[I-JEPA] Joint-Embedding Predictive Architecture (I-JEPA) vs the Transformers (Attention Blocks) скачать в хорошем качестве
[I-JEPA] Joint-Embedding Predictive Architecture (I-JEPA) vs the Transformers (Attention Blocks)
7 месяцев назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
![[I-JEPA] Joint-Embedding Predictive Architecture (I-JEPA) vs the Transformers (Attention Blocks)](https://imager.clipsaver.ru/Y4rMiOD0GH8/max.jpg)
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: [I-JEPA] Joint-Embedding Predictive Architecture (I-JEPA) vs the Transformers (Attention Blocks) в качестве 4k
У нас вы можете посмотреть бесплатно [I-JEPA] Joint-Embedding Predictive Architecture (I-JEPA) vs the Transformers (Attention Blocks) или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон [I-JEPA] Joint-Embedding Predictive Architecture (I-JEPA) vs the Transformers (Attention Blocks) в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
[I-JEPA] Joint-Embedding Predictive Architecture (I-JEPA) vs the Transformers (Attention Blocks)
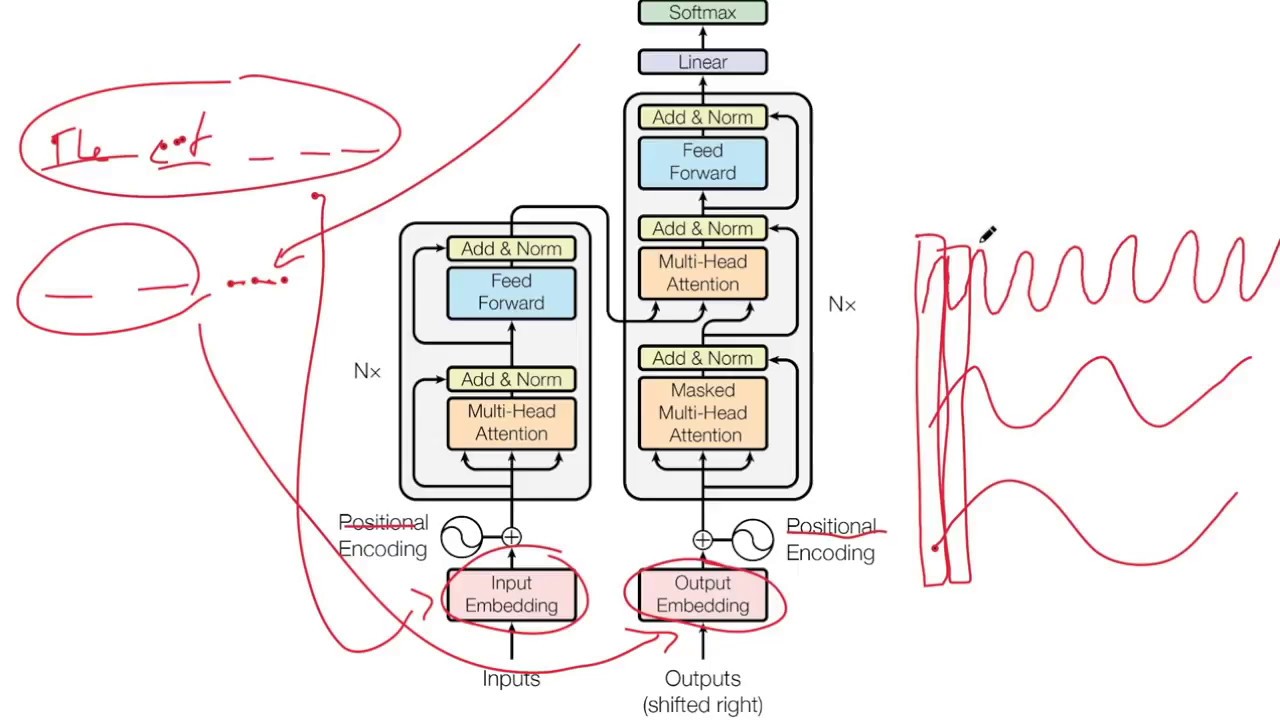
Joint-Embedding Predictive Architecture (I-JEPA) vs the Transformers. The Image-based Joint-Embedding Predictive Architecture (I-JEPA) and the Transformer architecture. I-JEPA: A Predictive Approach for Image Learning The Image-based Joint-Embedding Predictive Architecture (I-JEPA) is a self-supervised learning method designed to create highly semantic image representations without relying on manually designed data augmentations. The core idea is to predict the representations of several target blocks (parts of an image) from a single context block within the same image. The success of this non-generative approach depends on a specific masking strategy: using a large, informative context block to predict other large, semantic target blocks. When paired with a Vision Transformer (ViT), I-JEPA is highly scalable and has demonstrated strong performance on a wide range of tasks, including classification, object counting, and depth prediction. The Transformer: A Foundational Architecture The Transformer is a foundational neural network component used to learn useful representations from sequences or sets of data. It has been the driving force behind recent major advancements in natural language processing (NLP), computer vision, and other fields. While many introductions to the Transformer exist, the source text notes that they often lack precise mathematical descriptions and clear intuitions behind the design. This note's purpose is to provide a clean, mathematically precise, and intuitive explanation of the Transformer architecture itself, assuming the reader has a basic understanding of machine learning fundamentals. V-JPEA, I-JEPA, VL-JEPA
Comments