–љ–і—Г–Ї—В–Є–≤–љ—Л–µ —Б–Љ–µ—Й–µ–љ–Є—П –≤ —В—А–∞–љ—Б—Д–Њ—А–Љ–∞—В–Њ—А–∞—Е 29:05 - –Ч–∞–Ї–ї—О—З–µ–љ–Є–µ –Є –Ї–Њ–Љ–Љ–µ–љ—В–∞—А–Є–Є –°—В–∞—В—М—П (–љ–∞ —А–∞—Б—Б–Љ–Њ—В—А–µ–љ–Є–Є): https://openreview.net/forum?id=YicbF... –Т–µ—А—Б–Є—П Arxiv: https://arxiv.org/abs/2010.11929 –°—В–∞—В—М—П BiT: https://arxiv.org/pdf/1912.11370.pdf –°—В–∞—В—М—П ImageNet-ReaL: https://arxiv.org/abs/2006.07159 –Ь–Њ—С –≤–Є–і–µ–Њ –Њ BiT (Big Transfer): ¬†¬†¬†вАҐ¬†Big¬†Transfer¬†(BiT):¬†General¬†Visual¬†Represe...¬†¬† –Ь–Њ—С –≤–Є–і–µ–Њ –Њ —В—А–∞–љ—Б—Д–Њ—А–Љ–∞—В–Њ—А–∞—Е: ¬†¬†¬†вАҐ¬†Attention¬†Is¬†All¬†You¬†Need¬†¬† –Ь–Њ—С –≤–Є–і–µ–Њ –Њ BERT: ¬†¬†¬†вАҐ¬†BERT:¬†Pre-training¬†of¬†Deep¬†Bidirectional¬†T...¬†¬† –Ь–Њ—С –≤–Є–і–µ–Њ –Њ ResNets: ¬†¬†¬†вАҐ¬†[Classic]¬†Deep¬†Residual¬†Learning¬†for¬†Image...¬†¬† –Р–љ–љ–Њ—В–∞—Ж–Є—П: –•–Њ—В—П –∞—А—Е–Є—В–µ–Ї—В—Г—А–∞ Transformer —Б—В–∞–ї–∞ —Д–∞–Ї—В–Є—З–µ—Б–Ї–Є–Љ —Б—В–∞–љ–і–∞—А—В–Њ–Љ –і–ї—П –Ј–∞–і–∞—З –Њ–±—А–∞–±–Њ—В–Ї–Є –µ—Б—В–µ—Б—В–≤–µ–љ–љ–Њ–≥–Њ —П–Ј—Л–Ї–∞, –µ—С –њ—А–Є–Љ–µ–љ–µ–љ–Є–µ –≤ –Ї–Њ–Љ–њ—М—О—В–µ—А–љ–Њ–Љ –Ј—А–µ–љ–Є–Є –Њ—Б—В–∞—С—В—Б—П –Њ–≥—А–∞–љ–Є—З–µ–љ–љ—Л–Љ. –Т –Ј—А–µ–љ–Є–Є –≤–љ–Є–Љ–∞–љ–Є–µ –ї–Є–±–Њ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П —Б–Њ–≤–Љ–µ—Б—В–љ–Њ —Б–Њ —Б–≤—С—А—В–Њ—З–љ—Л–Љ–Є —Б–µ—В—П–Љ–Є, –ї–Є–±–Њ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П –і–ї—П –Ј–∞–Љ–µ–љ—Л –Њ—В–і–µ–ї—М–љ—Л—Е –Ї–Њ–Љ–њ–Њ–љ–µ–љ—В–Њ–≤ —Б–≤—С—А—В–Њ—З–љ—Л—Е —Б–µ—В–µ–є —Б —Б–Њ—Е—А–∞–љ–µ–љ–Є–µ–Љ –Є—Е –Њ–±—Й–µ–є —Б—В—А—Г–Ї—В—Г—А—Л. –Ь—Л –њ–Њ–Ї–∞–Ј—Л–≤–∞–µ–Љ, —З—В–Њ —В–∞–Ї–∞—П –Ј–∞–≤–Є—Б–Є–Љ–Њ—Б—В—М –Њ—В —Б–≤–µ—А—В–Њ—З–љ—Л—Е –љ–µ–є—А–Њ–љ–љ—Л—Е —Б–µ—В–µ–є –љ–µ —П–≤–ї—П–µ—В—Б—П –Њ–±—П–Ј–∞—В–µ–ї—М–љ–Њ–є, –Є —З–Є—Б—В—Л–є Transformer –Љ–Њ–ґ–µ—В –Њ—З–µ–љ—М —Е–Њ—А–Њ—И–Њ —Б–њ—А–∞–≤–ї—П—В—М—Б—П —Б –Ј–∞–і–∞—З–∞–Љ–Є –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—Ж–Є–Є –Є–Ј–Њ–±—А–∞–ґ–µ–љ–Є–є –њ—А–Є –њ—А–Є–Љ–µ–љ–µ–љ–Є–Є –љ–µ–њ–Њ—Б—А–µ–і—Б—В–≤–µ–љ–љ–Њ –Ї –њ–Њ—Б–ї–µ–і–Њ–≤–∞—В–µ–ї—М–љ–Њ—Б—В—П–Љ —Д—А–∞–≥–Љ–µ–љ—В–Њ–≤ –Є–Ј–Њ–±—А–∞–ґ–µ–љ–Є–є. –Я–Њ—Б–ї–µ –њ—А–µ–і–Њ–±—Г—З–µ–љ–Є—П –љ–∞ –±–Њ–ї—М—И–Є—Е –Њ–±—К—С–Љ–∞—Е –і–∞–љ–љ—Л—Е –Є –њ–µ—А–µ–љ–Њ—Б–∞ –љ–∞ –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –±–µ–љ—З–Љ–∞—А–Ї–Њ–≤ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П (ImageNet, CIFAR-100, VTAB –Є —В. –і.) Vision Transformer –і–µ–Љ–Њ–љ—Б—В—А–Є—А—Г–µ—В –њ—А–µ–≤–Њ—Б—Е–Њ–і–љ—Л–µ —А–µ–Ј—Г–ї—М—В–∞—В—Л –њ–Њ —Б—А–∞–≤–љ–µ–љ–Є—О —Б —Б–Њ–≤—А–µ–Љ–µ–љ–љ—Л–Љ–Є —Б–≤—С—А—В–Њ—З–љ—Л–Љ–Є —Б–µ—В—П–Љ–Є, –њ—А–Є —Н—В–Њ–Љ —В—А–µ–±—Г—П —Б—Г—Й–µ—Б—В–≤–µ–љ–љ–Њ –Љ–µ–љ—М—И–µ –≤—Л—З–Є—Б–ї–Є—В–µ–ї—М–љ—Л—Е —А–µ—Б—Г—А—Б–Њ–≤ –і–ї—П –Њ–±—Г—З–µ–љ–Є—П. –Р–≤—В–Њ—А—Л: –Р–љ–Њ–љ–Є–Љ / –Э–∞ —А–∞—Б—Б–Љ–Њ—В—А–µ–љ–Є–Є –Ш—Б–њ—А–∞–≤–ї–µ–љ–Є—П: –Я–∞—В—З–Є –љ–µ —Б–≤–µ–і–µ–љ—Л, –∞ –≤–µ–Ї—В–Њ—А–Є–Ј–Њ–≤–∞–љ—Л –°—Б—Л–ї–Ї–Є: YouTube: ¬†¬†¬†/¬†yannickilcher¬†¬† Twitter: ¬†¬†/¬†ykilcher¬†¬† Discord: ¬†¬†/¬†discord¬†¬† BitChute: https://www.bitchute.com/channel/yann... Minds: https://www.minds.com/ykilcher Parler: https://parler.com/profile/YannicKilcher LinkedIn: ¬†¬†/¬†yannic-kilcher-488534136¬†¬† –Х—Б–ї–Є —Е–Њ—В–Є—В–µ –њ–Њ–і–і–µ—А–ґ–∞—В—М –Љ–µ–љ—П, –ї—Г—З—И–µ –≤—Б–µ–≥–Њ –њ–Њ–і–µ–ї–Є—В—М—Б—П –Ї–Њ–љ—В–µ–љ—В–Њ–Љ :) –Х—Б–ї–Є —Е–Њ—В–Є—В–µ –њ–Њ–і–і–µ—А–ґ–∞—В—М –Љ–µ–љ—П —Д–Є–љ–∞–љ—Б–Њ–≤–Њ (—Н—В–Њ —Б–Њ–≤–µ—А—И–µ–љ–љ–Њ –љ–µ–Њ–±—П–Ј–∞—В–µ–ї—М–љ–Њ –Є –і–Њ–±—А–Њ–≤–Њ–ї—М–љ–Њ, –љ–Њ –Љ–љ–Њ–≥–Є–µ –њ—А–Њ—Б–Є–ї–Є –Њ–± —Н—В–Њ–Љ): SubscribeStar: https://www.subscribestar.com/yannick... Patreon: ¬†¬†/¬†yannickilcher¬†¬† –С–Є—В–Ї–Њ–є–љ (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq –≠—Д–Є—А–Є—Г–Љ (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2 –Ы–∞–є—В–Ї–Њ–є–љ (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m –Ь–Њ–љ–µ—А–Њ (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
Comments
-
