[RL] Reinforcement Learning for Large Reasoning Models (LRMs/ LLM): A Survey. скачать в хорошем качестве
[RL] Reinforcement Learning for Large Reasoning Models (LRMs/ LLM): A Survey.
5 месяцев назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
![[RL] Reinforcement Learning for Large Reasoning Models (LRMs/ LLM): A Survey.](https://imager.clipsaver.ru/UIhYke7UbUM/max.jpg)
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: [RL] Reinforcement Learning for Large Reasoning Models (LRMs/ LLM): A Survey. в качестве 4k
У нас вы можете посмотреть бесплатно [RL] Reinforcement Learning for Large Reasoning Models (LRMs/ LLM): A Survey. или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон [RL] Reinforcement Learning for Large Reasoning Models (LRMs/ LLM): A Survey. в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
[RL] Reinforcement Learning for Large Reasoning Models (LRMs/ LLM): A Survey.
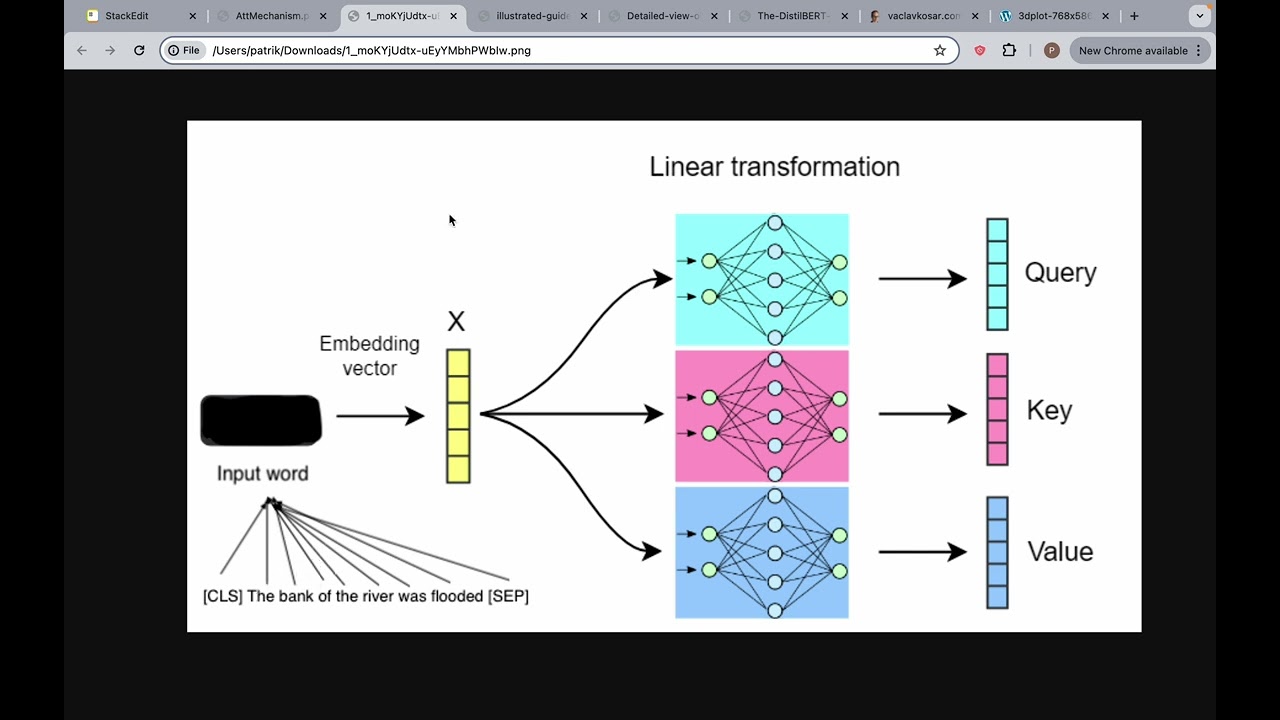
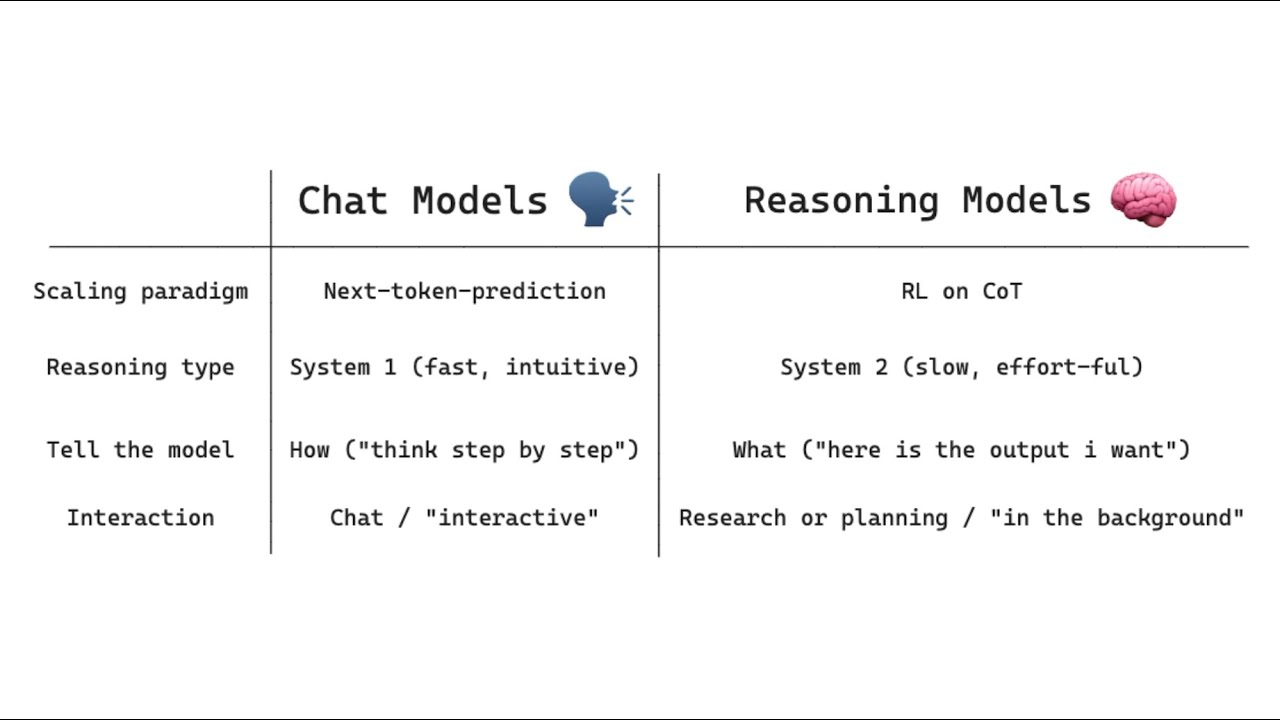
Reinforcement Learning for Large Reasoning Models: A Survey This survey explores recent advancements in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs), particularly as they evolve into Large Reasoning Models (LRMs) for tasks like mathematics and coding. It examines foundational elements such as reward design, including verifiable, generative, dense, and unsupervised rewards, along with different policy optimization algorithms like critic-based and critic-free approaches. The text also covers training resources, from static datasets to dynamic environments and specialized RL infrastructure, and highlights key applications in areas such as coding, agentic tasks, multimodal understanding and generation, multi-agent systems, robotics, and medical reasoning. Finally, it addresses future research directions and persistent challenges related to scalability, stability, and generalization in this rapidly developing field.
Comments
















![[AlphaFold to AlphaGenome] От сворачивания белков к расшифровке жизни. От Evoformer к U-Net Trans...](https://imager.clipsaver.ru/lA4Oewsv5lA/max.jpg)
