Day 6 | Transformer Architecture Series | The Real Math Behind Self-Attention скачать в хорошем качестве
Day 6 | Transformer Architecture Series | The Real Math Behind Self-Attention
4 часа назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Day 6 | Transformer Architecture Series | The Real Math Behind Self-Attention в качестве 4k
У нас вы можете посмотреть бесплатно Day 6 | Transformer Architecture Series | The Real Math Behind Self-Attention или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Day 6 | Transformer Architecture Series | The Real Math Behind Self-Attention в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Day 6 | Transformer Architecture Series | The Real Math Behind Self-Attention
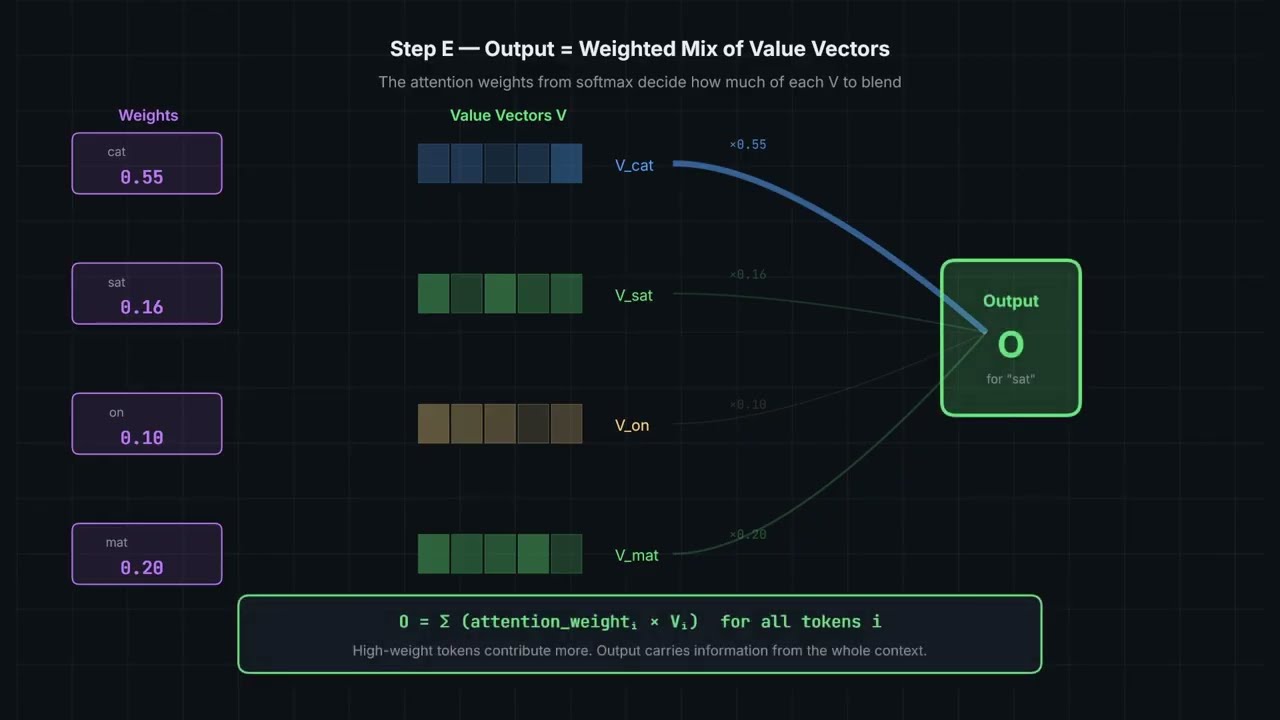
Self-attention isn’t magic—it’s a clean, teachable machine: dot products to score relevance, softmax to turn scores into weights, and a weighted sum of values to mix information across tokens. In this episode we unpack Q, K, V and the full scaled dot-product attention equation, including why the scaling is essential for stable learning.
Comments



