 5 –ї–µ—В –љ–∞–Ј–∞–і
5 –ї–µ—В –љ–∞–Ј–∞–і
-
 1 –≥–Њ–і –љ–∞–Ј–∞–і
1 –≥–Њ–і –љ–∞–Ј–∞–і
-
 2 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
2 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
-
 4 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
4 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
-
![[–Р–љ–∞–ї–Є–Ј —Б—В–∞—В—М–Є] –Ю —В–µ–Њ—А–µ—В–Є—З–µ—Б–Ї–Є—Е –Њ–≥—А–∞–љ–Є—З–µ–љ–Є—П—Е –њ–Њ–Є—Б–Ї–∞ –љ–∞ –Њ—Б–љ–Њ–≤–µ –≤—Б—В—А–∞–Є–≤–∞–љ–Є—П (–Я—А–µ–і—Г–њ—А–µ–ґ–і–µ–љ–Є–µ: –Ї—А–Є—В–Є–Ї–∞)](https://imager.clipsaver.ru/zKohTkN0Fyk/max.jpg) 4 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
4 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
-
 4 –і–љ—П –љ–∞–Ј–∞–і
4 –і–љ—П –љ–∞–Ј–∞–і
-
 1 –Љ–µ—Б—П—Ж –љ–∞–Ј–∞–і
1 –Љ–µ—Б—П—Ж –љ–∞–Ј–∞–і
-
 11 –і–љ–µ–є –љ–∞–Ј–∞–і
11 –і–љ–µ–є –љ–∞–Ј–∞–і
-
 4 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
4 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
-
![[Classic] Deep Residual Learning for Image Recognition (Paper Explained)](https://imager.clipsaver.ru/GWt6Fu05voI/max.jpg) 5 –ї–µ—В –љ–∞–Ј–∞–і
5 –ї–µ—В –љ–∞–Ј–∞–і
-
![[Classic] Generative Adversarial Networks (Paper Explained)](https://imager.clipsaver.ru/eyxmSmjmNS0/max.jpg) 5 –ї–µ—В –љ–∞–Ј–∞–і
5 –ї–µ—В –љ–∞–Ј–∞–і
-
 4 –і–љ—П –љ–∞–Ј–∞–і
4 –і–љ—П –љ–∞–Ј–∞–і
-

-
![How AI Taught Itself to See [DINOv3]](https://imager.clipsaver.ru/oGTasd3cliM/max.jpg) 6 –Љ–µ—Б—П—Ж–µ–≤ –љ–∞–Ј–∞–і
6 –Љ–µ—Б—П—Ж–µ–≤ –љ–∞–Ј–∞–і
-
 8 –ї–µ—В –љ–∞–Ј–∞–і
8 –ї–µ—В –љ–∞–Ј–∞–і
-
 1 –і–µ–љ—М –љ–∞–Ј–∞–і
1 –і–µ–љ—М –љ–∞–Ј–∞–і
-
 1 –і–µ–љ—М –љ–∞–Ј–∞–і
1 –і–µ–љ—М –љ–∞–Ј–∞–і
-
 4 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
4 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
-
 2 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
2 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
-
 3 –љ–µ–і–µ–ї–Є –љ–∞–Ј–∞–і
3 –љ–µ–і–µ–ї–Є –љ–∞–Ј–∞–і