How to extract text from PDF with Python скачать в хорошем качестве
How to extract text from PDF with Python
4 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: How to extract text from PDF with Python в качестве 4k
У нас вы можете посмотреть бесплатно How to extract text from PDF with Python или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон How to extract text from PDF with Python в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
How to extract text from PDF with Python
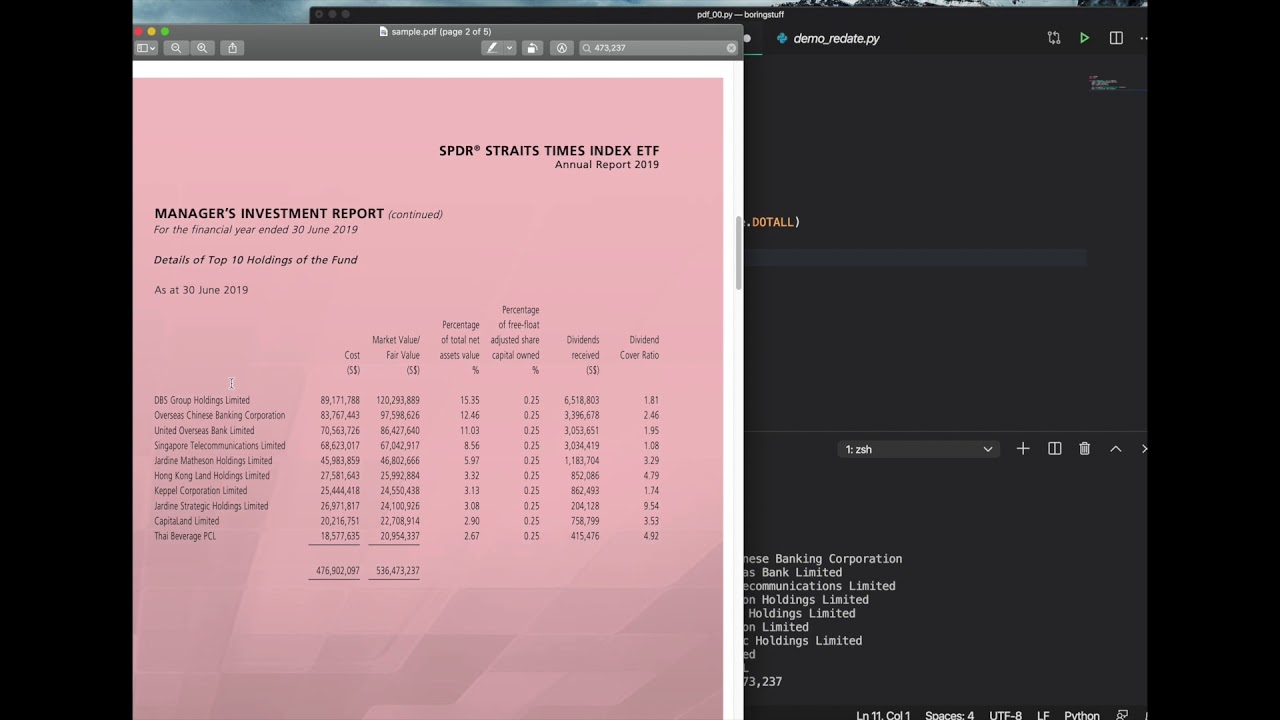
Extracting text from a PDF file is quite a simple task to do and can be a time-saver when working with PDF files. It doesn't take that much time to write the code and it is reusable, what more can a person ask for! The library used in this case is PyPDF2. Link to documentation: https://pythonhosted.org/PyPDF2/ Links for donation: Paypal: https://www.paypal.com/donate?hosted_... https://www.buymeacoffee.com/Kostadin
Comments
![[15] Use Python to extract invoice lines from a semistructured PDF AP Report](https://imager.clipsaver.ru/eTz3VZmNPSE/max.jpg)