Clojure REPL Workflow Live Coding Importance Of Being Earnest скачать в хорошем качестве
Clojure REPL Workflow Live Coding Importance Of Being Earnest
2 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Clojure REPL Workflow Live Coding Importance Of Being Earnest в качестве 4k
У нас вы можете посмотреть бесплатно Clojure REPL Workflow Live Coding Importance Of Being Earnest или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Clojure REPL Workflow Live Coding Importance Of Being Earnest в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Clojure REPL Workflow Live Coding Importance Of Being Earnest
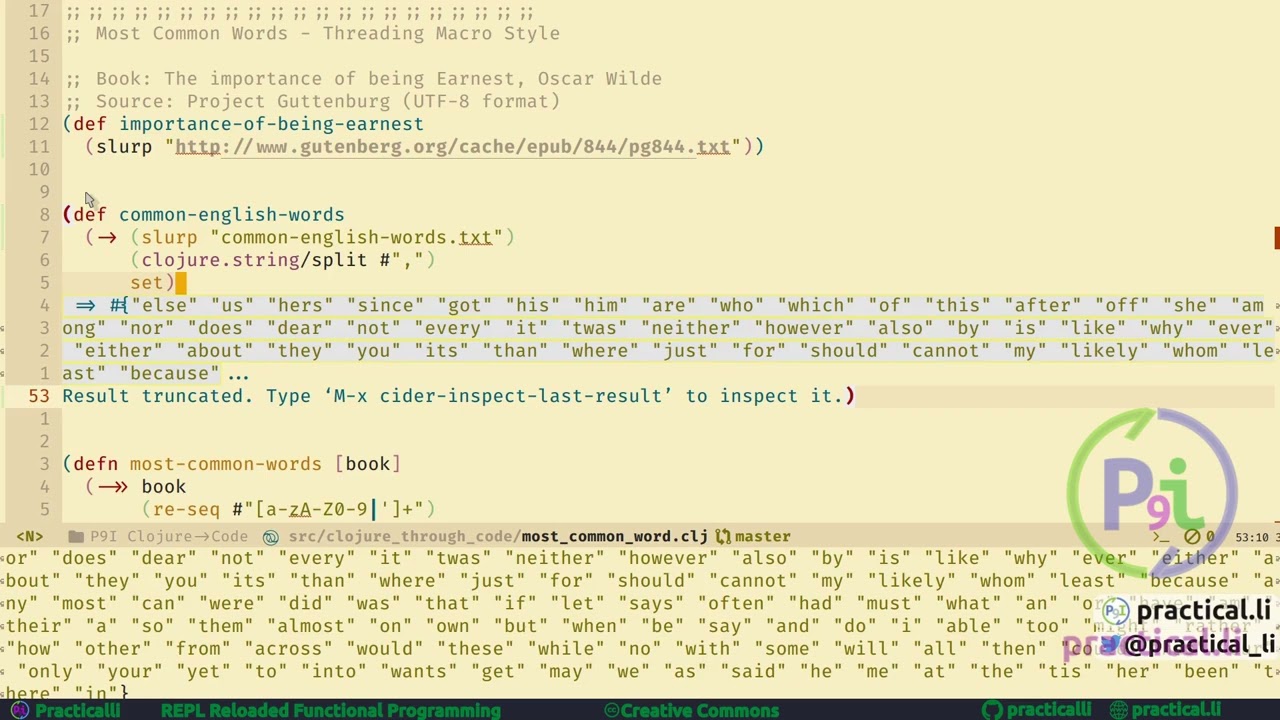
A brief example of the instant feedback given when using the Clojure REPL, via a simple challenge to find the most common word from the book, "The importance of being Ernest". Please note that Project Gutenberg now Gzip's the book texts and serves them over https. The code changes required are in the tutorial https://practical.li/clojure/simple-p... Emacs (Spacemacs config) is used with CIDER to start and connect to a Clojure REPL. To see the code in more detail, the results are pretty printed. Transcript of the video I am using my Clojure editor with a simple project, to find the most common word from a book. The book is the importance of being earnest from project Gutenberg I am slurping in the book from the website, which returns a single string of the entire book text This string is a value bound to the name importance-of-being-earnest, so we can refer to it easily throughout the code We want to eliminate the common English words, otherwise works such as a, the, to, may be the most common word. Slurp is used to get the common English words from a text file, in CSV format The result of that is passed to split, creating individual words Which are put into a set to remove any duplicate words, as sets contain unique values A function is defined to get the most common word, although most of the code is commented, so we can explore what each expression does. This function is called, passing the book as an argument The book is passed into re-seq, which uses a regular expression to create individual words from the book text. All our common English words are in lower case, so transform all the words in the book to match Now we can remove the common English words We have the book in a form where we can start counting how many times a word appears Frequencies creates a new data structure with a count for each book With the word as a key and the frequency the word occurs as the value. Sort by the value to put the result of frequencies in order And reverse the order so we see the biggest at the top. Not surprisingly the results show the most common words are characters names from the book
Comments