輝達開放CXL記憶體:打破HBM產能限制,開啟MaaS時代 скачать в хорошем качестве
輝達開放CXL記憶體:打破HBM產能限制,開啟MaaS時代
1 день назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: 輝達開放CXL記憶體:打破HBM產能限制,開啟MaaS時代 в качестве 4k
У нас вы можете посмотреть бесплатно 輝達開放CXL記憶體:打破HBM產能限制,開啟MaaS時代 или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон 輝達開放CXL記憶體:打破HBM產能限制,開啟MaaS時代 в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
輝達開放CXL記憶體:打破HBM產能限制,開啟MaaS時代
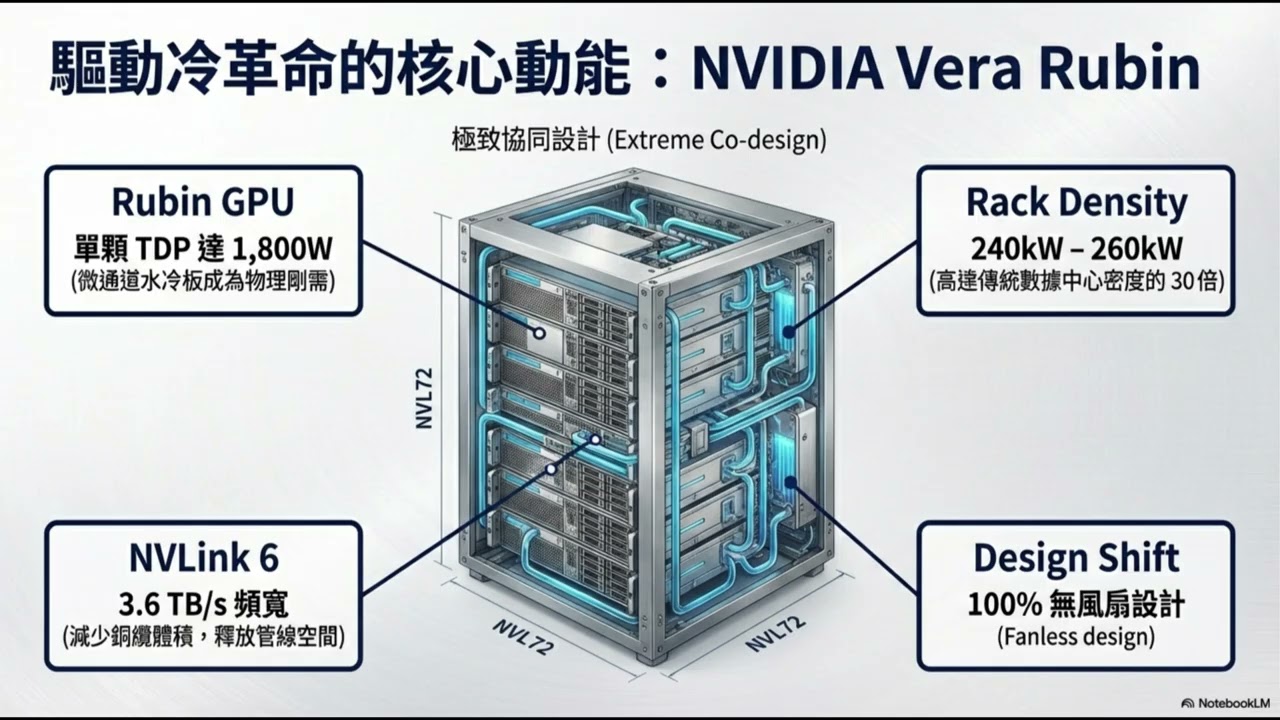
[重點整理] NVIDIA 推出的 Vera Rubin 平台標誌著 AI 基礎設施從單純算力競賽轉向「效率治理」的範式轉換。輝達透過收購 Groq 技術資產,將「Mellanox 劇本」應用於推論階段,其核心策略在於「解構化推論」(Disaggregated Inference),將計算密集的預填充與頻寬受限的解碼階段進行硬體級分離。 1、架構解構:新晶片 Rubin CPX 棄用昂貴的 HBM,改採 GDDR7 記憶體,專門處理計算密集的「預填充」階段(Prefill);而負責「解碼」階段(Decode)的標準 Rubin GPU 則保留 HBM4。這種分離解決了資源錯配問題,大幅提升 GPU 利用率並降低 token 生成成本。 2、記憶體空缺:隨模型上下文窗口邁向百萬 tokens,KV 快取需求呈現線性成長。單一使用者的 KV 快取可能超過 120GB,足以塞滿一張高效能 GPU 的本地記憶體。輝達主動在機身上配置 CXL 4.0 介面,是策略性引導外部供應商填補此巨大記憶體空口。 3、CXL 4.0 技術突破:CXL 4.0 於 2025 年發布,基於 PCIe 7.0 提供 128GT/s 頻寬,首度支援多機架記憶體池化。其實測延遲僅 200-500 奈秒,比 SSD 快數百倍,能支撐 KV 快取在不同運算節點間自由流動。 4、軟硬體協作:輝達透過 Dynamo 編排框架與 BlueField-4 DPU,將共享記憶體定義為「G3.5 層」溫儲存。這使 AI 工廠能像擁有無限記憶體般運作,每 GPU 吞吐量最高可提升 30 倍,實現「記憶體即服務」(MaaS)模式。 5、產業影響:此舉將利多三星等 GDDR7 供應商,並促使雲端服務商轉向動態劃撥資源的 MaaS 商業模式。競爭邊界已從 TFLOPS 比較轉移至機架級記憶體池化能力與編排效率。輝達採「核心閉環、邊緣開門」策略,鞏固了運算王座的同時,也藉開放標準吸引生態夥伴共同承擔記憶體成本壓力。 [ 沒有買賣建議 僅做資訊分享 且AI資訊不一定正確 需自行查證]
Comments


![Почему взрываются батарейки и аккумуляторы? [Veritasium]](https://imager.clipsaver.ru/a3-3R9zwyGY/max.jpg)



![Пожалуй, главное заблуждение об электричестве [Veritasium]](https://imager.clipsaver.ru/6Hv2GLtnf2c/max.jpg)