Summarize Automotive & Healthcare Insurance Calls - Supabase - OpenAI - HuggingFace | LLM Dev Demo скачать в хорошем качестве
Summarize Automotive & Healthcare Insurance Calls - Supabase - OpenAI - HuggingFace | LLM Dev Demo
3 недели назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Summarize Automotive & Healthcare Insurance Calls - Supabase - OpenAI - HuggingFace | LLM Dev Demo в качестве 4k
У нас вы можете посмотреть бесплатно Summarize Automotive & Healthcare Insurance Calls - Supabase - OpenAI - HuggingFace | LLM Dev Demo или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Summarize Automotive & Healthcare Insurance Calls - Supabase - OpenAI - HuggingFace | LLM Dev Demo в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Summarize Automotive & Healthcare Insurance Calls - Supabase - OpenAI - HuggingFace | LLM Dev Demo
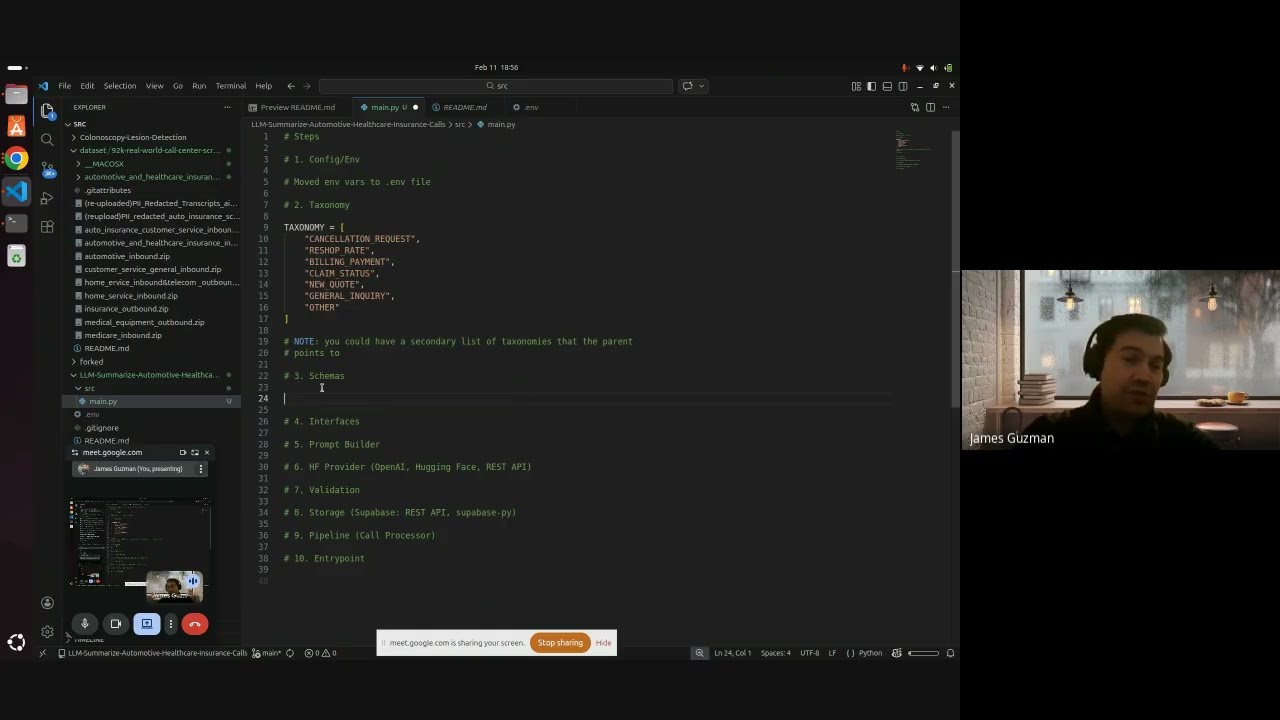
Build a Python LLM Backend to Summarize Insurance Call Transcripts (Hugging Face + OpenAI‑Style API + Supabase): 🚀 In this step‑by‑step tutorial, we build an end‑to‑end Python “LLM backend” that reads real insurance call‑center transcript JSON files, sends them to an LLM through either the Hugging Face Inference API or OpenAI‑style Chat Completions via the Hugging Face Router, parses strict JSON output, and upserts structured summaries into a Supabase Postgres table — all while debugging every step together. 💡 Tip: If your Supabase table doesn’t update immediately, refresh the table editor — the upsert likely succeeded but the UI lagged! You'll see this happen near the end of the video, I stopped the video recording and then realized, I just had to wait and then refresh again and then I saw the table populated with our new call summary row. 📦 GitHub Repo: https://github.com/james94/LLM-Summar... 📚 Dataset: Hugging Face “92k‑real‑world‑call‑center‑scripts‑english” (PII‑redacted), we zone into the "automotive and healthcare insurance inbound" sub dataset. 🎯 What You’ll Learn ● How to set up the project from scratch — create a new GitHub repo, Conda environment, and install dependencies (pydantic, python-dotenv, huggingface_hub, openai, supabase, requests) ● Configure a secure .env file with keys like HF_TOKEN, HF_MODEL_ID, SUPABASE_URL, SUPABASE_SECRET_KEY, and SUPABASE_TABLE ● Define Pydantic schemas (CallEvent, LLMResult, KeyEntities) with safe defaults for imperfect model outputs ● Build robust prompts that enforce JSON‑only structured responses ● Implement two LLM inference clients: 1. Hugging Face InferenceClient 2. OpenAI SDK calling the HF Router (https://router.huggingface.co/v1) ● Parse and validate LLM responses: handle markdown fences, extract clean {…} JSON objects, and apply fallbacks when parsing fails ● Integrate with Supabase using: 1. supabase-py client upserts (easy schema debugging) 2. REST API upserts via requests.post() with retry logic ● Construct the CallProcessor class that connects all components (LLM → structured record → Supabase upsert) ● Run single‑file and batch directory transcript summarizations ● Debug “Supabase lag” issues where new rows appear after a page refresh 🧩 What the Pipeline Produces: Each summarized record includes: ● summary ● intent_label (7‑label taxonomy) ● intent_confidence ● key_entities (policy_number, claim_id, effective_date, amount) ● action_items ● status (open | resolved | follow_up) ● model_raw (metadata + raw response snapshot) 🧠 Why Watch This: You’ll see how to go from creating a new github repo to a fully functional AI summarization backend, complete with structured data validation, robust error handling, and cloud database persistence. Perfect for building customer support analytics, insurance ops automation, or LLM‑powered call insight systems. 🪜 Chapters: ● Intro & goals ● Repo setup & environment creation ● Install dependencies + .env configuration ● Implementing schema models & strict JSON prompt design ● Building dual LLM clients (HF + OpenAI style) ● Parsing outputs & error handling ● Writing to Supabase (REST vs supabase‑py) ● Debugging and solving “Supabase lag” (NOTE: You’ll see us run into in the video, I refreshed supabase website’s table editor and our new upserted call summary row appeared after I stopped the video) ● Final results and next steps
Comments